关注公众号,发现CV技术之美
本文分享 CVPR 2022 论文『BEVT: BERT Pretraining of Video Transformers』,复旦&微软提出 Video 版本 BERT,在多个视频数据集上SOTA!
详细信息如下:

论文链接:https://arxiv.org/abs/2112.01529
项目链接:https://github.com/xyzforever/BEVT
01
摘要
本文研究了视频Transformer的预训练问题。因为最近图像Transformer的BERT预训练取得了成功,这是一个直截了当但值得研究的扩展。作者提出了BEVT,它将视频表示学习解耦为空间表示学习和时间动态学习。具体来说,BEVT首先对图像数据进行mask图像建模,然后对视频数据进行mask图像建模和mask视频建模。
这种设计是由两个观察结果驱动的:1)在图像数据集上学习的Transformer提供了良好的空间先验知识,可以简化视频Transformer的学习,如果从头开始训练,这些Transformer的计算量通常会增加几倍;2) 由于类内和类间的巨大差异,不同视频之间进行正确预测所需的辨别性线索(即空间和时间信息)各不相同。
作者在三个具有挑战性的视频基准上进行了广泛的实验,其中BEVT取得了不错的结果。在Kinetics 400,上,BEVT的识别主要依赖于有区别的空间表示,BEVT可以获得与强监督baseline相当的结果。在Something-Something-V2和Diving 48上,BEVT的性能明显优于所有备选基baseline,达到了SOTA的性能,其Top1准确率分别为71.4%和87.2%。
02
Motivation
Transformer已经成为自然语言处理(NLP)领域的主导网络结构,并在不同的NLP任务中取得了巨大成功。最近,开拓性工作ViT提出将一幅图像转换为一系列基于patch的token,并应用transformer结构进行图像识别。许多方法进一步证明了transformer作为通用视觉backbone的力量,并在各种视觉任务上实现了SOTA的性能。
