一、Framework of ML
1) 给你一堆训练的资料,这些训练资料里面中包含n个x和跟它对应的ŷ,测试集是你只有x,没有ŷ。
2) 这里的好几个案例其实都是大同小异,本质上是差不多的。
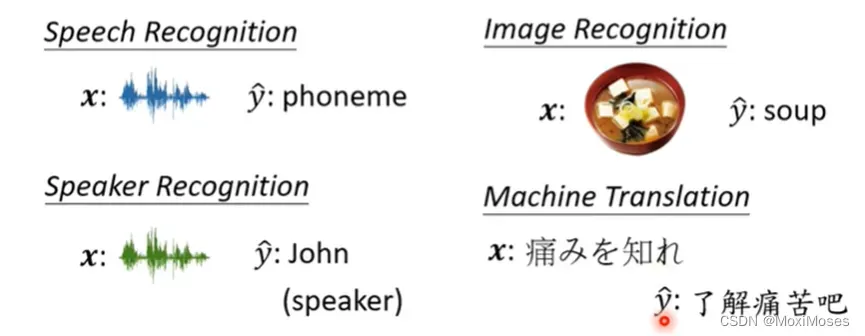
第一个是语言辨识(Speech Recognition), 但它不是一个完整的语音辨识系统。x是一小段声音讯号, ŷ是去判断它属于哪一个phoneme。
第二个是图像识别(Image Recognition),x是一张图片,ŷ是机器要去判断出图片中有什么东西。
第三个是语者识别(Speaker Recognition),x是一段声音讯号,ŷ是判断说话的人是谁。
第四个是机器翻译(Machine Translation),x是某一种语言,ŷ是翻译成另外一种语言。
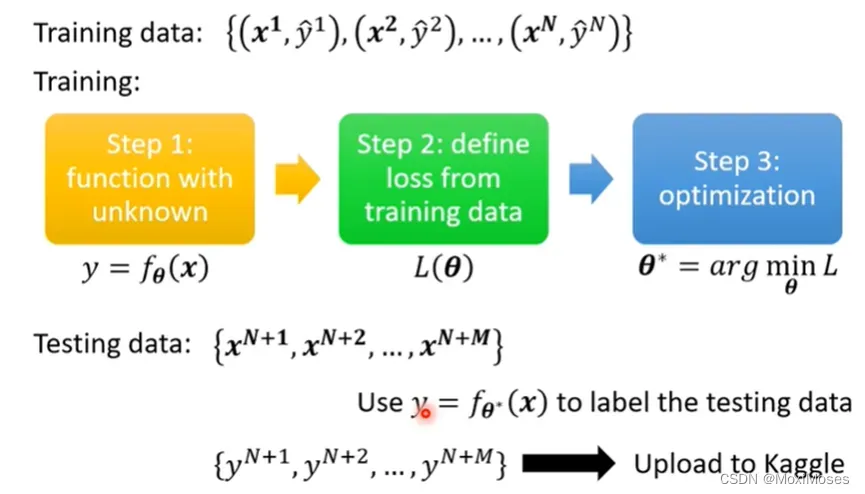
3) 我们用训练集来训练Model,总共有三个步骤。
第一步,我们需要写出一个有未知数的function, 这个未知数用θ表示,因此fθ(x)的含义是我们现在有一个function是f(x),未知数的参数是θ,输入是x,即是feature。
