
0.摘要
- 1.当前像素级分割的问题
- 场景适应能力差
- 速度慢
- 2.人类识别车道线的特点
- 利用了上下文信息(可以理解为人类的联想能力)和全局信息
- 3.本文车道线检测算法
- 基于人类识别车道线的特点–提出结构损失函数(structural loss)
- 速度快,可以应对有挑战性的场景
- 4.具体实现
- 基于行的选择(row-based selecting) –> 速度变快,场景适应能力强
- structural loss –> 场景适应能力增强
- 5.实验及结果
- 使用图森和CULane数据集,速度和精度都获得了提升
- 轻量级版本的模型检测速度可以达到300+FPS,比之前最先进的算法(SAD)快4倍

1.研究背景(Introduction)
-
下面这一段主要讲了车道线检测的历史,主要分为传统图像处理的方法和深度学习分割的方法。作者给出了深度学习分割方法的优势————表示能力强(应该是说可以表示曲线)和具有学习能力。

-
下面这一段主要证明了提高车道线检测速度的重要性,可以略过

-
下面这一段主要提了当前车道线检测
no-visual-clue(根据后文这里可以理解为当车道线被遮挡时没有推测出车道线位置的能力)的问题,并提到了SCNN算法的解决方法,以及该算法的不足。

-
下面这段主要说了当前的分割使用二值图的表示方法无法使用车道线的先验信息(主要是指车道线的形状信息,为了引出后文的structural loss)

-
基于以上问题,给出了本文的解决方案
-
structural loss可以使用先验信息
-
在图像上预先划分行(rows),将车道线检测问题转化为在每个行上的位置选择问题–>降低计算成本,提高速度


-
对于
no-visual-clue问题,本文由于使用了selecting in rows based on global features的方法,所以来自图像中其他位置的线索和信息可以被使用上。(目前可能还是不太好理解,可以继续往后看,主要是通过structural loss) -
另外本文还改变了车道线的表示方法,由二值图变成了用选出的网格单元位置的表示方法


-
-
本文的主要工作概括
- 1.和分割的方法相比,本文的方法是通过位置选择来检测车道线,可以理解为从像素级的分类变成了grid cells(类似与anchor的)的分类,因此检测速度快了很多。这个操作也导致感受野变大了,可以使用全局特征,
no-visual-clue也被解决了。 - 2.另外还提出了一个结构损失函数,利用了车道线的先验信息。后文有解释,为方便理解,提前说一下,是基于车道线连续性假设,当前row的车道线位置一定是和前一个row的车道线位置距离接近的。
- 3.和摘要最后的内容差不多,主要是说实验结果。轻量级版本的模型检测速度可以达到300+FPS,比之前最先进的算法(SAD)快4倍

- 1.和分割的方法相比,本文的方法是通过位置选择来检测车道线,可以理解为从像素级的分类变成了grid cells(类似与anchor的)的分类,因此检测速度快了很多。这个操作也导致感受野变大了,可以使用全局特征,
2.研究现状(Related Work)
- 和本文算法相关的内容不多,我就不写了。原文放上,感兴趣可以看看。