除了图像任务外,还有一些研究表明transformer在视频理解方面的前景。transformer在NLP中成功的关键是BERT预训练,这是最成功的预训练任务之一,它可以预测损坏文本中的mask token。这促使一些最近的研究探索BERTstyle预训练方法,通过恢复mask图像块的原始像素或潜在代码来进行图像表示学习。然而,如何利用这样的训练策略来理解视频,以前从未进行过探索。
本文研究了视频Transformer的BERT预训练。与静态图像不同,视频描述对象随着时间的推移进行移动和交互。这种动态性为表征学习带来了额外的困难。人们经常发现,从头开始在视频上学习表示在计算上非常昂贵,即使不是数亿个样本的话,也需要数百万个样本的超大规模数据集。
与从头开始的训练不同,一些方法表明,在有监督和无监督设置下,在图像数据集上预训练的自监督模型有利于视频识别。这些方法简单地利用预训练模型作为更好的初始化来学习视频中的时空特征。虽然广泛使用且有时有效,但在视频特征学习过程中,从图像确定阶段学习到的空间上下文关系可能会被大幅修改。
作者认为,在进行视频表示学习时,在预训练的自监督模型中编码的空间先验信息应该被明确地保留。背后的直觉是,不同视频之间存在着巨大的类间差异,它们依赖于使用什么样的鉴别信息(即空间和时间线索)来做出不同的正确预测。
例如,对于像“涂口红”这样的动作,空间知识通常是足够的,简单地使用2D特征就可以在Kinetics等数据集上获得不错的结果,这一事实证明了这一点。另一方面,时间动态对于区分两个细粒度序列之间的作用至关重要,这突出了在特征学习过程中考虑视频样本之间差异的重要性。
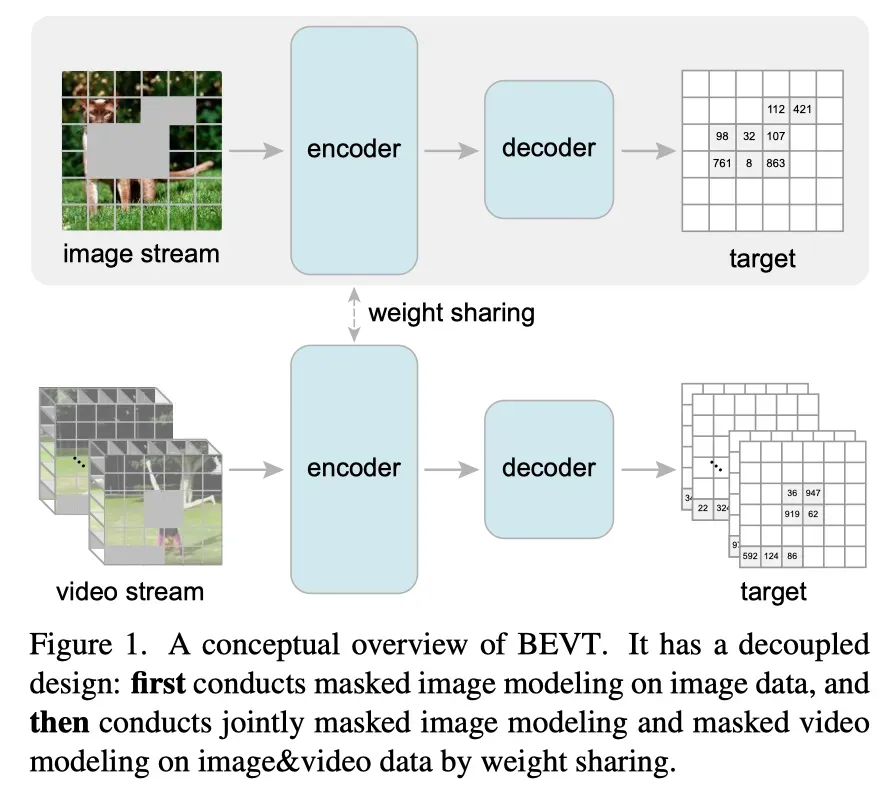
