文地址:
《Neural Architecture Search: A Survey》
问题
深度学习卷积神经网络最近得到了很好的发展,由于深度学习可以捕捉到有用的特征,其在图像处理领域取得了很好的效果;然而, 这种效果很大程度上得益于新的神经网络结构的出现,如ResNet、Inception、DenseNet等等。但设计出高性能的神经网络需要大量的专业知识与反复试验,成本极高,限制了神经网络在很多问题上的应用;尽管各种神经网络模型层出不穷,但往往模型性能越高,对超参数的要求也越来越严格,稍有不同就无法复现论文的结果。而网络结构作为一种特殊的超参数,在深度学习整个环节中扮演着举足轻重的角色。
以往都是手工设计网络结构,有没有办法能够设计一个可以自动搜索网络结构的方法呢?
Goolge提出了NAS,神经结构搜索(Neural Architecture Search,NAS)是一种自动设计神经网络的技术,可以通过算法根据样本集自动设计出高性能的网络结构,在某些任务上甚至可以媲美人类专家的水准,甚至发现某些人类之前未曾提出的网络结构,这可以有效的降低神经网络的使用和实现成本。
NAS的原理
给定一个称为搜索空间的候选神经网络结构集合,用某种搜索策略从中搜索出最优网络结构。神经网络结构的优劣即性能用某些指标如精度、速度来度量,称为性能评估。
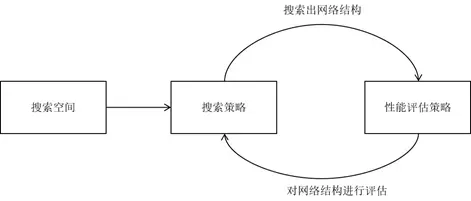
在搜索过程的每次迭代中,从搜索空间产生“样本”即得到一个神经网络结构,称为“子网络”。在训练样本集上训练子网络,然后在验证集上评估其性能。逐步优化网络结构,直至找到最优的子网络。
搜索空间,搜索策略,性能评估策略是NAS算法的核心要素:
搜索空间定义了可以搜索的神经网络结构的集合,即解的空间;
搜索策略定义了如何在搜索空间中寻找最优网络结构;
性能评估策略定义了如何评估搜索出的网络结构的性能;
对这些要素的不同实现得到了各种不同的NAS算法。
搜索空间
搜索空间定义了NAS算法可以搜索的神经网络的类型,同时也定义了如何描述神经网络结构。
确定网络的拓扑结构:网络有多少个层,这些层的连接关系,确定每一层的输入数与输出数;
确定每个层的类型:除了第一个层必须为输入层,最后一个层必须为输出层之外,中间的层的类型是可选的,它们代表了各种不同的运算即层的类型。典型有全连接,卷积,反卷积,空洞卷积,池化,激活函数等。但这些层的组合使用一般要符合某些规则;
