- 重要度采样比的概念在 RL 中似乎很简单,我以前也没太关注过,最近看 PER 论文突然想到一个问题,为何基于 DQN 的 PER 需要重要度采样比,而基于 Q-learning 的优先级 Dyna-Q 则不用,由此引发的一些思考整理成此文
- 开篇先说一下我的看法,针对 off-policy 的 value based control 方法
- MC Control 类方法使用行为策略
收集的数据估计目标策略
对应的价值
,必须用重要性采样比调整期望
- TD Control 方法基于 Bellman Optimal Equation,使用行为策略
对应的价值
得到
,进而导出行为策略
- 对于使用的函数近似的 TD control 方法而言,由于函数近似方法本身的性质,它们得到的价值估计总会存在误差(注意并不是 “错误”),行为策略
,价值估计误差越大。这时我们应该避免使用和目标策略
总是有较小的估计误差。DQN 中行为
- MC Control 类方法使用行为策略
-
重要度采样比主要用于 off-policy 的 value based control 方法,这类方法特点为
- value based 意味着 agent 首先估计价值函数,再从中导出策略
- off-policy 意味着 agent 学习的 target policy
解 control 问题时,此类方法通常基于 policy iteration 思想,不停循环 “估计目标策略价值” 和 “优化目标策略” 两步直到收敛,示意图如下
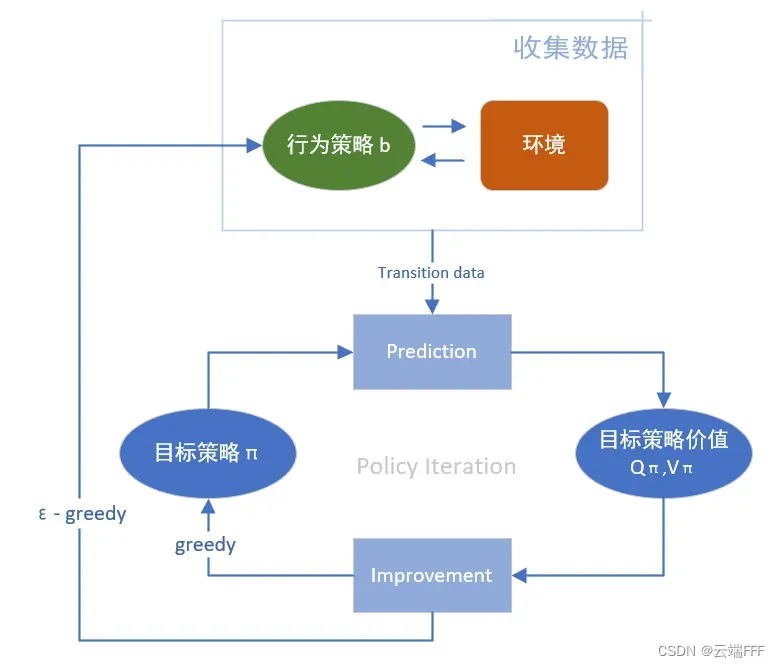
1. 什么是重要度采样比
- 有时我们想估计目标分布下某一统计量的期望值,但是只有另一个分布的样本,这种利用来自其他分布的样本估计目标分布期望值的通用方法称为
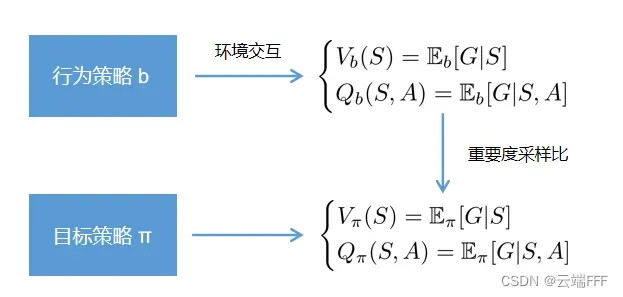
重要度采样 - 观察前面的算法交互图,我们的目标是估计出目标策略
,但是估计时利用的样本全部来自行为策略
进行加权调整,从而获得目标策略
重要度采样比 ρ
- 简而言之,当价值估计方法对行为策略
和目标价值
不相等时,可以使用重要度采样比调整期望,使
,目标价值估计更准确
2. 使用重要度采样比的场景
2.1 MC Control 方法(使用)
-
MC Control 使用蒙特卡洛方法做 prediction,其思想是直接使用经验期望估计真实期望,公式为(
表示估计)
显然经验期望是受到行为策略影响的,因此需要做重要度采样
-
对于这种 MC prediction,有两种重要度采样方法,定义
为所有访问过状态
的时刻的集合
- 使用
普通重要度采样比:,得到无偏估计
,但方差无界
- 使用
加权重要度采样比:,得到有偏估计
,但可收敛到0
- 使用
-
估计
的情况完全类似,这里不再展开,示意图如下
2.2 TD Control 方法(必要时使用)
- 所有 TD 方法的核心都是 Bellman equation 或 Bellman optimal equation,分别对应 on-policy 方法和 off-policy 方法
- 这两个等式有很好的性质,比如他们对应的算子都是压缩映射(可以依此证明价值估计一定收敛),又比如 Off-policy 情况下 TD target 是和行为策略无关的,请看下文分析
2.2.1 Q-learning(不使用)
-
Q-learning 算法直接对 Bellman optimal equation 不停迭代来估计价值,得到的估计期望如下
注意到等式右侧的期望只与状态转移分布
