Computer Vision 里面的 Self-attention Head
queries, keys 和 values 的计算方式
queries, keys 和 values 是输入 通过全连接层得到,具体如下:
queries
keys
values
where the dimensions of query and key must be equal, which is .
在 Vision Transformer 里,,为输入图片 patches 的个数 + 一个用于分类的
token,为了方便,在以下的比较中,令 , 并且
和
取作
.
矩阵乘法的 Flop
的
Flop 为 .
1. 单头 Self-attention
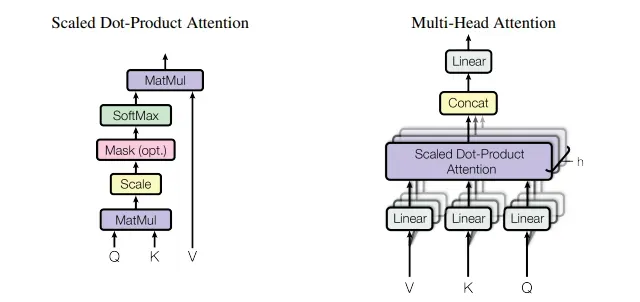
self-attention
单头注意力模块的 Flop :
2. Multi-Head Attention
原论文中每个 head 的获取方式是通过一个 linear project 得到的(全连接层),但是在实现中,正常直接通过对输入进行均分切片得到每一个 head 的输入,因此就省去了 三个全连接层的计算。直接简单均分切片奏效的原因,个人猜测是,网络很容易学到不同
head 所需要的模式应该位于输入 token 的哪几个维度上。以下是原论文的计算方式,这里不使用这种(linear project)计算方法。
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions. With a single attention head, averaging inhibits this.
Where the projections are parameter matrices and
.
直接使用简单均分切片的方法相较于多头注意力模块相比单头注意力模块的计算量仅多了最后一个融合矩阵的计算量
, 所以多头注意力的
Flop 为(详细计算可参见这里):
3. Windowing Multi-Head Attention
假设每个 window 的大小为 ,
Windowing Multi-Head Attention 相当于在 的窗口上做
次
Multi-Head Attention,因此所以Windowing Multi-Head Attention 的 Flop 为:
各式各樣神奇的自注意力機制 (Self-attention) 變型
Notice
- Self-attention is only a module in a larger network.
- Self-attention dominates computation when
Nis large. - Usually developed for image processing
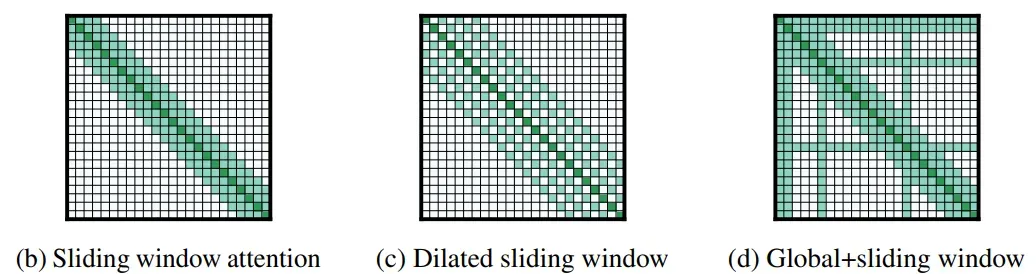
1. Local Attention / Truncated Attention
只考虑相邻 sequence 的 attention .