有鉴于此,作者提出了BEVT,它将视频表示学习解耦为空间表示学习和时间动力学学习。更具体地说,BEVT基于视频Swin Transformer,因为其计算效率高,并以BERT风格的目标进行训练,以充分释放Transformer在表征学习中的力量。BEVT包含用于空间建模的图像流和用于时间建模的视频流,它们相互交互用于视频建模。
特别是,在RGB图像上运行的图像流通过预测来自预训练VQ-VAE的潜在代码形式的mask图像块,以无监督的方式首先在ImageNet上学习空间先验知识。然后使用它初始化视频流的注意权重矩阵,视频流的输入是采样的视频片段,以节省视频transformer的计算。
另一方面,视频流通过预测潜在代码表示的mask 3D tube来学习视频中的时间动态。这两个流将图像和视频对作为输入,然后通过权重共享策略对视频数据进行联合训练。这样的设计不仅保持了从图像中学习的空间知识,确保静态视频样本的良好结果,也可以学习时间信息,以确保对包含动态运动的样本进行正确预测。最后,BEVT在目标数据集上进行调整,以进行下游评估。
本文的主要贡献总结如下:
作者探索BERT风格的训练目标,以充分发挥transformer的力量,学习有区别的视频表示;
作者引入了一种新的双流网络,该网络将空间表示学习和时间动态学学习解耦;
作者证明了不同的视频样本对时空线索有不同的偏好;
作者在三个具有挑战性的视频基准上进行了广泛的实验,并使用最先进的方法取得了相当或更好的结果。
03
方法
BEVT的目标是以自监督的方式有效地学习相对静态视频和动态视频的视频表示。这里,“相对静态视频”指的是仅需要辨别性空间表示才能识别的视频,而“动态视频”指的是也需要时间动态才能识别的视频。除了有效性之外,视频预训练中需要考虑的另一个关键问题是效率。与图像预训练相比,视频预训练的计算成本更高,因此在没有大量计算资源的情况下,从头开始对大规模视频数据进行预训练是不够的,甚至是不适用的。
为此,BEVT将视频预训练解耦为空间表示学习和时间动态学习。空间表示学习仅对图像数据进行,时间动态学习对视频数据进行。为了实现这个想法,本文的BEVT包含两个流,分别对图像和视频进行操作。