有关而与策略无关,不论训练 transition 来自于哪个策略,按照 Q-Learning 的更新式更新都能使
,又因为 Q-learning 是一个表格型方法没有泛化性,对一个
-
再仔细分析一下,得益于使用 Bellman optimal equation,这里有了一些 value iteration 的意味,我们估计的对象从目标策略的价值
变成了最优策略价值
,这样我们就不用再考虑对
- 原来我们利用
,引入重要度采样是为了更好地估计
- 现在我们利用
- 原来我们利用
-
需要注意的是,不同行为策略
这就好像是用茶壶往一堆杯子里倒水,向一个杯子倒水不会干扰其他杯子。行为策略指导你向哪些杯子倒,其频繁访问的杯子更快装满水(价值收敛),如果所有杯子被访问的概率都大于 0,则时间趋于无穷时总能使所有杯子装满水(价值全部收敛到相同位置)
2.2.2 Dyna-Q(不使用)
- Dyna-Q 是 Sutton 在 RL 圣经中第八章介绍的方法,其实就是 Q-learning 加上了经验重放机制,同一章中还介绍了一种 “优先级遍历算法”,其实就是 Dyna-Q 加上了简化版本的经验优先重放(PER)机制
- 无论是均匀的经验重放,还是不均匀的经验重放,都可以把他们看做行为策略
2.2.3 DQN(不使用)
-
DQN 基本可以看作将 Dyna-Q 直接扩展到深度学习得到的方法,它通过优化 TD error 的 L2 损失使价值估计不断靠近 TD target,最终使所有
的价值估计符合 Bellman optimal equation 等式(收敛),并且引入了经验重放机制
-
具体来说,梯度下降第
轮迭代时损失函数为
其中
是行为策略
是 TD target
损失函数梯度为
和 Q-leaning 非常相似,这里也是基于 Bellman optimal equation 做更新,利用行为策略收集的样本直接估计价值
-
表格型方法没有泛化性,行为策略访问更多的
-
函数近似方法有泛化性,行为策略
这就好像是用水桶往一堆杯子泼水,往一个地方泼水,所有杯子都会溅到,水还可能洒出来。行为策略指导你向哪些泼水,这时行为策略的一点点区别,都会导致各个杯子最终的水量不同
-
-
虽然听起来好像问题很严重,甚至让人怀疑 DQN 这类方法到底能不能接受任意行为策略
- DQN 作为 off-policy 方法是没错的,因为借助 bellman Optimal equation,我们确实可以利用任意行为策略
- DQN 不使用重要度采样比是没错的,可以这样想,假设我们用了一个参数量非常多的价值网络,多到参数量和
虽然没有错,但是我们还是应该尽量避免使用和当前目标策略
- DQN 作为 off-policy 方法是没错的,因为借助 bellman Optimal equation,我们确实可以利用任意行为策略
-
DQN 原文中使用了均匀的经验重放机制,行为策略可以看做近一段时间目标策略
2.2.4 PER(使用)
- PER 是适用于 DQN 系列方法的一个 trick,它在经验回放的过程中以更高的概率重放那些 TD error 更大的 transition,这相当于给原始 DQN 中的行为策略
- PER 论文讲解请参考:论文理解【RL – Exp Replay】 —— 【PER】Prioritized Experience Replay
2.3 其他
- RL 中还有一些重要性采样比的高级用法,比如 “折扣敏感的重要度采样比”(见 Sutton 圣经书 5.8 节),但和本文主要讨论的问题无关,不再展开
文章出处登录后可见!