3.研究方法(Method)
- 这节是重点,主要讲结构损失函数,占了论文大约1/3的篇幅。
3.1 车道线检测新表达形式(New formulation for lane detection)
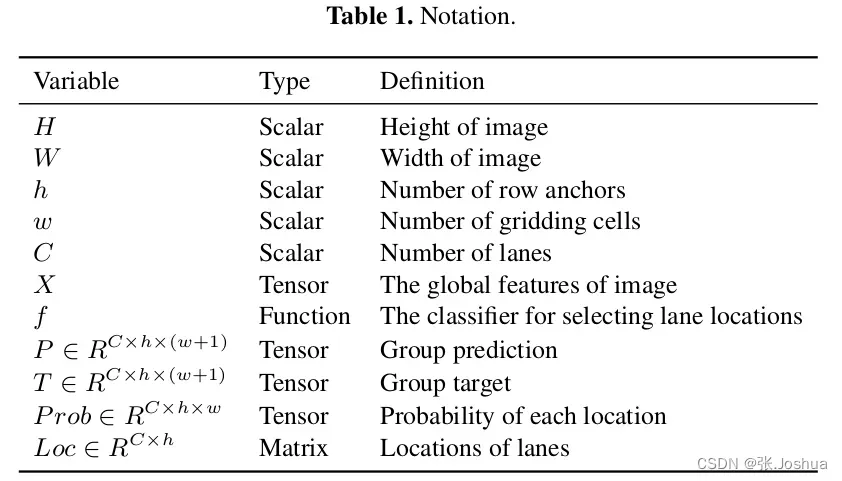
- 本小节主要是新表达形式的推到方式,解决检测速度和无视觉线索的问题。表1为符号说明

3.1.1新表达形式的定义
-
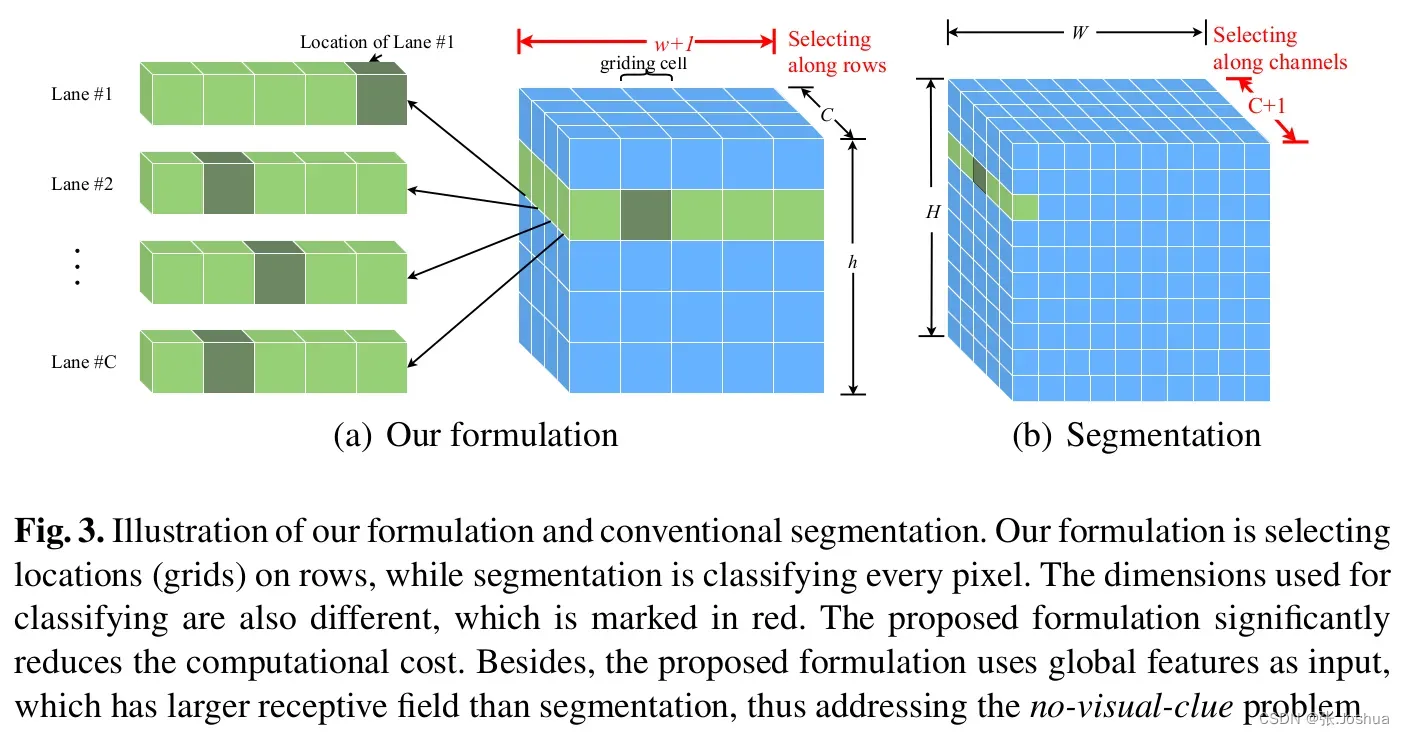
这一段主要解释了基于行的车道线位置选择方法。原文解释在下面红线处标注,就是将整个图中可能有车道线的区域划分为很多行,每个行中又划分有很多小单元,本文的车道线检测新表达形式就是从每个行中找出那一个小单元是车道线。

