深度学习初级课程
正文
寻找希格斯玻色子
标准模型是粒子物理学中的一种理论,它描述了一些最基本的自然力。希格斯玻色子是一种基本粒子,它可以解释物质的质量。希格斯玻色子最早是在1964年提出理论的,近50年来一直没有被观测到。2012年,最终在大型强子对撞机上进行了实验观测。这些实验产生了数百万GB的数据。
像这样庞大而复杂的数据集是深度学习的优势所在。在本文中,我们将建立一个广泛而深入的神经网络,以确定观察到的粒子碰撞是否产生了希格斯玻色子。
碰撞数据
高能质子碰撞可以产生像希格斯玻色子这样的新粒子。然而,这些粒子不能被直接观察到,因为它们几乎是瞬间衰变的。因此,为了检测新粒子的存在,我们转而观察它们衰变成的粒子的行为,它们的“衰变产物”。
希格斯数据集包含衰变产物的21个“低水平”特征,以及由此衍生的另外7个“高水平”特征。
广度和深度神经网络
一个宽而深的网络将一个线性层与一堆密集的层并排排列。广泛而深入的网络通常对表格数据集有效。[^1]
数据集和模型都比我们在课程中使用的要大得多。为了加快训练,我们将使用Kaggle的 Tensor Processing Units(TPU),这是一种适合大工作量的加速器。
我们在这里收集了一些超参数,以简化实验。点击这里亲自尝试一下,就可以 Fork 这个笔记了!
# Model Configuration
UNITS = 2 ** 11 # 2048
ACTIVATION = 'relu'
DROPOUT = 0.1
# Training Configuration
BATCH_SIZE_PER_REPLICA = 2 ** 11 # powers of 128 are best
接下来的几节建立了TPU计算、数据管道和神经网络模型。如果您只想看到结果,请跳到结尾!
安装程序
除了我们的导入之外,本节还包含一些将笔记本电脑连接到TPU并创建分发策略的代码。每个TPU有八个独立运行的计算核。通过分发策略,我们可以定义如何在他们之间分配工作。
# TensorFlow
import tensorflow as tf
print("Tensorflow version " + tf.__version__)
# Detect and init the TPU
try: # detect TPUs
tpu = tf.distribute.cluster_resolver.TPUClusterResolver.connect() # TPU detection
strategy = tf.distribute.TPUStrategy(tpu)
except ValueError: # detect GPUs
strategy = tf.distribute.get_strategy() # default strategy that works on CPU and single GPU
print("Number of accelerators: ", strategy.num_replicas_in_sync)
# Plotting
import pandas as pd
import matplotlib.pyplot as plt
# Matplotlib defaults
plt.style.use('seaborn-whitegrid')
plt.rc('figure', autolayout=True)
plt.rc('axes', labelweight='bold', labelsize='large',
titleweight='bold', titlesize=18, titlepad=10)
# Data
from kaggle_datasets import KaggleDatasets
from tensorflow.io import FixedLenFeature
AUTO = tf.data.experimental.AUTOTUNE
# Model
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras import callbacks
Tensorflow version 2.4.1
Number of accelerators: 8
请注意,TensorFlow 现在检测到八个加速器。使用TPU有点像同时使用八个GPU。
加载数据
数据集已编码为名为TFRecords的二进制文件格式。这两个函数将解析TFRecords并构建 tf.data.Dataset。数据可用于训练的Dataset对象。
def make_decoder(feature_description):
def decoder(example):
example = tf.io.parse_single_example(example, feature_description)
features = tf.io.parse_tensor(example['features'], tf.float32)
features = tf.reshape(features, [28])
label = example['label']
return features, label
return decoder
def load_dataset(filenames, decoder, ordered=False):
AUTO = tf.data.experimental.AUTOTUNE
ignore_order = tf.data.Options()
if not ordered:
ignore_order.experimental_deterministic = False
dataset = (
tf.data
.TFRecordDataset(filenames, num_parallel_reads=AUTO)
.with_options(ignore_order)
.map(decoder, AUTO)
)
return dataset
dataset_size = int(11e6)
validation_size = int(5e5)
training_size = dataset_size - validation_size
# For model.fit
batch_size = BATCH_SIZE_PER_REPLICA * strategy.num_replicas_in_sync
steps_per_epoch = training_size // batch_size
validation_steps = validation_size // batch_size
# For model.compile
steps_per_execution = 256
feature_description = {
'features': FixedLenFeature([], tf.string),
'label': FixedLenFeature([], tf.float32),
}
decoder = make_decoder(feature_description)
data_dir = KaggleDatasets().get_gcs_path('higgs-boson')
train_files = tf.io.gfile.glob(data_dir + '/training' + '/*.tfrecord')