第二步,我们需要定义loss,loss是一个function,loss的输入是一组参数,功能是去判断这组参数好还是不好。
第三步,我们需要去找一个θ,这个θ可以使loss的值越小越好,因此我们需要去找使loss值最小的θ,我们把它叫做θ*。
我们现在把θ*代入未知参数中,输入是现在的测试资料,输出结果保存起来,然后上传到Kaggle结束。
二、General Guide
如下图所示,如果你对Kaggle上得到的结果不满意,你需要做的第一件事是检查training data的loss。我们需要先去观察model有没有在training data上学起来,再去观察testing data的结果。
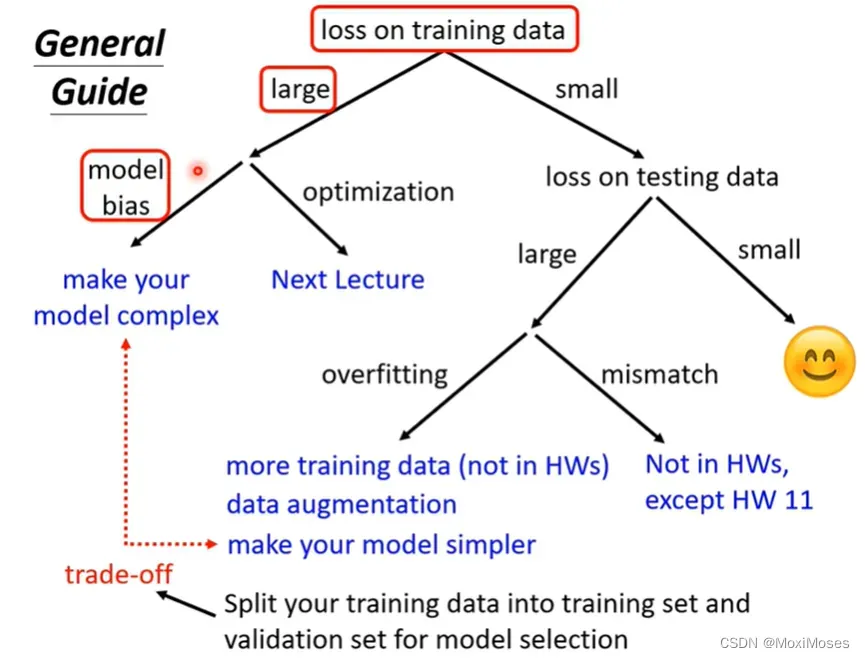
如果training date上的loss很大,说明它在训练集上没有训练好。这里的原因有两个,第一个是Model bias。
三、Model bias
1)Model bias的意思是你的model太过简单。我们现在写下一个有未知参数的function,而对于这个未知参数,我们可以代入不同的数值,代入θ1得到一个function,我们把这个function来一个点表示,代入θ2得到另一个function,我们把所有的function集合起来,得到一个function的set。