-
图3(a)中,C是车道线的数量,h是划分的行的数量,w是每个行划分的小单元的数量,w+1是表示改行车道线可能确实,也就是每个小单元中都没有车道线,这种情况需要多一维来表示。X是图像的全局特征,f是分类器,P是预测结果,是一个概率值,表示第j行的第i个小单元有车道线的概率。当前车道线的位置可以通过概率分布得到。
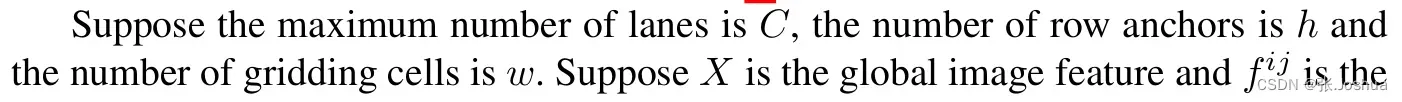

-
由标注内容得到,也就是ground truth。

-
是类别损失,
是交叉熵损失。

3.1.2新表达形式如何实现快速的检测速度的?
- 如小标题所示,本节主要解释了下新表达形式如何实现快速的检测速度的。我觉得可以简单理解为使用类似anchor的方法对原始图像进行了降维。(这是我的通俗的理解,可能不严谨)原文的解释应该更加严谨。可以结合Fig3来理解。

3.1.3新表达形式如何处理no-visual-clue问题的?
- 第一段:当目标位置(可能由于遮挡)没有车道线信息的时候,使用其他位置的信息就特别重要。
- 第二段:本文的新表达形式获得的信息比分割方法要大很多(相当于感受野变大),因此可以使用来自其他位置的上下文信息解决
no-visual-clue的问题。structural loss可以学习车道线的形状和方向信息。- 概括一下,作者认为可以从感受野的角度和网络学习的角度来分析为什么能解决
no-visual-clue问题,从这两个角度分析的理由分别是感受野变大,获得的特征也多了;structural loss可以学习车道线的形状和方向信息
- 概括一下,作者认为可以从感受野的角度和网络学习的角度来分析为什么能解决
- 第三段:最后作者对比了本文
row-based和分割方法。row-based具有可以建立不同行之间关系的优势。而分割的方法,是利用在像素级(low-level)提取车道信息,然后表示车道线(high-level)细长型结构。

3.2 车道线结构损失函数(Lane structural loss)
-
这部分可以说是本文的核心,给出了结构损失函数的推导过程。结构损失函数主要增强网络学习车道线检测点之间的位置关系。可以先看一下公式(8),结构损失由相似度损失和形状损失组成。接下来会分别讲这两个损失的推导。
-
下面这段是相似度损失(
)的推导。首先作者给出了一个合理假设,车道线是连续的;因此,相邻的行上检测到的lane point(被认定有车道线的小单元)的位置也应该是接近的。下面的公式是相似度损失
计算方法,
表示相邻两行的所有小单元的概率值的一范数,当
和
所表示的概率约接近时,