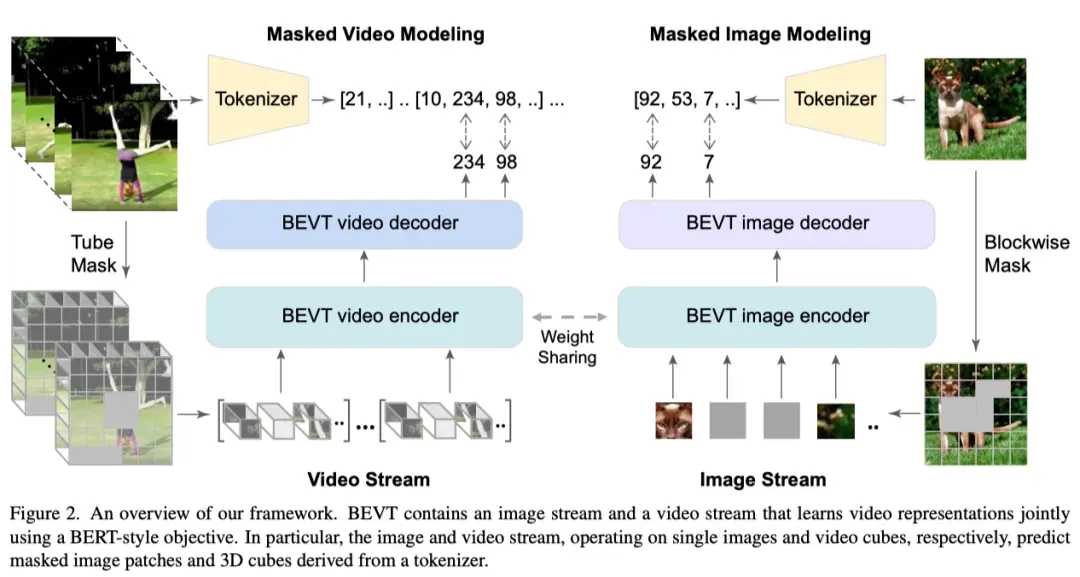
Image and video patches
对于视频流,给定视频片段和T帧,作者采用VideoSwin,将其转换为个 3D patch,每个patch大小为;每个三维patch包含96维特征。对于图像流,给定输入图像,作者将每个大小为4×4×3的patch视为一个token,并将每个token的特征维数设置为48。然后,作者通过线性嵌入层将每个token投影到维度为C的token嵌入向量,并将token嵌入序列输入到transformer架构中。
Masked image and video tokens
受BERT在NLP任务中取得巨大成功的启发,BEVT被优化为通过分别预测“损坏”的图像和视频token来同时执行掩蔽图像建模(MIM)和掩蔽视频建模(MVM)。MIM用于捕获空间先验信息,而MVM用于捕获视频中的时间动态信息。对于图像流,由于输入图像被划分为非重叠的patch,作者随机屏蔽几个patch,并训练图像流来恢复它们。
具体来说,每个masked patch的嵌入特征被可学习的mask token嵌入所取代。对于视频流,作者随机屏蔽3D token,并训练视频流预测这些masked token。屏蔽图像和视频token集以及其余patch特征将送入到编码器。
Mask strategy
对于mask图像建模,作者使用blockwise masking,而不是随机选择每个遮罩patch。在为图像生成mask位置时,作者每次mask一块patch,并为每个块设置最小patch数。在预设范围内随机选择每个块的位置、纵横比和大小。重复进行mask block操作,直到mask patch的比率超过预设的下限。
对于屏蔽视频建模,作者采用了一种tube屏蔽策略,它是块屏蔽的直接扩展。给定长度为T的输入视频片段,作者首先随机选择遮罩帧数(tube长度)l和开始帧t。然后,作者使用blockwise masking生成2D masking,并将该2D mask应用于从t到t+l的每个帧。换句话说,对于每个mask帧,mask位置集是相同的,整个3D mask的形状是一个tube。mask tube长度范围为[0.5T,T],每个mask框的masking ratio为0.5。