但是这个function的set太小了,以至于这个function的set里面没有包含任何一个function,可以让我们的loss变低。所以说可以让loss变低的function,不在你的model可以描述的范围内。
在这种情况下,就算我们找到了一个θ*,也就是说找到了function当中最好的一个,但也无济于事。相当于大海捞针,针都不在大海里面,我们永远都捞不到针。
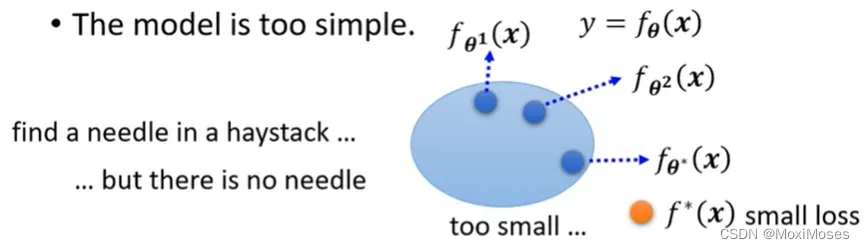
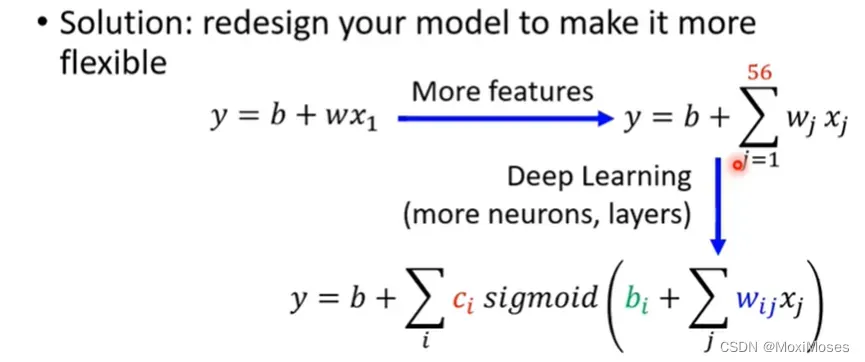
2)这个时候需要重新设计一个model,给model更大的弹性。如果model的弹性不够大,那么可以通过增加更多features,设一个更大的model,也可以用deep learning来增加model的弹性。
四、Optimization Issue
1)Gradient Descent没办法帮我们找出loss低的function,因为Gradient Descent是解一个optimization的problem,找到θ就结束了。问题是θ给我们的loss不够低,但在这一个model里面存在着某一个function,它的loss是够低的,Gradient Descent没有给我们这一个function。