-
接下来推导形状损失(
-
为什么要用二阶导,一阶导只能表示直线或曲线的斜率,而二阶导可以表示直线或曲线的斜率的变化率。限制了检测出的车道线出现特别大的曲率的可能(也就是限制检测出的曲线出现特别大的弯)。(个人理解)

-
下面这段是查找车道点的。求一行中所有小单元预测得到的概率最大的小单元的索引,有点绕,总之就是求出
最大的位置,该位置的索引用
表示。

-
由于
函数不可微,无法求二阶导。然后作者使用预测的期望值作为位置约束,使用
函数得到不同位置的预测概率值
。注意
是不同的。
-
然后就是通过公式6找到
j行中车道点的位置为第i个小单元格。这里求出来的的值最大,接近1,其他位置的
都比较小,约等于0。所以

-
然后就可以使用
。
-
结合形状损失和相似度损失就可以得到结构损失了。在我理解,相似度损失是通过车道线连续性假设约束不同行之间的检测到的车道点位置,形状损失是约束车道线的平滑程度。
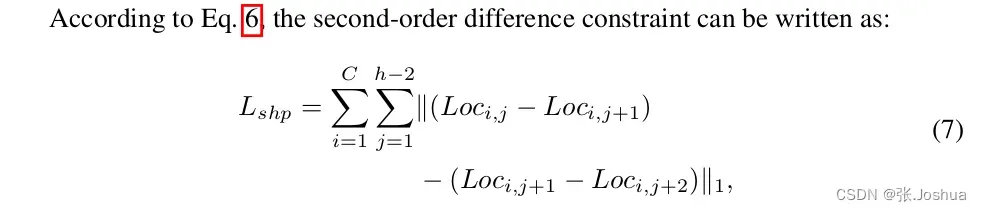
3.3 特征聚合(Feature aggregation)
-
在3.2节中,损失函数的设计主要聚焦于车道线的内在关系。在这一节中,通过使用多尺度特征提出了一个辅助特征聚类方法。使用交叉熵损失作为辅助分割损失函数。得到整体的损失函数
。Fig4是网络的总体架构。

-
值得关注的是,这个辅助分割损失只在训练阶段被使用,在测试阶段会被移除。因此,该结构不会增加推理时间。

4实验(Experiments)
- 这节主要是通过实验验证算法的效果。主要分三个方面:
- 实验设置
- 消融实验
- 在两个车道线检测数据集上的实验结果

4.1 实验设置(Experimental setting)
-
论文使用的两个数据集如下表所示:
- TuSimple:稳定光照条件的高速场景
- CULane:包括城镇到了的拥堵,曲线车道,炫光,夜间,无车道线,阴影等和高速公路场景

-
评价指标
- 图森数据集使用的是预测正确的车道点与标注的真正车道线的比值所表示的准确率指标。

- CULane中预测正确的标准是把车道线宽度设置为30个像素,求预测值和真值的IoU,IoU大于0.5则认为是预测正确。然后求F1分数,使用F1分数作为最终的评价指标。

- 图森数据集使用的是预测正确的车道点与标注的真正车道线的比值所表示的准确率指标。
-
实施细节
-
主要讲网格划分
-
图森:在竖直方向从160-710以10个像素为步长划分55个行,每行又划分为100个小单元
-
CULane:在竖直方向从260-530以步长10划分为27个行,每行又划分为150个小单元

-
优化过程中,原始图像被resize到288×800分辨率,使用Adam优化方法进行训练,学习率初始值为0.0004,采用余弦衰减策略,损失函数的系数
=
=
= 1,batch_size = 32, 在图森数据集上训练了100个epochs,CULane训练了50个epochs。作者也解释了为什么选择这么大的epochs,主要是保留结构信息(structure-preserving)的数据增强需要长时间的学习(没太理解。。)。作者使用的深度学习框架是Pytorch,GPU是1080ti。