valid_files = tf.io.gfile.glob(data_dir + '/validation' + '/*.tfrecord')
ds_train = load_dataset(train_files, decoder, ordered=False)
ds_train = (
ds_train
.cache()
.repeat()
.shuffle(2 ** 19)
.batch(batch_size)
.prefetch(AUTO)
)
ds_valid = load_dataset(valid_files, decoder, ordered=False)
ds_valid = (
ds_valid
.batch(batch_size)
.cache()
.prefetch(AUTO)
)
建模
现在数据已经准备好了,让我们定义网络。我们正在使用Keras的函数API定义网络的深层分支,这比我们在课程中使用的顺序方法要灵活一些。
def dense_block(units, activation, dropout_rate, l1=None, l2=None):
def make(inputs):
x = layers.Dense(units)(inputs)
x = layers.BatchNormalization()(x)
x = layers.Activation(activation)(x)
x = layers.Dropout(dropout_rate)(x)
return x
return make
with strategy.scope():
# Wide Network
wide = keras.experimental.LinearModel()
# Deep Network
inputs = keras.Input(shape=[28])
x = dense_block(UNITS, ACTIVATION, DROPOUT)(inputs)
x = dense_block(UNITS, ACTIVATION, DROPOUT)(x)
x = dense_block(UNITS, ACTIVATION, DROPOUT)(x)
x = dense_block(UNITS, ACTIVATION, DROPOUT)(x)
x = dense_block(UNITS, ACTIVATION, DROPOUT)(x)
outputs = layers.Dense(1)(x)
deep = keras.Model(inputs=inputs, outputs=outputs)
# Wide and Deep Network
wide_and_deep = keras.experimental.WideDeepModel(
linear_model=wide,
dnn_model=deep,
activation='sigmoid',
)
wide_and_deep.compile(
loss='binary_crossentropy',
optimizer='adam',
metrics=['AUC', 'binary_accuracy'],
experimental_steps_per_execution=steps_per_execution,
)
训练
在训练期间,我们将像往常一样使用EarlyStopping回调。请注意,我们还定义了学习速率计划。研究发现,在训练过程中逐渐降低学习率可以提高成绩(权重“适应”到最小)。如果验证损失在一个epoch后没有减少,此计划将学习率乘以0.2。
early_stopping = callbacks.EarlyStopping(
patience=2,
min_delta=0.001,
restore_best_weights=True,
)
lr_schedule = callbacks.ReduceLROnPlateau(
patience=0,
factor=0.2,
min_lr=0.001,
)
history = wide_and_deep.fit(
ds_train,
validation_data=ds_valid,
epochs=50,
steps_per_epoch=steps_per_epoch,
validation_steps=validation_steps,
callbacks=[early_stopping, lr_schedule],
)
Epoch 1/50
640/640 [==============================] - 168s 263ms/step - loss: 0.6084 - auc: 0.7547 - binary_accuracy: 0.6890 - val_loss: 0.7376 - val_auc: 0.7030 - val_binary_accuracy: 0.5391
Epoch 2/50
640/640 [==============================] - 27s 43ms/step - loss: 0.4968 - auc: 0.8357 - binary_accuracy: 0.7534 - val_loss: 0.4887 - val_auc: 0.8417 - val_binary_accuracy: 0.7582
Epoch 3/50
640/640 [==============================] - 28s 45ms/step - loss: 0.4779 - auc: 0.8492 - binary_accuracy: 0.7652 - val_loss: 0.4781 - val_auc: 0.8499 - val_binary_accuracy: 0.7665
Epoch 4/50
640/640 [==============================] - 27s 43ms/step - loss: 0.4697 - auc: 0.8550 - binary_accuracy: 0.7706 - val_loss: 0.4740 - val_auc: 0.8542 - val_binary_accuracy: 0.7712
Epoch 5/50
640/640 [==============================] - 27s 43ms/step - loss: 0.4632 - auc: 0.8594 - binary_accuracy: 0.7748 - val_loss: 0.4712 - val_auc: 0.8552 - val_binary_accuracy: 0.7710
Epoch 6/50
640/640 [==============================] - 28s 44ms/step - loss: 0.4575 - auc: 0.8633 - binary_accuracy: 0.7786 - val_loss: 0.4577 - val_auc: 0.8657 - val_binary_accuracy: 0.7787
Epoch 7/50
640/640 [==============================] - 27s 42ms/step - loss: 0.4521 - auc: 0.8668 - binary_accuracy: 0.7819 - val_loss: 0.4527 - val_auc: 0.8671 - val_binary_accuracy: 0.7824