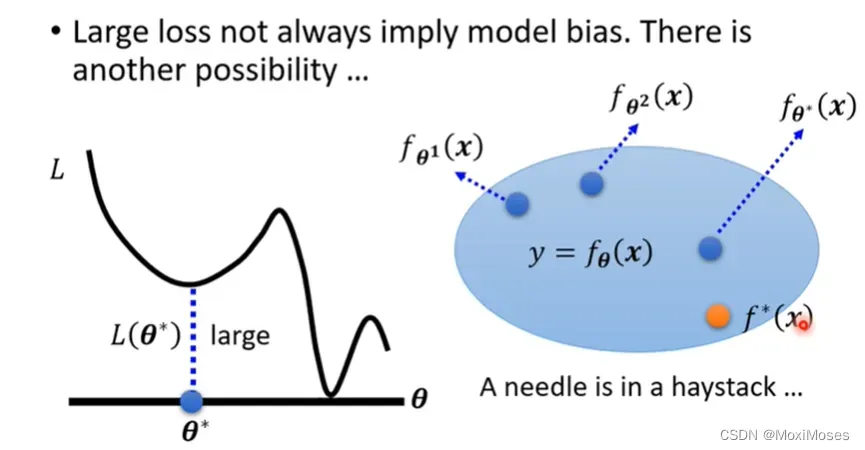
这就相当于大海捞针,针确实在海里,但是我们却捞不上来。
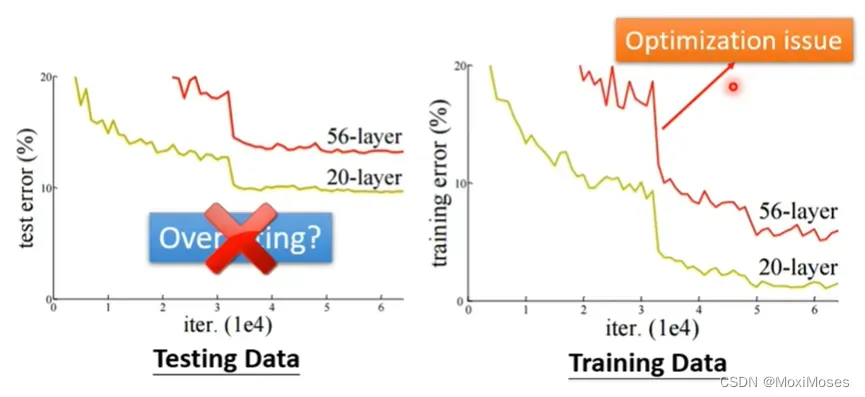
2)辨别是否是optimization issue的方法是通过比较不同的模型来得知 model 的弹性是否够大,即是查看 training data 上的 loss 值。
五、Overfitting
1)使用一个极端的例子来说明Overfitting的情况。

2)举例说明,model弹性太大的情况。
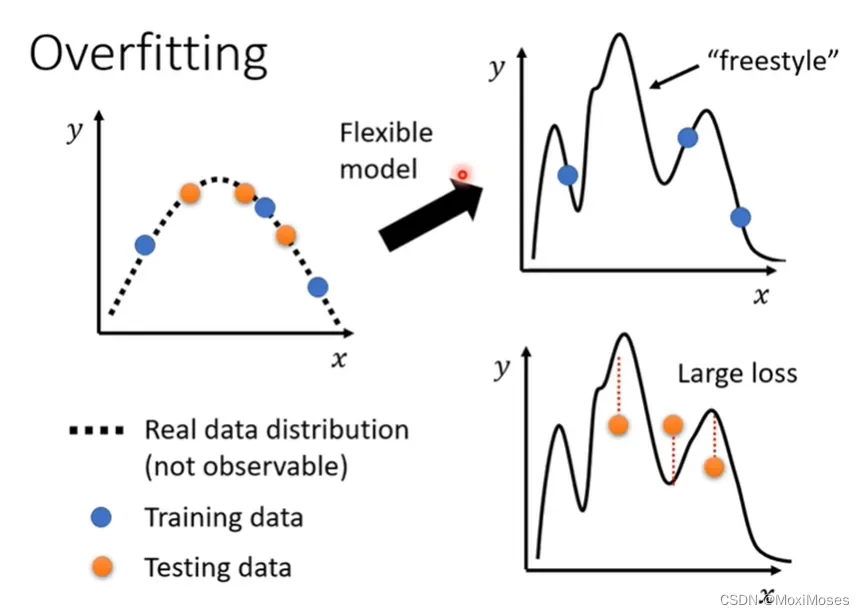
3)那现在怎么解决Overfitting的问题呢?有以下两个方向。
第一个方向是增加你的训练集(more training data),这个是最有效的方法。
通过收集更多的资料来添加数据。
Data augmentation(根据自己的理解创造出新的资料,比如做图像识别的时候,你可以将图片左右反转、放大等操作,但一定要合理处理)
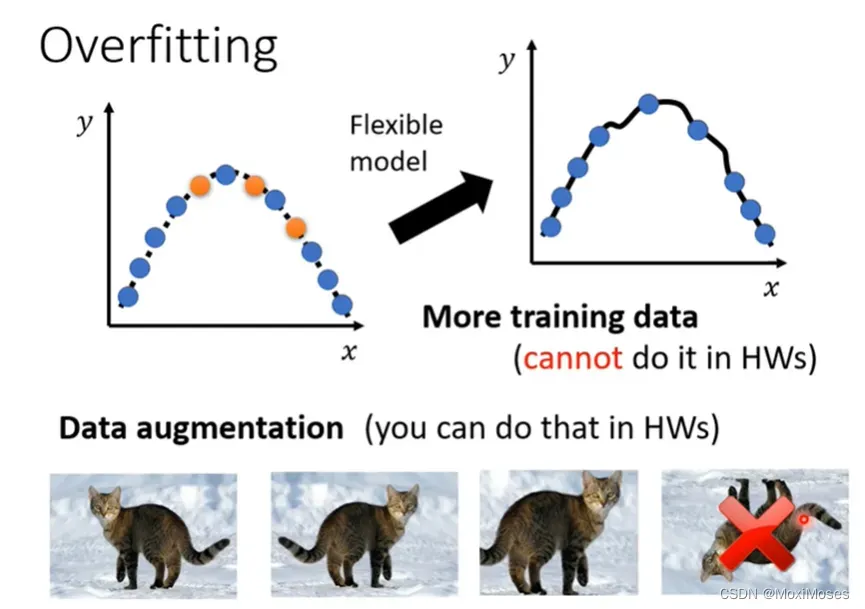
第二个方向是给你的模型一些限制,不要让它有那么大的弹性(比如限定为二次函数)。