确定每个层内部的超参数:卷积层的超参数有卷积核的数量,卷积核的通道数,高度,宽度,水平方向的步长,垂直方向的步长等。全连接层的超参数有神经元的数量。激活函数层的超参数有激活函数的类型,函数的参数等。
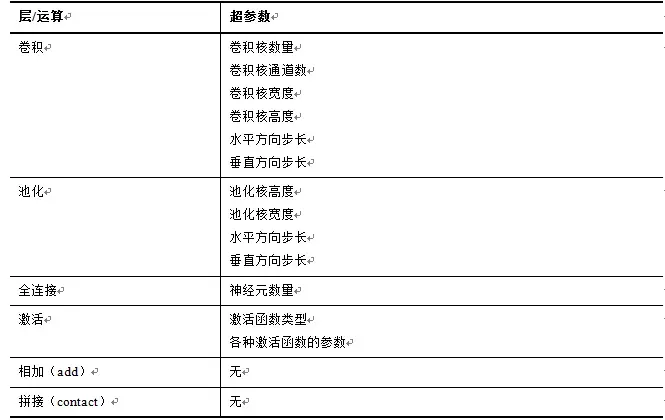
为了提高搜索效率,有时候会对搜索空间进行限定简化:
在某些NAS实现中会把网络切分成基本单元(cell,或block),通过这些单元的堆叠形成更复杂的网络,基本单元由多个神经网络的层组成,它们在整个网络中重复出现多次,但具有不同的权重参数,另外一种做法是限定神经网络的整体拓扑结构,借鉴于人类设计神经网络的经验。
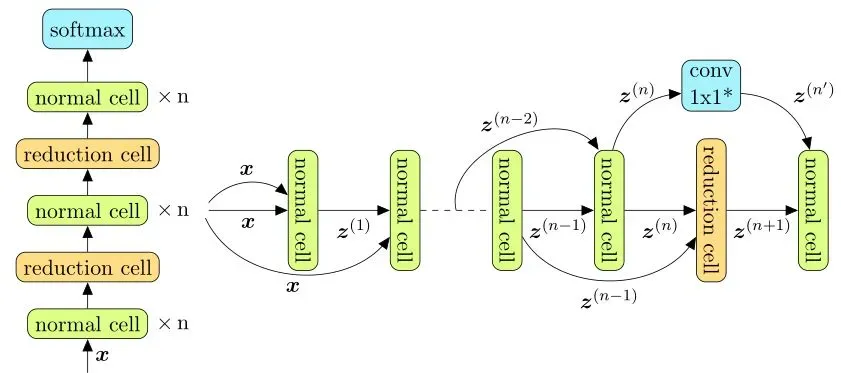
基于cell的NAS搜索只搜索一些小的结构,通过堆叠、拼接的方法组合成完整的大网络,这样既减少了搜索代价,也提高了结构的可迁移性。如下图所示:
Cell分两种:Normal和Reduction。当输入特征和输出特征的分辨率是一致时,采用Normal Cell,当输入特征的分辨率是输入特征的一半时,采用Reduction Cell。Reduction Cell的设计方法Normal Cell基本一样,只是在输入特征上添加了一个stride=2的卷积操作,降低分辨率。在整体网络架构中,Normal Cell和Reduction Cell的设计原则是每N个Normal Cell中插入一个Reduction Cell。
搜索策略
搜索策略定义了如何找到最优的网络结构,即如何在搜索空间中进行选择,通常是一个迭代优化过程,本质上是超参数优化问题。
目前已知的搜索方法有随机搜索,贝叶斯优化,遗传算法,强化学习,基于梯度的算法。
基于强化学习的NAS算法
强化学习被广泛应用于连续决策建模中,该方法通过智能体(agent)与环境交互,每次agent都会执行一些动作(action),并从环境中获得回馈,强化学习的目标就是让回馈最大化。
这里的智能体(agent)是设计神经网络结构的算法,用于输出神经网络结构描述,强化学习算法使得生成的神经网络的性能最优化;为了用强化学习求解,可以将神经网络的设计看做一个动作序列(action),每次执行动作确定网络的一部分结构如层。神经网络在验证集上的性能值是强化学习中的奖励值。