Epoch 8/50
640/640 [==============================] - 26s 41ms/step - loss: 0.4472 - auc: 0.8700 - binary_accuracy: 0.7850 - val_loss: 0.4459 - val_auc: 0.8713 - val_binary_accuracy: 0.7867
Epoch 9/50
640/640 [==============================] - 26s 41ms/step - loss: 0.4431 - auc: 0.8726 - binary_accuracy: 0.7876 - val_loss: 0.4478 - val_auc: 0.8703 - val_binary_accuracy: 0.7857
Epoch 10/50
640/640 [==============================] - 27s 42ms/step - loss: 0.4392 - auc: 0.8751 - binary_accuracy: 0.7900 - val_loss: 0.4367 - val_auc: 0.8766 - val_binary_accuracy: 0.7908
Epoch 11/50
640/640 [==============================] - 26s 41ms/step - loss: 0.4355 - auc: 0.8774 - binary_accuracy: 0.7922 - val_loss: 0.4353 - val_auc: 0.8775 - val_binary_accuracy: 0.7922
Epoch 12/50
640/640 [==============================] - 26s 41ms/step - loss: 0.4322 - auc: 0.8795 - binary_accuracy: 0.7942 - val_loss: 0.4325 - val_auc: 0.8794 - val_binary_accuracy: 0.7939
Epoch 13/50
640/640 [==============================] - 27s 41ms/step - loss: 0.4288 - auc: 0.8815 - binary_accuracy: 0.7963 - val_loss: 0.4304 - val_auc: 0.8808 - val_binary_accuracy: 0.7953
Epoch 14/50
640/640 [==============================] - 27s 42ms/step - loss: 0.4256 - auc: 0.8835 - binary_accuracy: 0.7985 - val_loss: 0.4279 - val_auc: 0.8821 - val_binary_accuracy: 0.7966
Epoch 15/50
640/640 [==============================] - 28s 43ms/step - loss: 0.4224 - auc: 0.8854 - binary_accuracy: 0.8003 - val_loss: 0.4268 - val_auc: 0.8830 - val_binary_accuracy: 0.7974
Epoch 16/50
640/640 [==============================] - 29s 45ms/step - loss: 0.4190 - auc: 0.8874 - binary_accuracy: 0.8024 - val_loss: 0.4262 - val_auc: 0.8833 - val_binary_accuracy: 0.7981
Epoch 17/50
640/640 [==============================] - 28s 43ms/step - loss: 0.4158 - auc: 0.8892 - binary_accuracy: 0.8042 - val_loss: 0.4252 - val_auc: 0.8841 - val_binary_accuracy: 0.7985
Epoch 18/50
640/640 [==============================] - 28s 44ms/step - loss: 0.4126 - auc: 0.8911 - binary_accuracy: 0.8061 - val_loss: 0.4249 - val_auc: 0.8844 - val_binary_accuracy: 0.7994
Epoch 19/50
640/640 [==============================] - 28s 43ms/step - loss: 0.4095 - auc: 0.8929 - binary_accuracy: 0.8079 - val_loss: 0.4241 - val_auc: 0.8850 - val_binary_accuracy: 0.8001
Epoch 20/50
640/640 [==============================] - 27s 43ms/step - loss: 0.4060 - auc: 0.8948 - binary_accuracy: 0.8100 - val_loss: 0.4249 - val_auc: 0.8844 - val_binary_accuracy: 0.7996
Epoch 21/50
640/640 [==============================] - 28s 43ms/step - loss: 0.4024 - auc: 0.8968 - binary_accuracy: 0.8121 - val_loss: 0.4253 - val_auc: 0.8847 - val_binary_accuracy: 0.8002
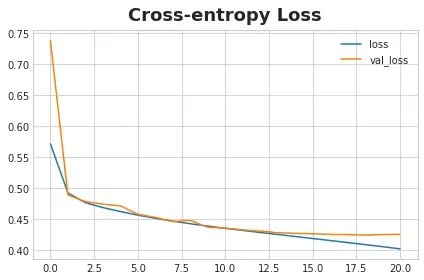
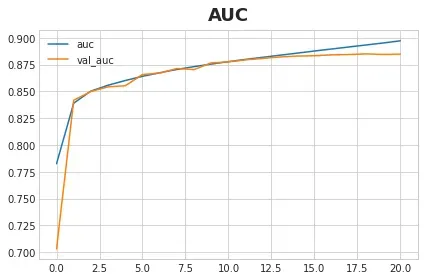
history_frame = pd.DataFrame(history.history)
history_frame.loc[:, ['loss', 'val_loss']].plot(title='Cross-entropy Loss')
history_frame.loc[:, ['auc', 'val_auc']].plot(title='AUC');
参考资料
Baldi, P. et al. Searching for Exotic Particles in High-Energy Physics with Deep Learning. (2014) (arXiv)
Cheng, H. et al. Wide & Deep Learning for Recommender Systems. (2016) (arXiv)
What Exactly is the Higgs Boson? Scientific American. (1999) (article)]
文章出处登录后可见!