BEVT encoders
BEVT包含两个编码器,一个用于图像流,一个用于视频流。这两种编码器都是用视频Swin Transformer实例化的,因为它具有强大的性能和适中的计算成本。作者使用视频Swin Transformer作为自监督学习的主干。
具体而言,视频Swin Transformer遵循Swin Transformer的设计,是一个由四个阶段组成的层次结构。在每两个阶段之间,通过patch合并层执行空间下采样,这将关联每组2×2空间相邻patch的特征。下采样后,线性层将每个concatenated token的特征映射到其维数的一半。在应用特征变换之后,会出现一系列Swin attention blocks。
给定一系列token作为输入,视频编码器输出一个大小为的特征映射。由于视频Swin Transformer仅在开始的线性嵌入层中执行时间下采样,因此当输入的时间维度为1时,它将退化为2D架构。因此,对于图像编码器,输出特征映射的大小为。
Tokenizer
作者使用预训练图像VQ-VAE生成的视觉token作为ground truth token,本文的预训练任务是预测mask patch的token。经过预训练的VQ-VAE tokenizer通过在其预先学习的视觉码本中搜索最近的潜在代码,将图像块映射为离散token。
给定输入图像,它将被tokenize为的视觉token map。类似的,对于输入 视频,可以tokenize为。考虑到预训练的VQ-VAE仅将8×8 patch下采样为一个token,作者在输入tokenizer之前将输入图像/帧下采样1/2,以便输出token map的空间分辨率为。
BEVT decoders