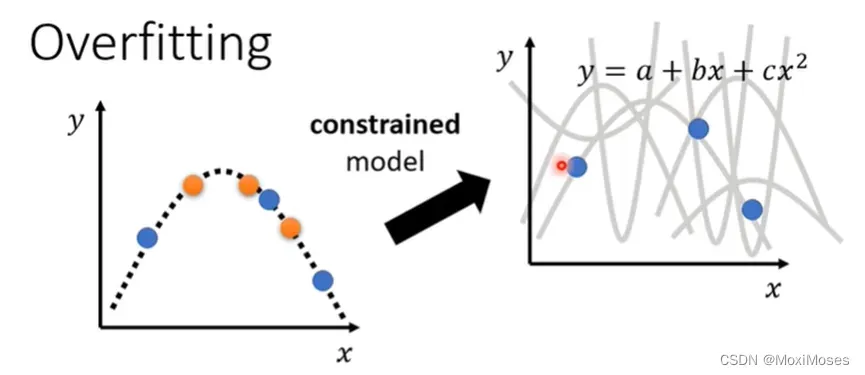
4)可以通过以下几种方法给model制造限制。
第一个是给它比较少的参数,第二个是用比较少的features,第三个是Early stopping,第四个是Dropout,这是在Deep Learning里面用来限制模型的方法。

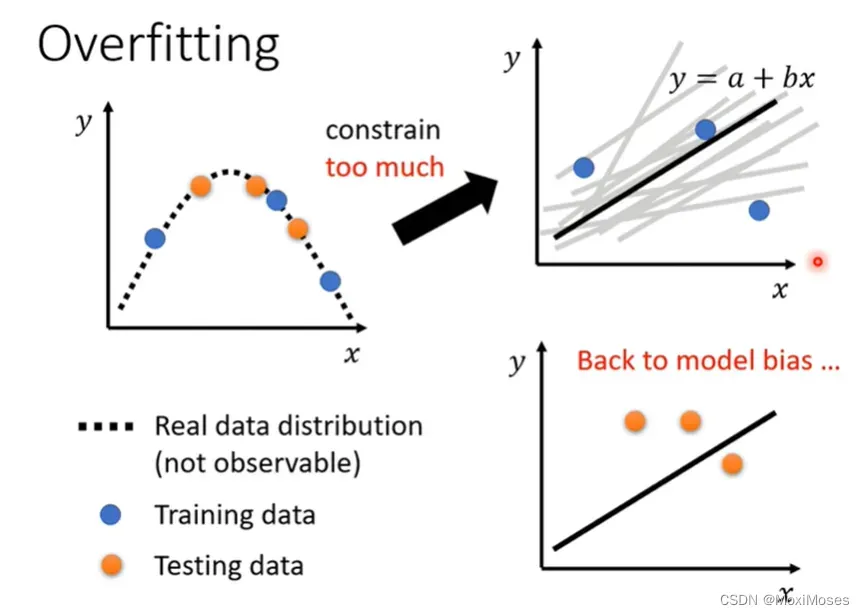
5)但是不要给过多的限制,否则就变成了model bias的问题。
六、Cross Validation
1) 我们要把Training的资料分成两部分,一部分叫做Training Set,一部分叫做Validation Set。现在我们把90%的资料放在Training Set里面,10%的资料放在Validation Set里面。我们在Training Set上训练出来的模型,在Validation Set上面去衡量它们的分数,根据Validation Set上面的分数去挑选结果,再把这个结果上传到Kaggle上面,再去看看我们得到的public的分数。
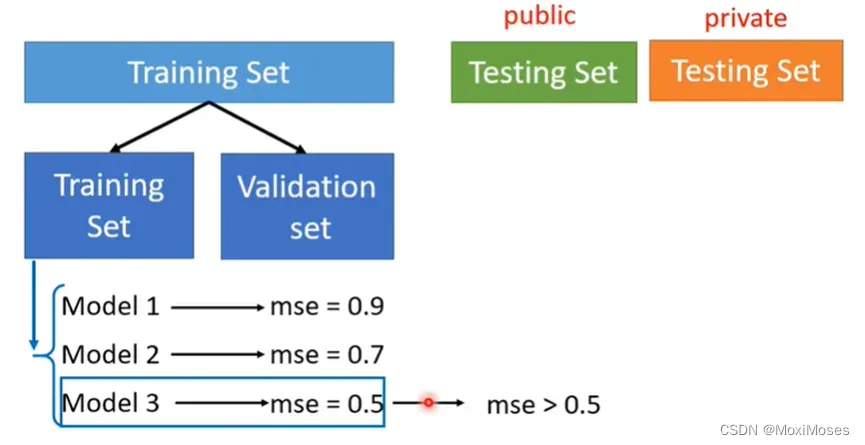
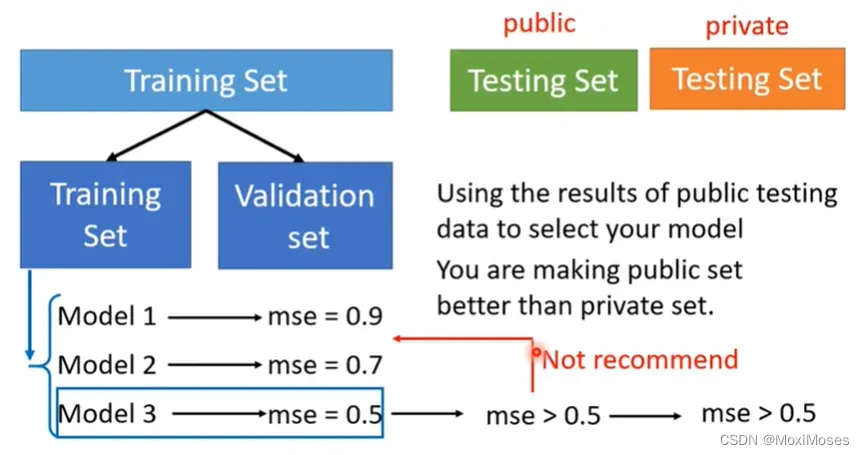