由于神经网络的结构参数长度不固定,因此需要用一个可变长度的串来描述网络结构,算法需要输出这种不定长的串。循环神经网络(RNN)可以输出不固定长度的数据,因此可以用RNN来生成网络结构的描述,NAS使用RNN作为控制器来采样子网络,对子网络训练、评估后使用策略梯度方法更新RNN参数。
该算法用一个称为控制器的循环神经网络(RNN)生成描述子网络结构的串,从而确定子网络的结构。然后在训练集上训练子网络,在验证集上计算其精度值。以精度值作为反馈信号,采用策略梯度算法更新控制器网络的参数。在迭代时,控制器会以给予那些有更高精度值的神经网络以更高的概率值,从而确保策略函数能够输出最优网络结构。
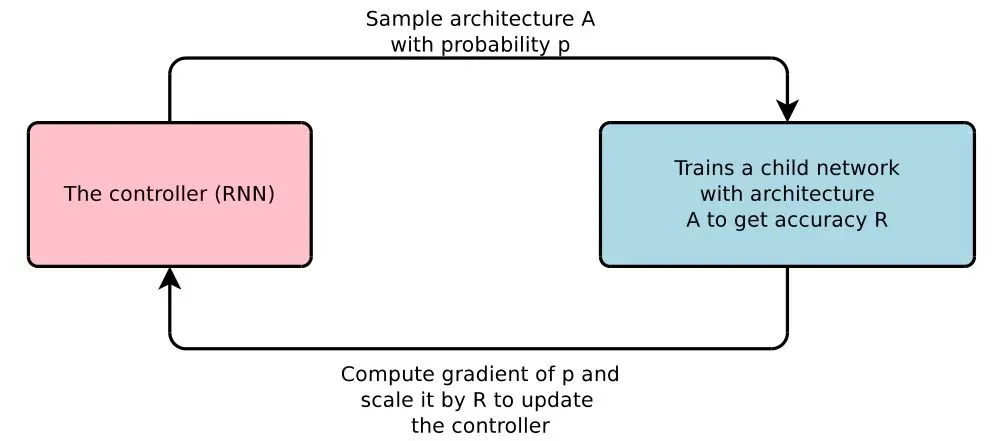
算法的输出限定为分层的网络结构,第n个网络层以第n-1个网络层为基础。网络结构生成可抽象为序列生成问题,按层逐次预测网络结构。在RNN中,每5个输出值定义一个神经网络层。上一时刻的输出是本时刻的输入,确保RNN基于前面n-1层所有的结构信息来预测第n层的结构。RNN的输出层是softmax回归,根据它确定结构参数。对于卷积核高度,可以限定输出值为[1,3,5,7]四个数,RNN的softmax输出是取这4个数的概率值。
控制器每一时刻的输出包括:卷积核的数量,卷积核的高度,卷积核的宽度,卷积操作在水平方向的步长,卷积操作在垂直方向的步长。
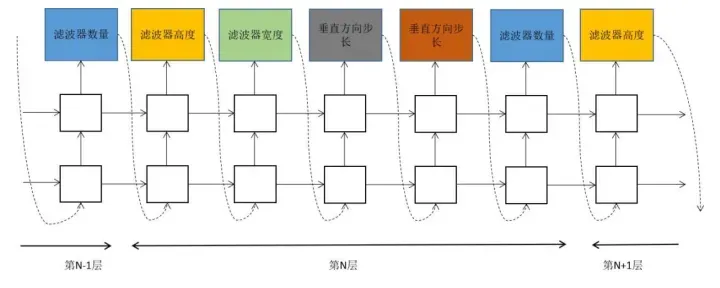
具体实现时考虑到典型的网络结构:对于卷积核的数量,取值范围为[24,36,48,64],卷积核的高度取值范围为[1,3,5,7],卷积核宽度的取值范围与高度相同。卷积步长可以固定为1,也可以按照 [1,2,3]取值;实现时同时限定了神经网络的层数,达到一定的层之后,停止输出;
控制器生成该描述串之后,接下来在训练集上训练该子网络,这里采用了REINFORCE算法,实现原理:

用强化学习解决NAS问题,面临着计算量大的问题。一种解决方案是对搜索空间进行简化,限定网络结构为某些类型。回顾卷积网络的发展历史,各种典型卷积神经网络一般都具有某些重复、规整的结构,如ResNet中的跨层连接块,GoogLeNet中的Inception块等。如果能预测出这种基本块结构,然后将其堆叠形成网络,既可以降低搜索成本,又能使得网络随着输入数据的尺寸动态扩展,对于大尺寸的输入图像,只需要增加堆叠的块数即可。