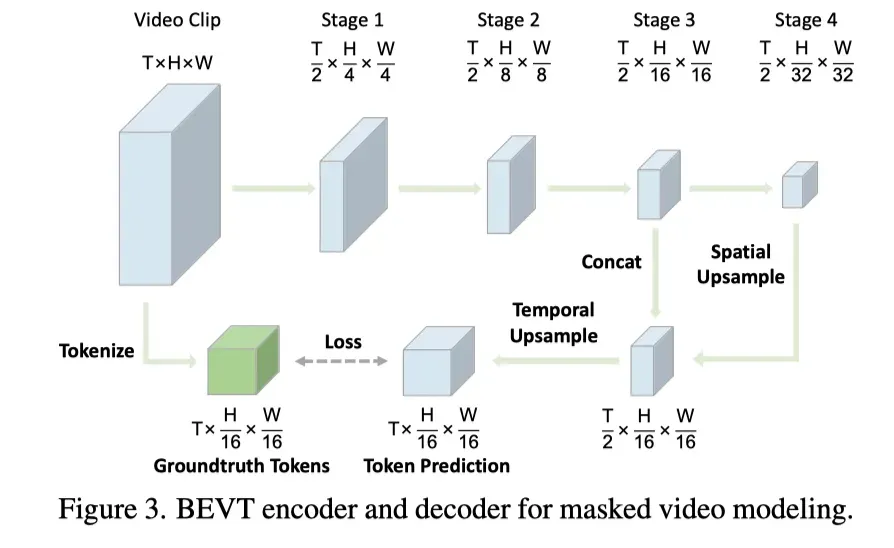
为了通过预测输入中mask图像和视频patch的token来学习有意义的表示,BEVT有一个图像解码器和一个视频解码器作为预测头。现有的现代视觉Transformer(包括Swin Transformer)遵循层次化设计,并对输入进行降采样,以降低空间/时间分辨率。以上图所示视频流的VideoSwin为例,它包括四个阶段,最后一阶段的特征映射的维数为。
为了将特征映射的尺寸与groundtruth视觉token的数量相匹配,作者为BEVT中的视频流设计了一个轻量级的解码器。它首先使用转置卷积层对第四阶段特征进行空间上采样,然后将上采样的第四阶段特征与第三阶段特征连接在一起,并将其与简单的线性层融合。最后,融合特征F将使用另一转置卷积层进行时间上采样:

为了预测每个位置的token,在F上应用一个简单的基于softmax的分类器:
![]()
其中,是位置处输出特征映射的特征向量,表示相应的概率向量。W和b是线性层的权重和偏差。对于图像流中的解码器,它遵循类似的设计,唯一的区别是没有时间上采样部分。
Training objectives
将masked patches在输入图像和视频中的位置表示为和,mask图像建模的目标是最大化每个mask位置的groundtruth token 的对数似然。
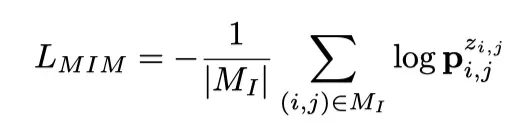
其中p的上标表示索引一个特定位置的概率值。类似地,mask视频建模的目标可以表示为:
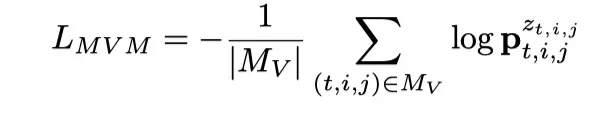
双流联合训练的目标是两个目标的简单组合:
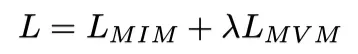
其中λ是平衡图像流和视频流权重的超参数。
Training strategies