因为在挑选分数的时候,是用Validation Set来挑选的model,所以public的Testing Set的分数,就可以反应private Testing Set的分数,就比较不容易出现在public上面结果很好,但是在private上面结果很差的情况。
2) 最好的做法就是直接挑Validation loss最小的model,就是你不要去管你的public Testing Set的结果。
七、N-fold Cross Validation
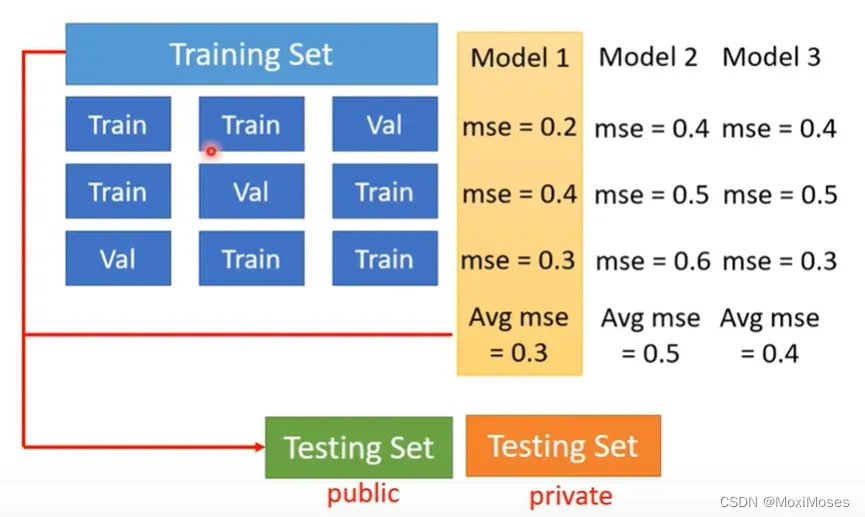
N-fold Cross Validation就是把训练集切成N等份,现在我们把训练集切成三等份,其中一份当作Validation Set,另外两份当Training Set,然后把这件事情重复三次,这样就会得到三个模型。现在不知道哪一个是好的,于是就把这三个模型放在这三个Training跟Validation的data set上面,通通跑一遍,然后把这三个模型在这三种状况的结果都平均起来,再看看谁的结果最好。
八、Mismatch
Mismatch是训练资料和测试资料的分布不一样的时候,就算增加训练资料,也没有任何帮助。

文章出处登录后可见!