基于策略梯度的优化效率很低,而且对子网络的采样优化会带来很大的变异性(有时方差很大),RNN只能生成网络描述,因而无法通过模型的准确率直接对其进行优化。同样的策略也适用于各种其他的约束,如网络时延等各项衡量网络好坏的指标。
基于遗传算法的NAS算法
使用遗传算法求解NAS的思路是将子网络结构编码成二进制串,运行遗传算法得到适应度函数值(神经网络在验证集上的精度值)最大的网络结构,即为最优解。
首先随机初始化若干个子网络作为初始解。遗传算法在每次迭代时首先训练所有子网络,然后计算适应度值。接下来随机选择一些子网络进行交叉,变异生成下一代子网络,然后训练这些子网络,重复这一过程,最后找到最优子网络。
如何将神经网络的结构编码成固定长度的二进制串。
将网络划分为多个级(stage),对每一级的拓扑结构进行编码。级以池化层为界进行划分,是多个卷积层构成的单元,每一组卷积核称为一个节点(node)。数据经过每一级时,高度,宽度和深度不变。每一级内的卷积核有相同的通道数。每一次卷积之后,执行批量归一化和ReLU激活函数。对全连接层不进行编码。对于每一组卷积核,首先对输入数据进行逐元素相加,然后执行卷积。
基于梯度下降的NAS算法
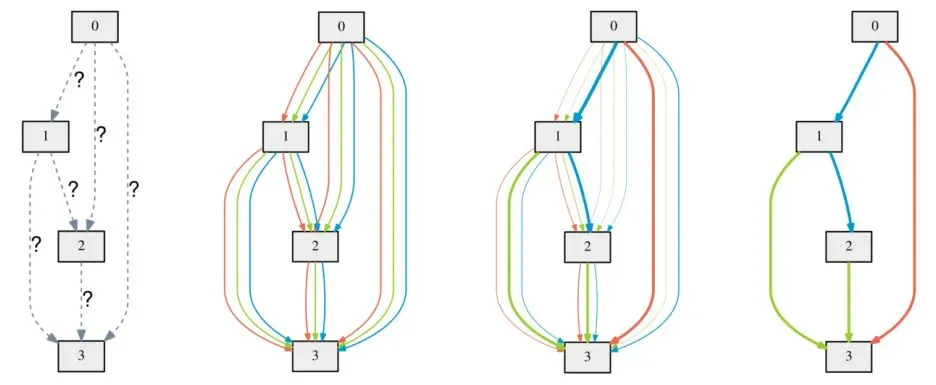
前面的方法网络空间是离散的,它们都将NAS处理为黑盒优化问题,因而效率不尽人意。如果能将网络空间表示为连续分布,就能通过基于梯度的方法进行优化。可微分结构搜索方法。该方法与ENAS相同,将网络空间表示为一个有向无环图,其关键是将节点连接和激活函数通过一种巧妙的表示组合成了一个矩阵,其中每个元素代表了连接和激活函数的权重,在搜索时使用了Softmax函数,这样就将搜索空间变成了连续空间,目标函数成为了可微函数。在搜索时,DARTS会遍历全部节点,使用节点上全部连接的加权进行计算,同时优化结构权重和网络权重。搜索结束后,选择权重最大的连接和激活函数,形成最终的网络。
性能评估策略
搜索策略的目标是找到一个神经网络结构,最大化某种性能度量指标,如在之前未见的数据集上的精度。为了指导搜索过程,NAS算法需要估计一个给定神经网络结构的性能,这称为性能评估策略。
对于搜索策略搜索出的神经网络结构,首先在一个训练集上训练,然后在验证集上测试精度值。训练和验证过程非常耗时,因此有必要采取措施以降低性能评估的成本。降低训练成本的简单做法有减少训练时间(迭代次数),在训练样本的一个子集上进行训练,在低分辨率的图像上进行训练,或者在训练时减少某些层的卷积核的数量。这些做法在降低计算成本的同时可能会导致性能评估值的偏差。虽然搜索策略只需对各种网络结构的优劣进行排序,无需知道它们准确的性能指标,但这种近似可能还是会导致排序结果的偏差。