在解耦设计之后,作者首先在ImageNet上使用mask图像建模任务训练图像流,以学习区分性空间表示。然后使用得到的模型初始化视频流,并对两个流进行联合训练,以便目标保留空间信息,而学习捕获视频中的时间动态。这种策略不仅使BEVT比从头开始对大规模视频数据进行视频Transformer预训练更有效,而且满足了学习不同类型视频样本的不同辨别线索的需要。
Weight sharing between streams
在联合训练图像和视频流时,作者设计了一种权重共享策略,除了一些图像/视频特定部分,能使它们能够共享编码器的模型权重,而不是独立学习两个流的两组模型权重。这是由transformer网络的良好特性推动的,即大多数操作符(包括多头注意和FFN)面向token,而不是特定的输入类型。以视频Swin transformer为例,作者使用以下策略进行权重共享:
作者使用独立的2D patch分割层代替3D patch分割,并在第一阶段添加线性嵌入层,用于将图像token投影到与原始3D视频patch嵌入相同的维度;
作者将3D移动的局部窗口调整为2D场景。通过重用原始三维相对位置嵌入的子矩阵(其中相对时间距离为0)作为二维相对位置嵌入,可以实现这一点。通过这样的设计,图像流和视频流可以通过优化一个“基本上没有改变”的编码器来提高效率。
Finetuning and inference
经过预训练后,BEVT提供了良好的视频表示,可以迁移到下游任务。在目标数据集上,作者只需使用3D patch嵌入层和视频编码器,其中附加了一些任务特定层(例如,视频识别的分类头),用于网络微调。由此产生的模型可以很容易地用于推理。
04
实验
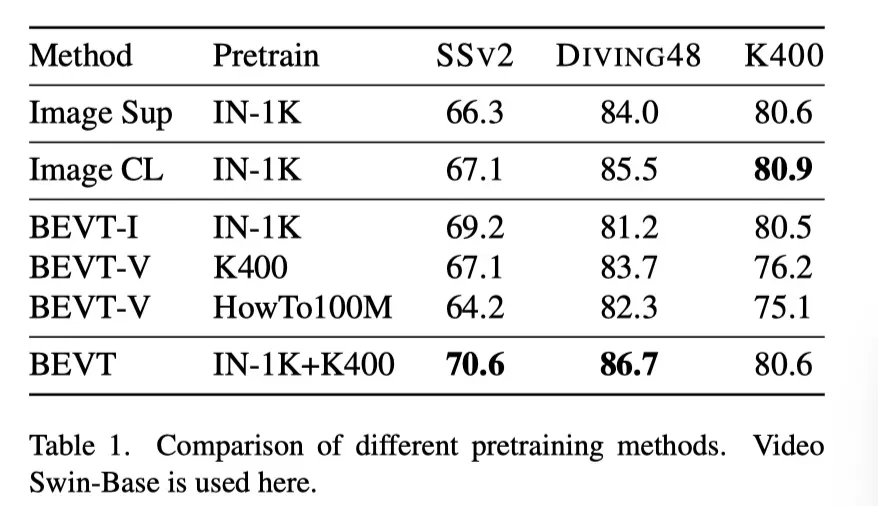
上表展示了不同预训练方法在多个数据集上的实验结果。
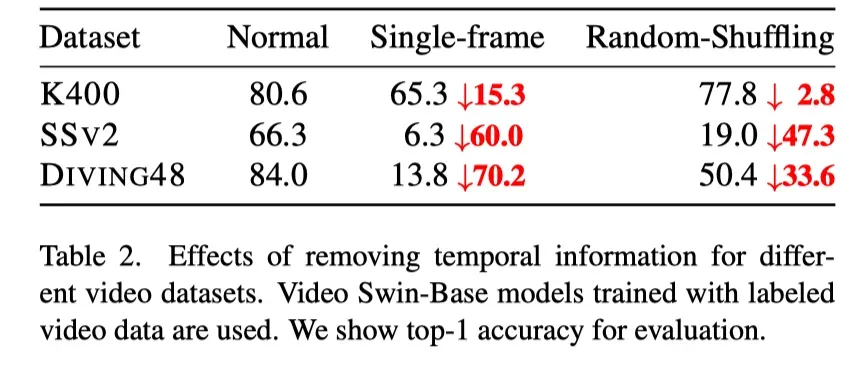
上表展示了用不同的方法去除时间信息的实验结果。
可以看出,在K400等空间线索占主导地位的数据集上,将模型与空间先验进行调整,例如在图像上进行预训练,可以获得良好的性能。附加视频建模对整体性能影响不大;在BEVT中使用视频流对于学习SS V 2和DIVING 48等数据集的必要时间信息至关重要。
