数据清洗主要是删除原始数据集中的无关数据、重复数据,平滑噪声数据,筛选掉与挖掘主题无关的数据,处理缺失值、异常值等。
1.缺失值
处理缺失值的方法可分为3类:删除记录、数据插补和不处理。
*缺失值的处理方法
均值/中位数/众数插补:
根据属性值的类型,用该属性取值的平均数/中位数/众数进行插补
使用固定值:
将缺失的属性值用一个常量替换。如广州一个工厂普通外来务工人员的“基本工资”属性的空缺值可以用2015年广州市普通外来务工人员工资标准1895元/月,该方法就是使用固定值
最近临插补:
在记录中找到与缺失样本最接近的样本的该属性值插补
回归方法:
对带有缺失值的变量,根据已有数据和与其有关的其他变量(因变量)的数据建立拟合模型来预测缺失的属性值
插值法:
插值法是利用已知点建立合适的插值函数f(x),未知值由对应点xi,求出的函数值f(xi)近似代替
*如果通过简单的删除小部分记录达到既定的目标,那么删除含有缺失值的记录的方法是最有效的。然而,这种方法却有很大的局限性。它是以减少历史数据来换取数据的完备,会造成资源的大量浪费,将丢弃了大量隐藏在这些记录中的信息。尤其在数据集本来就包含很少记录的情况下,删除少量记录可能会严重影响到分析结果的客观性和正确性。
*一些模型可以将缺失值视作一种特殊的取值,允许直接在含有缺失值的数据上进行建模。
2.异常值
在数据预处理时,异常值是否剔除,需视具体情况而定,因为有些异常值可能蕴含着有用的信息。
*异常值处理方法
删除含有异常值的记录:直接将含有异常值的记录删除
视为缺失值:将异常值视为缺失值,利用缺失值处理的方法进行处理
平均值修正:可用前后两个观测值的平均值修正该异常值
不处理:直接在具有异常值的数据集上进行挖掘建模
*将含有异常值的记录直接删除的方法简单易行,但缺点也很明显,在观测值很少的情况下,这种删除会造成样本量不足,可能会改变变量的原有分布,从而造成分析结果的不准确。视为缺失值处理的好处是可以利用现有变量的信息,对异常值(缺失值)进行填补。
*在很多情况下,要先分析异常值出现的可能原因,再判断异常值是否应该舍弃,如果是正确的数据,可以直接在具有异常值的数据集上进行挖掘建模。
3.数据集成
数据挖掘需要的数据往往分布在不同的数据源中,数据集成就是将多个数据源合并存放在一个一致的数据存储(如数据仓库)中的过程。
在数据集成时,来自多个数据源的现实世界实体的表达形式是不一样的,有可能不匹配,要考虑实体识别问题和属性冗余问题,从而将源数据在最低层上加以转换、提炼和集成。
4.实体识别
实体识别是指从不同数据源识别出现实世界的实体,它的任务是统一不同源数据的矛盾之处
(1 )同名异义
数据源A中的属性ID和数据源B中的属性ID分别描述的是菜品编号和订单编号,即描述的是不同的实体。
(2)异名同义
数据源A中的sales_dt和数据源B中的sales_date都是描述销售日期的,即A. sales_dt= B. sales_date
(3 )单位不统一
描述同一个实体分别用的是国际单位和中国传统的计量单位。
检测和解决这些冲突就是实体识别的任务。
5.冗余属性识别
数据集成往往导致数据冗余,例如,
- 同一属性多次出现;
- 同一属性命名不一致导致重复。
*仔细整合不同源数据能减少甚至避免数据冗余与不一致,从而提高数据挖掘的速度和质量。对于冗余属性要先分析,检测到后再将其删除。
*有些冗余属性可以用相关分析检测。给定两个数值型的属性A和B,根据其属性值,用相关系数度量一个属性在多大程度上蕴含另一个属性。
6.数据变换
数据变换主要是对数据进行规范化处理,将数据转换成“适当的”形式,以适用于挖掘任务及算法的需要。
(1)简单函数变换
简单函数变换是对原始数据进行某些数学函数变换,常用的变换包括平方、开方、取对数、差分运算等
简单的函数变换常用来将不具有正态分布的数据变换成具有正态分布的数据。在时间序列分析中,有时简单的对数变换或者差分运算就可以将非平稳序列转换成平稳序列。在数据挖掘中,简单的函数变换可能更有必要,比如个人年收人的取值范围为10000元到10亿元,这是一个很大的区间,使用对数变换对其进行压缩是常用的一种变换处理方法。
(2)规范化
*最小-最大规范化也称为离差标准化,是对原始数据的线性变换,将数值值映射到[0,1][0,1]之间.
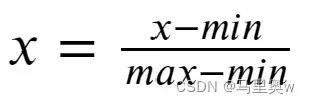
max为样本数据的最大值,min为样本数据的最小值。max-min为极差。离差标准化保留了原来数据中存在的关系,是消除量纲和数据取值范围影响的最简单方法。这种处理方法的缺点是若数值集中且某个数值很大,则规范化后各值会接近于0,并且将会相差不大。若将来遇到超过目前属性[min,max]取值范围的时候,会引起系统出错,需要重新确定min和max。
*零-均值规范化也称标准差标准化,经过处理的数据的均值为0,标准差为1。
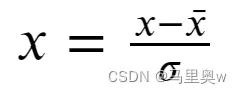
其中x¯为原始数据的均值,σ为原始数据的标准差,是当前用得最多的数据标准化方法。
小数定标规范化
通过移动属性值的小数位数,将属性值映射到[-1,1]之间,移动的小数位数取决于属性值绝对值的最大值。
data/10* np.ceil(np.log10(data.abs().max()))
(3)连续属性离散化
*离散化的过程:
连续属性的离散化就是在数据的取值范围内设定若干个离散的划分点,将取值范围划分为一些离散化的区间,最后用不同的符号或整数值代表落在每个子区间中的数据值。所以,离散化涉及两个子任务:确定分类数以及如何将连续属性值映射到这些分类值。
*常用的离散化方法:
常用的离散化方法有等宽法、等频法和(一维)聚类。
*等宽法
将属性的值域分成具有相同宽度的区间,区间的个数由数据本身的特点决定,或者由用户指定,类似于制作频率分布表。
*等频法
将相同数量的记录放进每个区间。
这两种方法简单,易于操作,但都需要人为地规定划分区间的个数。同时,等宽法的缺点在于它对离群点比较敏感,倾向于不均匀地把属性值分布到各个区间。有些区间包含许多数据,而另外一些区间的数据极少,这样会严重损坏建立的决策模型。等频法虽然避免了上述问题的产生,却可能将相同的数据值分到不同的区间以满足每个区间中固定的数据个数。
*基于聚类分析的方法
一维聚类的方法包括两个步骤,首先将连续属性的值用聚类算法(如K-Means算法)进行聚类,然后再将聚类得到的簇进行处理,合并到一个簇的连续属性值并做同一标记。聚类分析的离散化方法也需要用户指定簇的个数,从而决定产生的区间数。
(4)属性构造
利用已有的属性构造出新的属性,并加入到现有的属性集合中。
文章出处登录后可见!