-
-
数据增强
- 数据增强的目的:由于车道线的固有结构(长条型的),基于分类的网络很容易过拟合。

- 数据增强的目的:由于车道线的固有结构(长条型的),基于分类的网络很容易过拟合。
4.2 消融实验(Ablation study)
- 这节通过消融实验来验证模型中不同模块的有效性。分别进行了网格划分方式的影响,分类和回归的方式对车道点位置检测的影响,最后对提出的模型做了一个定性和定量的实验。这部分操作比较好理解,我直接写一下作者的结论。
-
作者通过实验得到在图森数据集上最优的网格设置数量是100个

-
在预测车道点位置时,分类的方式好于回归的方式,并且论文里提出的求期望值近似作为位置的方法也不差。

-
定量实验设置相同的训练方法,组合不同的模块看一下检测精度。
-
定性实验验证相似度损失的影响,通过Fig7可以看出应用相似度损失后图像更平滑了。
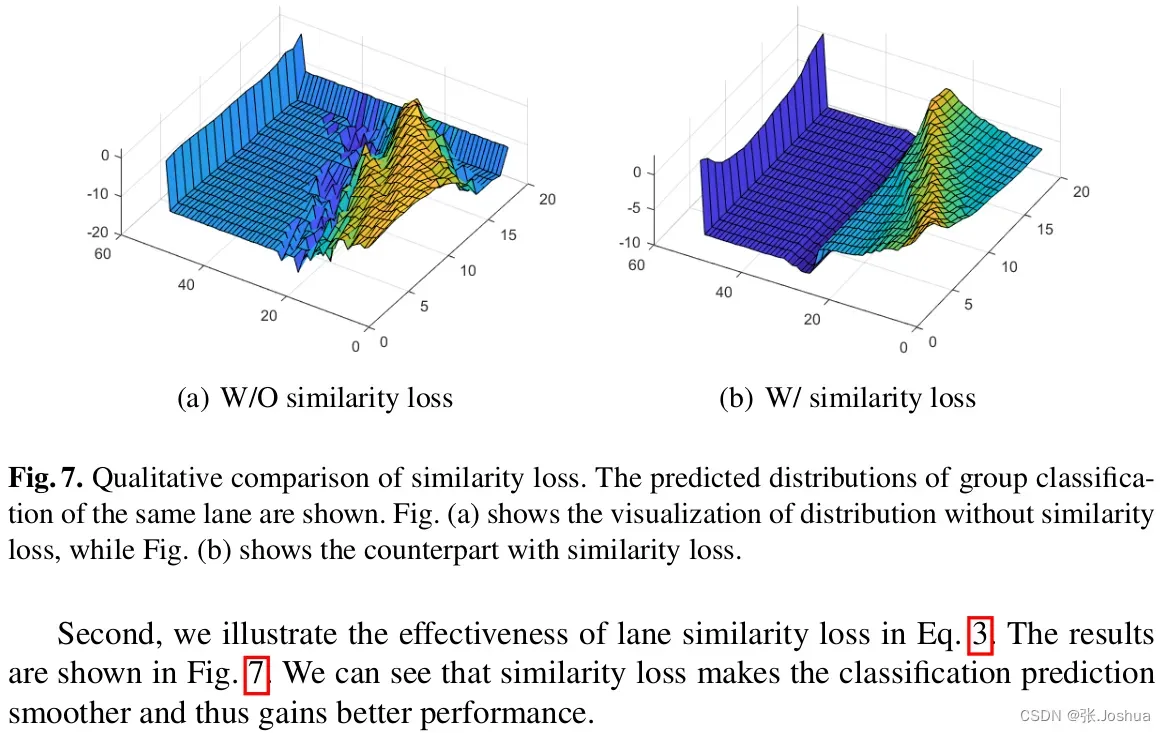
-
4.3实验结果(Results)
-
本节展示了在图森和CULane数据集上的检测结果,使用的主干网络是Resnet-18和Resnet-34。