Self-attention 与 CNN 的区别之一为, self-attention 关注的范围更大,CNN 关注的范围只在局部。因此 Local Attention 在一定程度上抛弃了 self-attention 的优点,与 CNN 更为相似,因此 Local Attention 可以加快运算,但是在性能上不一定能带来提高。
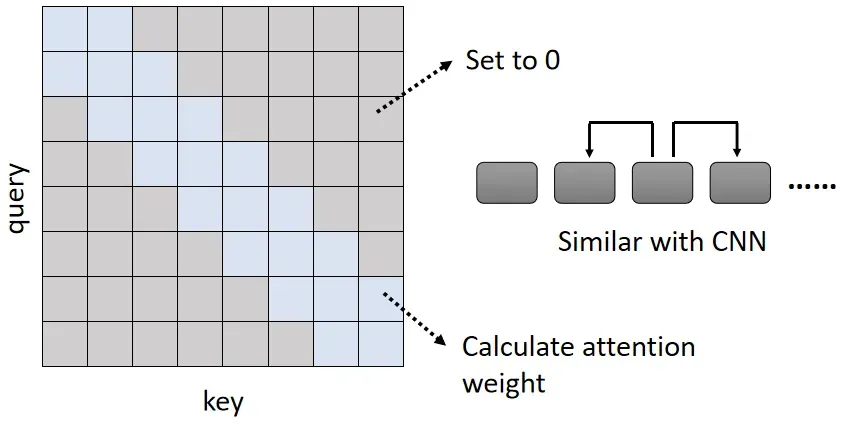
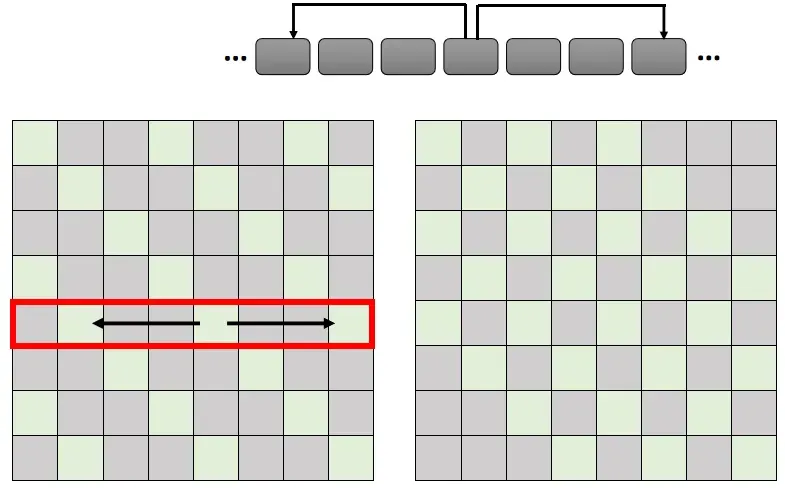
2. Stride Attention
间隔一定的距离做 attention .
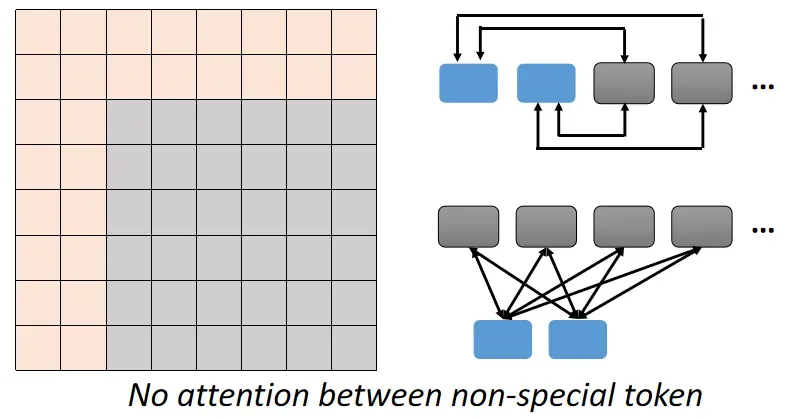
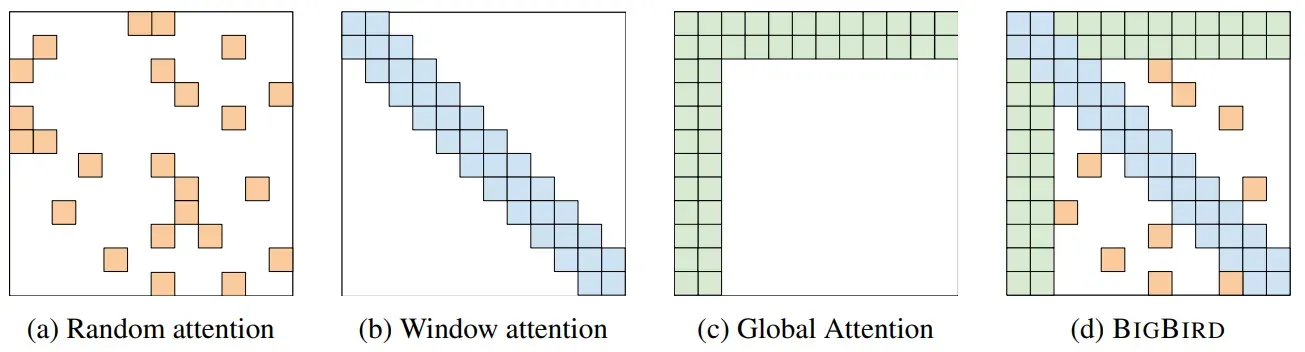
3. Global Attention
Add special token into original sequence
- Attend to every token → collect global information
- Attended by every token → it knows global information
How to choose the right Attention?
