本内容主要介绍构建词向量的 GloVe 模型。
1 前言
在 GloVe 模型被提出之前,学习词向量的模型主要有两大类:
- 全局矩阵分解方法,例如潜在语义分析(Latent semantic analysis,LSA)。
- 局部上下文窗口方法,例如 Mikolov 等人提出的 skip-gram 模型。
但是,这两类方法都有明显的缺陷。虽然向 LSA 这样的方法有效地利用了统计信息,但他们在单词类比任务上表现相对较差,这表明不是最优的向量空间结构。像 skip-gram 这样的方法可能在类比任务上做得更好,但是他们很少利用语料库的统计数据,因为它们在单独的局部上下文窗口上训练,而不是在全局共现计数上训练。
2 GloVe 模型
GloVe 的全称叫 Global Vectors for Word Representation,它是一个基于全局词频统计(count-based & overall statistics)的词表征(word representation)工具。
GloVe 的实现主要分为三步:(1)构建共现矩阵;(2)词向量和共现矩阵的近似关系;(3)构造损失函数。
2.1 构建共现矩阵
假设我们有一个语料库,包含以下三个句子:
i like deep learning
i like NLP
i enjoy flying
这个语料库涉及 7 个词:i,like,enjoy,deep,learning,NLP,flying。
假设我们采用一个大小为 3(左右长度为 1)的统计窗口,以第一个语句 “i like deep learning” 为例,则会生成以下窗口内容:
| 窗口标号 | 中心词 | 窗口内容 |
|---|---|---|
| 0 | i | i love |
| 1 | love | i love deep |
| 2 | deep | love deep learning |
| 3 | learning | deep learning |
以窗口 1 为例,中心词为 love,上下文词为 i、deep,则更新共现矩阵中的元素:
使用以上方法,将整个语料库遍历一遍,即可得到共现矩阵 :
| i | like | enjoy | deep | learning | NLP | flying | |
|---|---|---|---|---|---|---|---|
| i | 0 | 2 | 1 | 0 | 0 | 0 | 0 |
| like | 2 | 0 | 0 | 1 | 0 | 1 | 0 |
| enjoy | 1 | 0 | 0 | 0 | 0 | 0 | 1 |
| deep | 0 | 1 | 0 | 0 | 1 | 0 | 0 |
| learning | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| NLP | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| flying | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
其中,第一列表示中心词词,第一行表示上下文词。
2.2 词向量和共现矩阵的近似关系
在开始前,我们先定义一些变量:
表示词
在词
上下文中出现的次数。
表示任何词出现在词
表示词
我们来看一下论文作者提供的一个表格:
表 1 显示了一个大型语料库的概率及其比率结果,其中取 和
。对于与 ice 有关但与 steam 无关的词
,比如
,
远大于 1。类似地,对于与 steam 有关但与 ice 无关的词
,比如
,比率远小于 1。对于像 water 或 fashion 这样的词
,要么与 ice 和 steam 都有关,要么与两者都无关,其比率接近 1。与原始概率相比,该比率能够更好地区分相关词(solid 和 gas)和不相关词(water 和 fashion),并且能够更好地区分两个相关词。
上述论证表明,通过概率的比率而不是概率本身去学习词向量是一个更合适的方法。比率 取决于三个词
,
和
,最通用的模型采用以下形式:
其中, 是词向量,
是单独的上下文词向量。在这个等式中,右边是从语料库中提取的,
可能取决于一些尚未确定的参数。因为向量空间是线性结构的,所以要表达出两个概率的比例差,最自然的方法是使用向量差,即可得到:
接下来,我们注意到等式(2)中 的参数是向量,而右边是标量,于是我们把
的参数作点积操作,得到:
我们知道 是对称矩阵,词和上下文词其实是相对的,也就是如果我们做如下交换:
,
,式(3)应该保持不变。很显然,现在的公式是不满足的。然而,对称性可以通过两步实现。首先,我们要求
满足同态特性,即:
结合等式(3)得到:
令等式(4)中 ,得到:
接下来,我们注意到,如果不是右边的 ,等式(6)将表现出交换对称性。然而,该项与
无关,因此它可以被吸收为
的偏置项
。最后,为
添加一个偏置
实现对称性:
这样,我们就得到了词向量和共现矩阵之间的近似关系。
2.3 构造损失函数
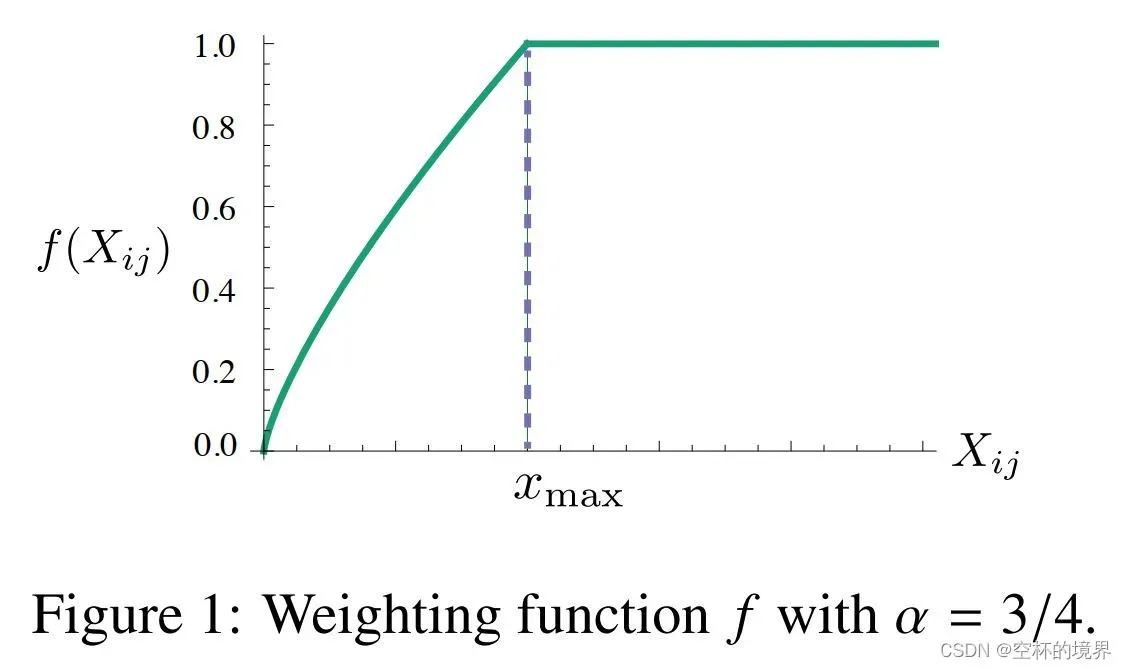
作者在论文中提出了一个新的加权最小二乘回归模型来构造损失函数。将等式(7)看作一个最小二乘问题,并在损失函数中引入权重函数 :
其中 是词库的大小。
因为少见的共现携带有噪声,并且比频繁的共现携带更少的信息。添加权重函数可以避免对所有共现事件赋予相同的权重。从而权重函数应符合以下特性:
-
。如果
被看作一个连续函数,它应该随着
足够快地消失,使得
是有限的。
-
应该是非递减的,这样少见的共现权重不会过大。
-
对于较大的
值,
很多函数满足这些性质,作者发现如下形式的函数表现良好:
文章出处登录后可见!