-
并在图森数据集上与多种算法进行了比较速度和精度。检测时间是记录的循环100次的平均值。

-
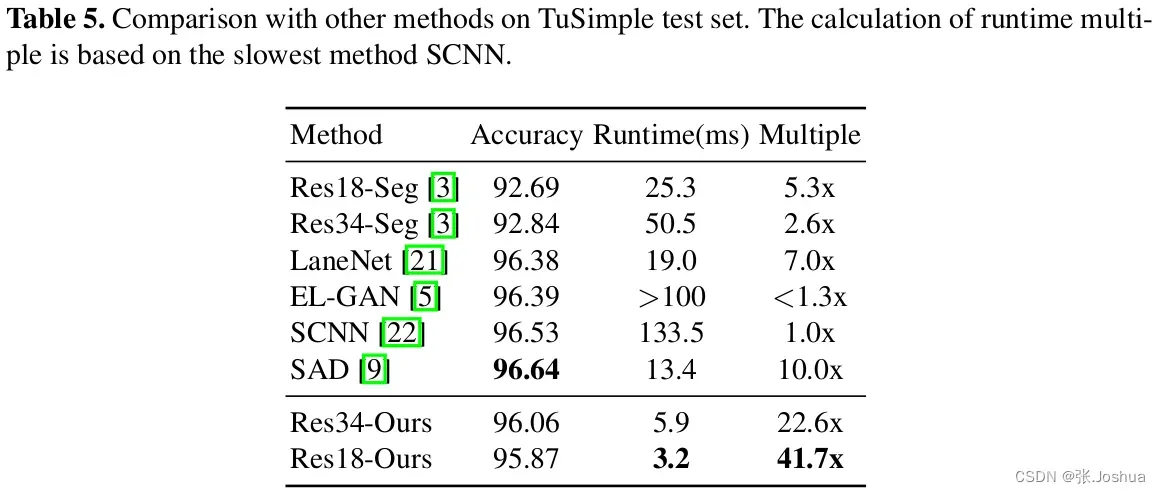
图森数据集上的速度和精度的比较结果在表5

-
从表中数据还可以看出使用相同的主干网络时,论文里所提出的方法比分割的方法速度更快精度更高。(主要是对比Res18-Seg Res18-Ours, Res34-Seg Res34-Ours)。