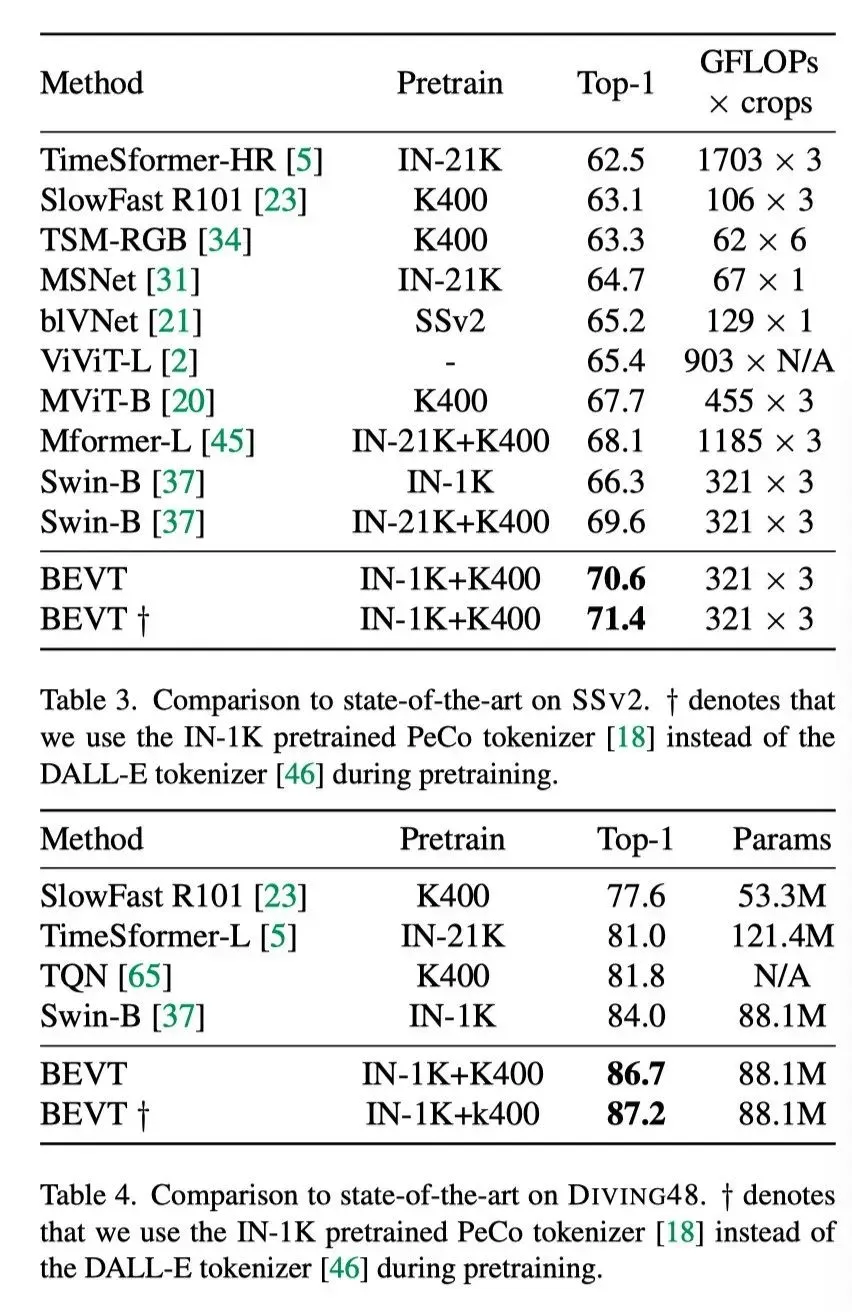
上表展示了BEVT在SSv2和DIVING48数据集上和SOTA结果的对比。
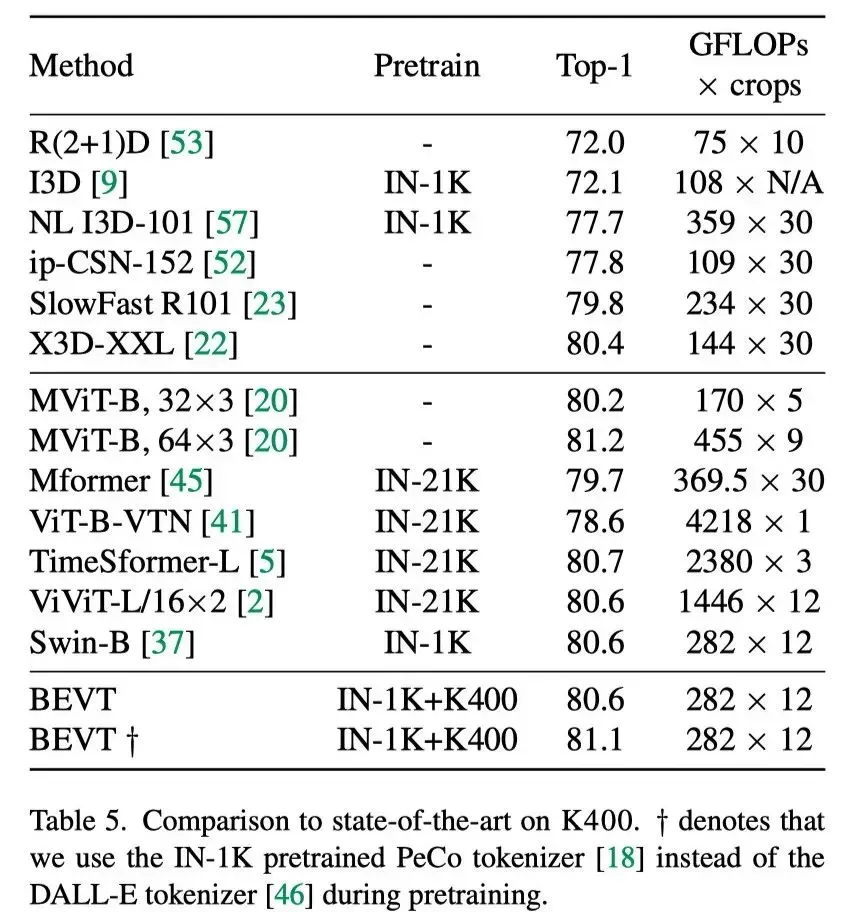
从上表中可以看出,在K400中,BEVT通过使用GFLOPs测量的类似或更少的计算,获得了与SOTA方法具有竞争力的结果。
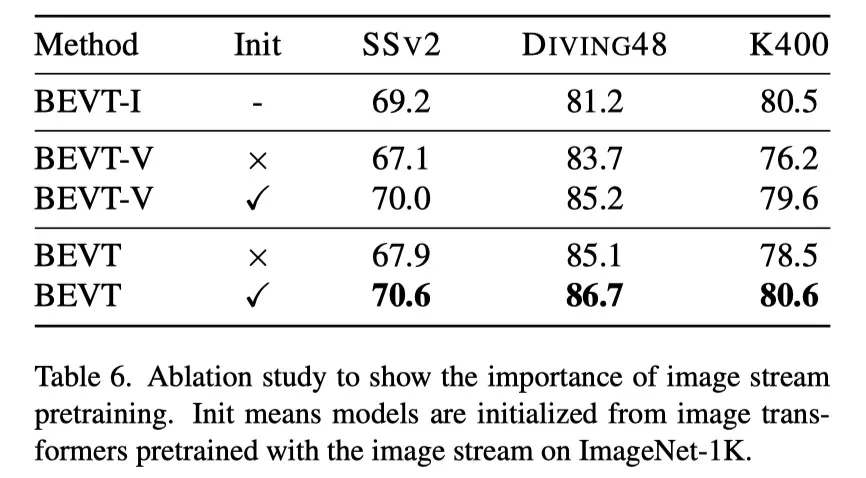
上表的消融研究表明图像流预训练的重要性。
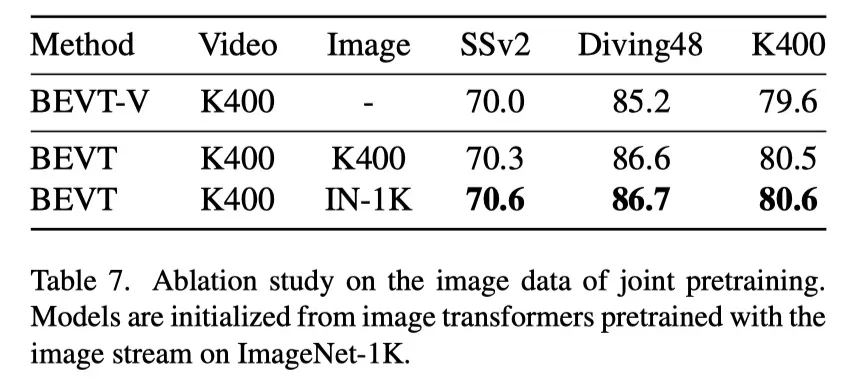
上表展示了联合预训练中图像数据的消融研究。
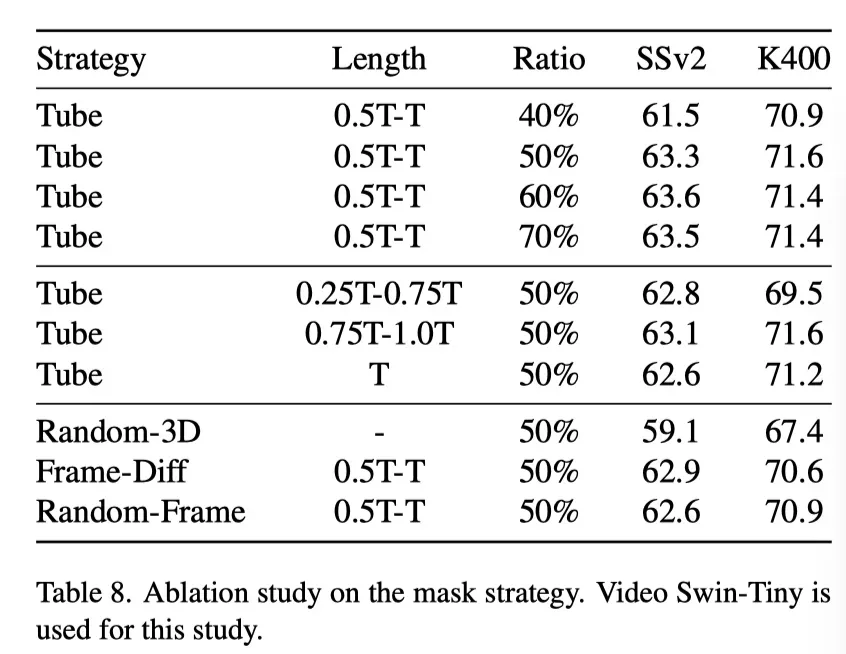
上表展示了不同Mask策略的研究结果。
05
总结
在NLP领域,Transformer已成为的标准架构,并在过去几年中重塑了NLP任务的各种类型。这在很大程度上是由广泛使用的BERT预训练策略驱动的,该策略展示了在大规模数据上预训练大型模型的缩放能力。最近Transformer在各种计算机视觉任务上的成功激发了一系列探索BERT视觉预训练的工作。
与一些同时进行的图像研究不同,作者向前迈出了一步,研究如何探索视频transformer的BERT预训练。这看起来很简单,但值得广泛研究。作者引入了BEVT,它可以学习区分性空间表示和时间动态。在本文中,作者证明了将视频预训练与时空表征学习解耦不仅有效,而且高效。通过BEVT的简单设计,作者在三个视频识别数据集上实现了SOTA性能。
参考资料
[1]https://arxiv.org/abs/2112.01529
[2]https://github.com/xyzforever/BEVT

END
加入「Transformer」交流群👇备注:TFM

文章出处登录后可见!