Different heads use different patterns.
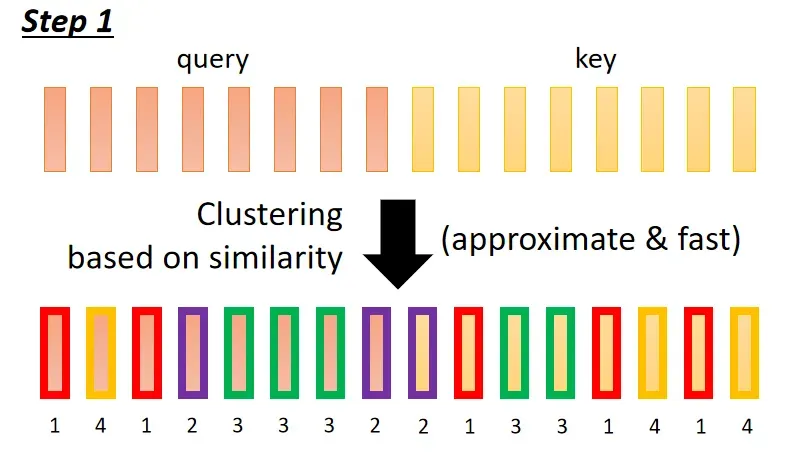
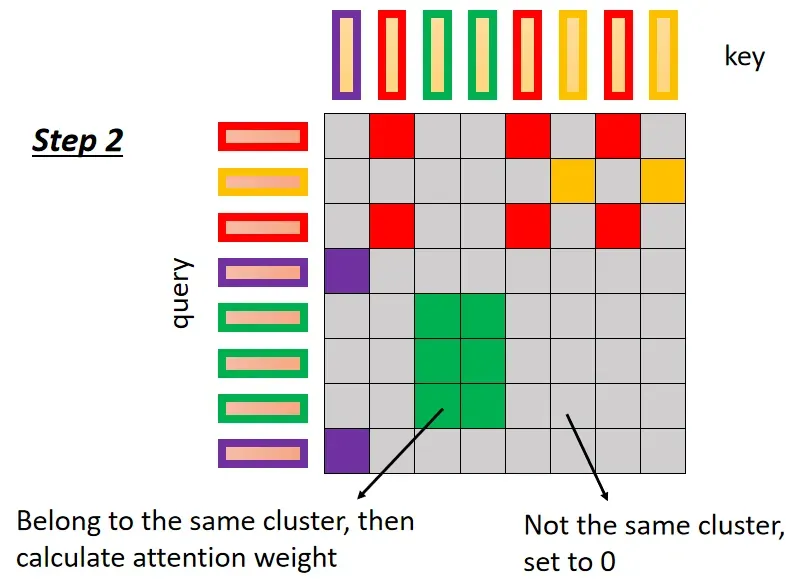
- Clustering Reformer & Routing Transformer
- Learnable Patterns Sinkhorn Sorting Network