-
然后在CULane数据集上也进行了类似的实验进行速度和精度的比较。
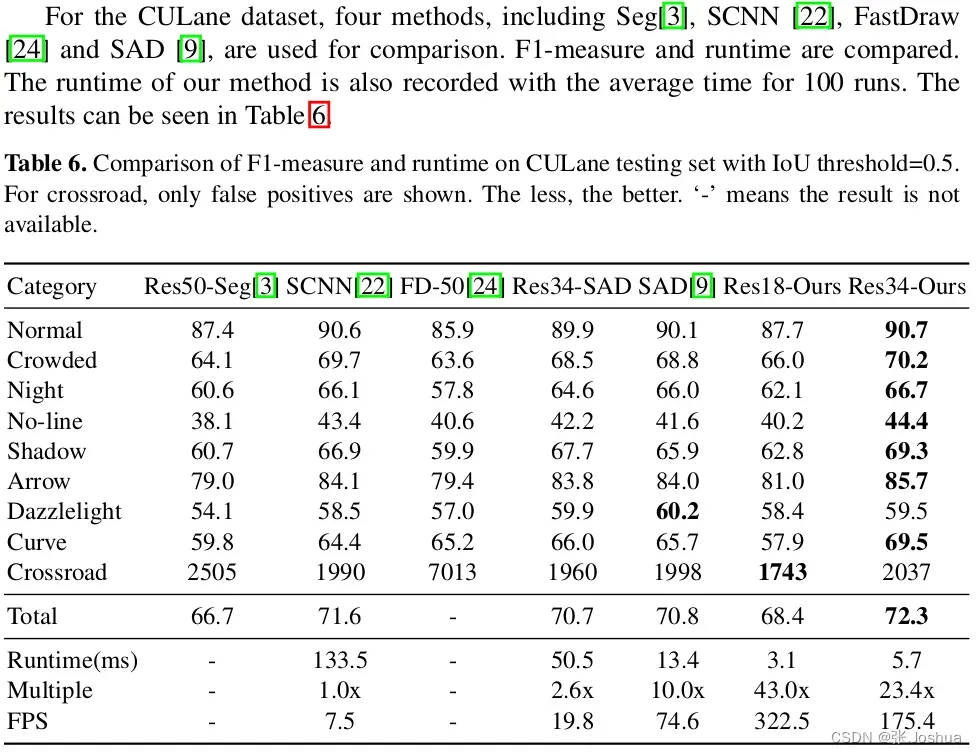

-
下面是检测结果的可视化

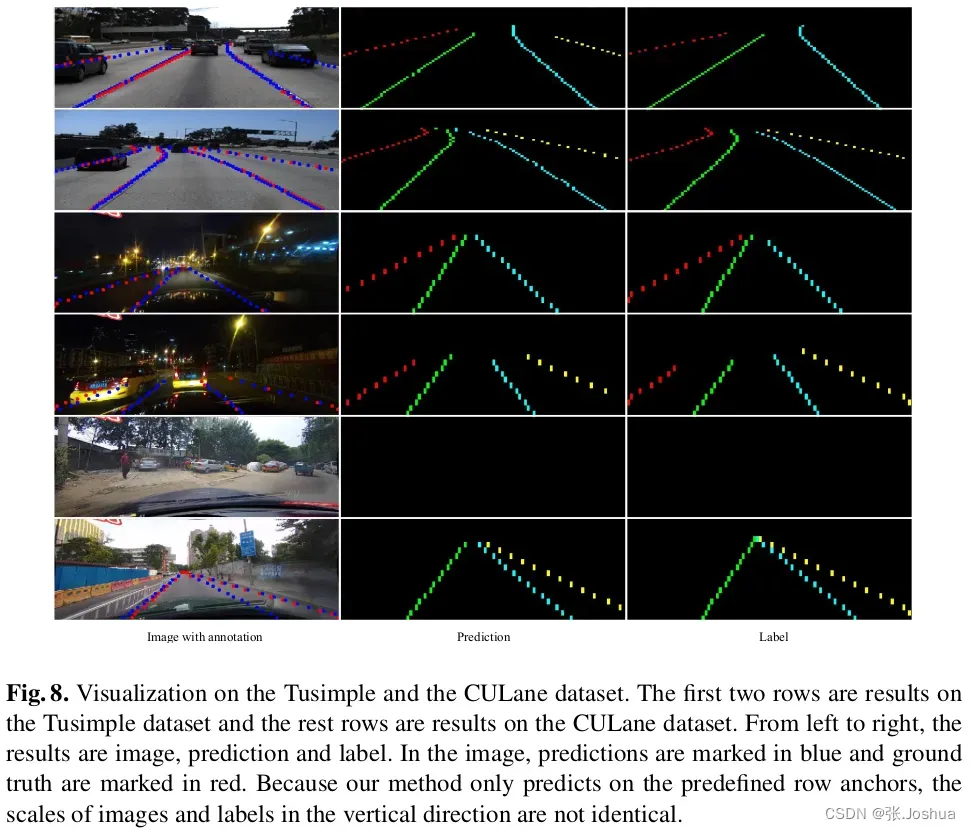
5 结论(Conclusion)
- 这部分看下原文吧

最后
- 终于写完了,这篇论文写的还是非常清晰的,实验也比较全,学习的话重点就是第3节,理解了第三节也就差不多理解了这个算法。
- 个人学习记录,难免有写的错误的地方,还请指正。
文章出处登录后可见!