更复杂的做法是对神经网络的性能进行预测(外推),即通过训练时前面若干次迭代时的性能表现推断其最终的性能,或者用搜索出的单元(块)的特性预测整个网络的性能。权值共享也是一种方案。以之前训练过的子网络的权重作为当前要评估的子网络的初始权重可以有效的提高训练速度,加速收敛,避免从头开始训练。ENAS和DARTS则直接让各个子网络共享同一套权重参数。
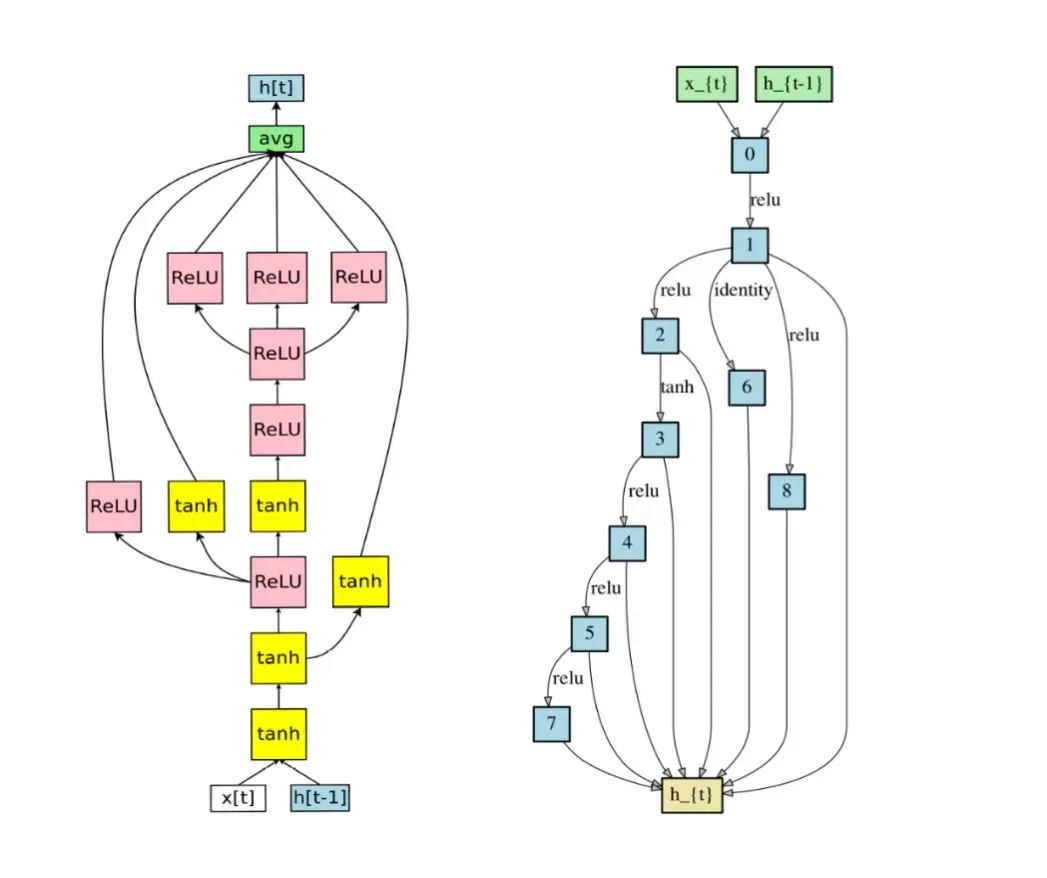
基于One-Shot的结构搜索是目前的主流方法,该方法将搜索空间定义为超级网络(supernet),全部网络结构都被包含其中。这个方法最显著的特征就是在一个过参数化的大网络中进行搜索,交替地训练网络权重和模型权重,最终只保留其中一个子结构,上面提到的DARTS和ENAS就是这一类方法的代表。该类方法的本质其实是对网络结构进行排序,然而不同的网络共享同一权重这一做法虽然大大提高搜索效率,却也带来了严重的偏置。显然,不同的神经网络不可能拥有相同的网络参数,在共享权重时,网络输出必定受到特定的激活函数和连接支配。ENAS和DARTS的搜索结果也反应了这一事实,如图6所示,其中ENAS搜索出来的激活函数全是ReLU和tanh,而DARTS搜索出来激活函数的几乎全是ReLU。此外,DARTS等方法在搜索时计算了全部的连接和激活函数,显存占用量很大,这也是它只能搜索较小的细胞结构的原因。
ENAS(左)和DARTS(右)在PTB上搜索的RNN模型:
NAS 未来展望
目前NAS搜索的网络都是比较简单的节点和激活函数的排列组合,尽管在一些任务上性能表现突出,但仍离不开繁琐的超参数选择。个人认为未来NAS技术的发展趋势有这几点:
- 网络设计自动化:真正做到把数据丢给机器,直接获得最优的模型,而不是依赖众多超参数。
- 多目标搜索:根据不同任务,朝着多目标的方向继续前进。
- 规模搜索:直接在大规模数据集上进行搜索,而不仅仅是在几个小型数据集上搜索、强化手工设计的网络。
- 拓展应用领域:在图像处理、自然语言处理等领域得到应用。
参考
如何看待神经架构搜索(Neural Architecture Search)的发展?
仅为学习记录,侵删!
文章出处登录后可见!