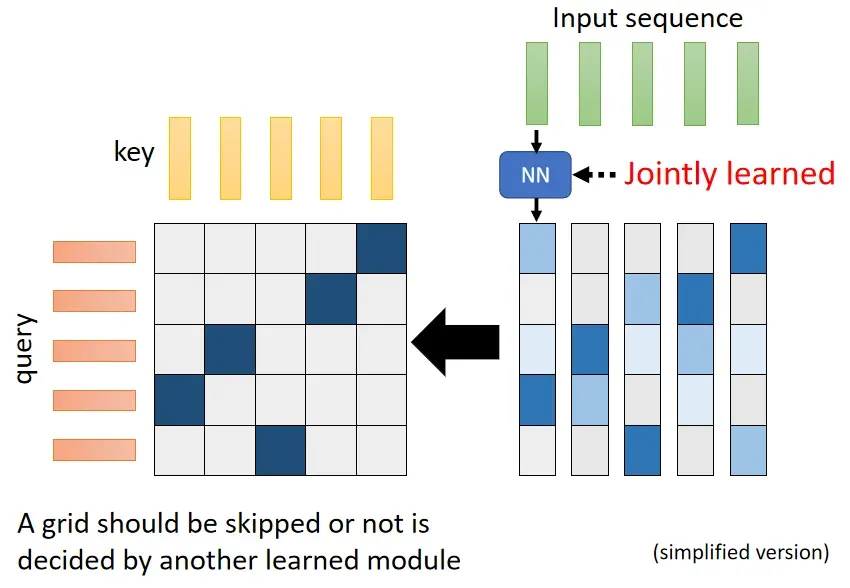
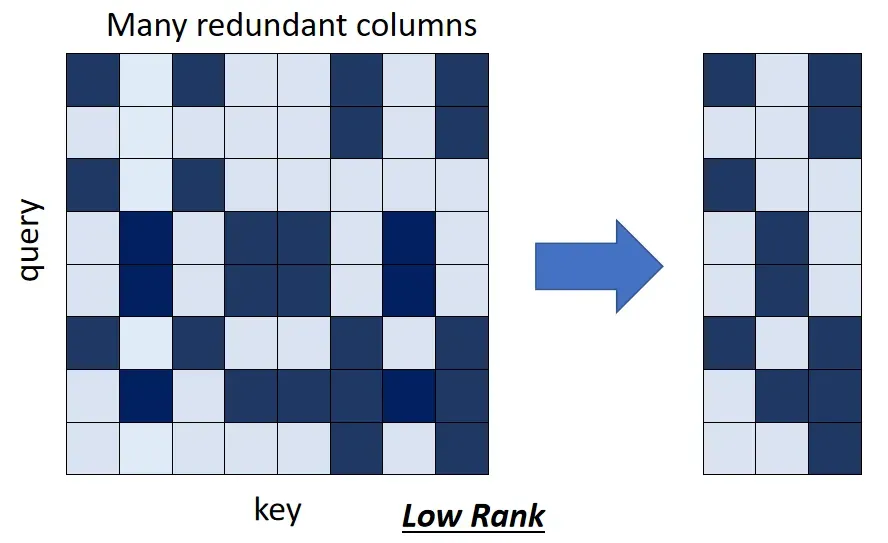
Do we need full attention matrix?
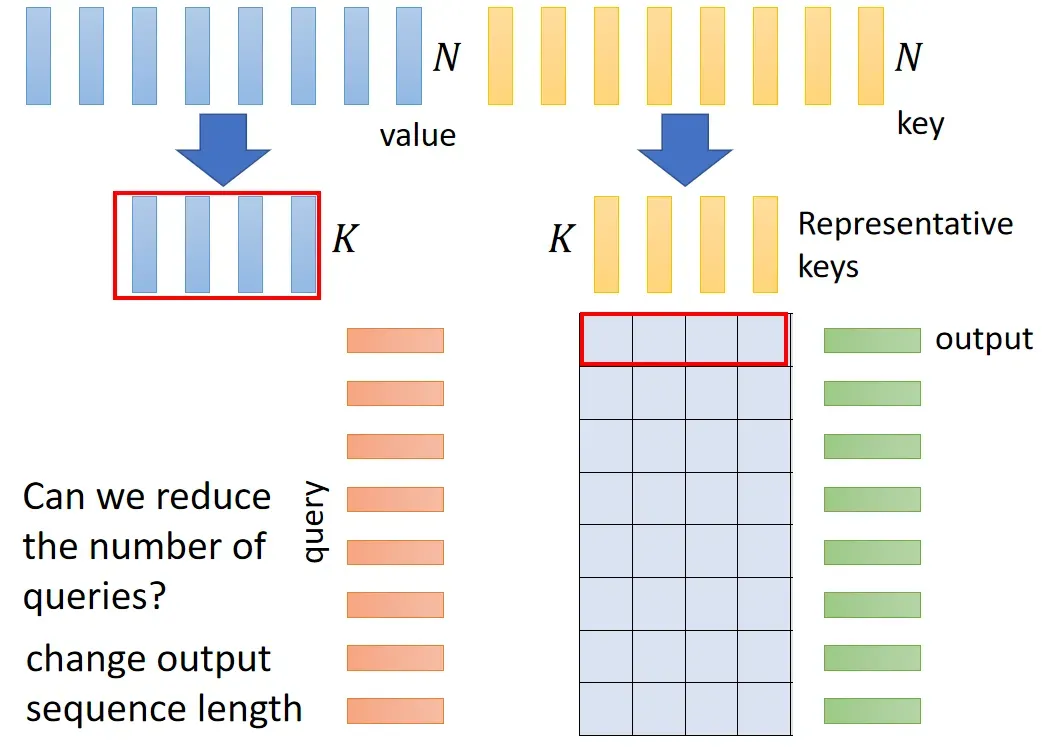
文章出处登录后可见!