最近的一篇关于YOLOv5检测小目标博客的点击量很高,没想到YOLOv5在现在还是很有影响力的。既然这样,今天本人就本着幽默、清晰、轻松的风格带大家深入了解一下YOLOv5那倾倒众生的网络结构,和它较之其他算法的改进之处。还是一句话,希望我的不经意之谈能够帮助到各位,如果感兴趣可以收藏一下,有任何问题欢迎下方评论,我会倾尽全力解答的呦!

1.YOLOv5简介
YOLOv5是一种单阶段目标检测算法,该算法在YOLOv4的基础上添加了一些新的改进思路,使其速度与精度都得到了极大的性能提升。主要的改进思路如下所示:
输入端:在模型训练阶段,提出了一些改进思路,主要包括Mosaic数据增强、自适应锚框计算、自适应图片缩放;
基准网络:融合其它检测算法中的一些新思路,主要包括:Focus结构与CSP结构;
Neck网络:目标检测网络在BackBone与最后的Head输出层之间往往会插入一些层,Yolov5中添加了FPN+PAN结构;
Head输出层:输出层的锚框机制与YOLOv4相同,主要改进的是训练时的损失函数GIOU_Loss,以及预测框筛选的DIOU_nms。
在Github上,大神已经更新了YOLOv5的6.0版本,其中主要是将SPP结构改成了串行结构,而且进过一顿的测试实验操作,证明了无论是从缠上来那个还是FLOPS等指标上均有显著的提升。
本人认为,,技术,尤其是这日新月异的人工智能领域,当然是要学习最新的技术了。(ps:最近在忙着下一篇论文,时常感觉到新技术太多了,学不过来了,时刻都在进步,所以各位要趁着年轻多学习哦!)
2.YOLOv5的网络结构(个人绘制,如有转载,还请声明,铁粉除外哈哈)
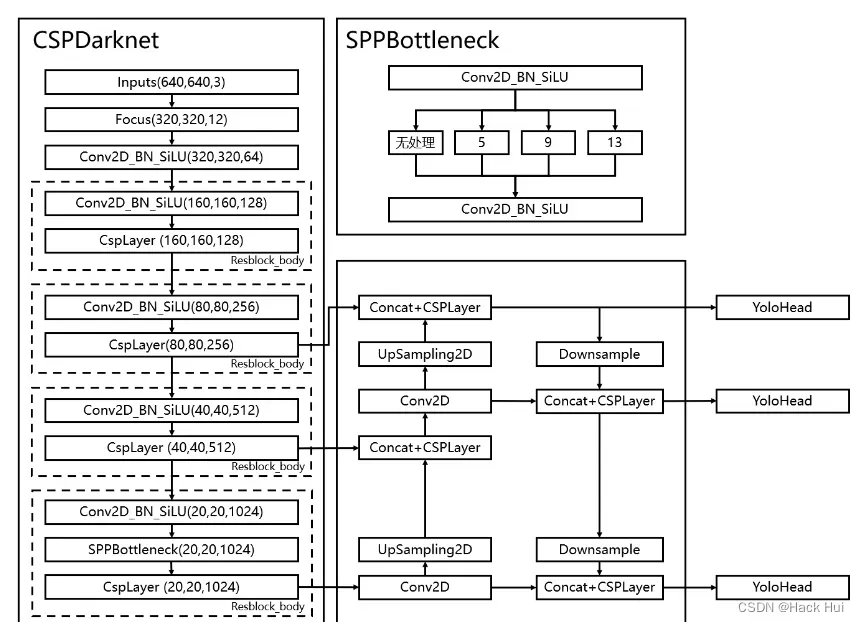
3.一些需要强调的基本细节知识(跟紧学习的脚步,马上讲完了)
YoloV5所使用的主干特征提取网络为CSPDarknet,它具有五个重要特点:
3.1、使用了残差网络Residual,CSPDarknet中的残差卷积可以分为两个部分,主干部分是一次1X1的卷积和一次3X3的卷积;残差边部分不做任何处理,直接将主干的输入与输出结合。整个YoloV5的主干部分都由残差卷积构成.
残差网络的特点是容易优化,并且能够通过增加相当的深度来提高准确率。其内部的残差块使用了跳跃连接,缓解了在深度神经网络中增加深度带来的梯度消失问题。
def Bottleneck(x, out_channels, shortcut=True, name = ""):
y = compose(
DarknetConv2D_BN_SiLU(out_channels, (1, 1), name = name + '.cv1'),
DarknetConv2D_BN_SiLU(out_channels, (3, 3), name = name + '.cv2'))(x)
if shortcut:
y = Add()([x, y])
return y
3.2、使用CSPnet网络结构,CSPnet结构并不算复杂,就是将原来的残差块的堆叠进行了一个拆分,拆成左右两部分:主干部分继续进行原来的残差块的堆叠;另一部分则像一个残差边一样,经过少量处理直接连接到最后。因此可以认为CSP中存在一个大的残差边。
def C3(x, num_filters, num_blocks, shortcut=True, expansion=0.5, name=""):
hidden_channels = int(num_filters * expansion) # hidden channels
x_1 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), name = name + '.cv1')(x)
x_2 = DarknetConv2D_BN_SiLU(hidden_channels, (1, 1), name = name + '.cv2')(x)
for i in range(num_blocks):
x_1 = Bottleneck(x_1, hidden_channels, shortcut=shortcut, name = name + '.m.' + str(i))
route = Concatenate()([x_1, x_2])
return DarknetConv2D_BN_SiLU(num_filters, (1, 1), name = name + '.cv3')(route)
3.3、使用了Focus网络结构,这个网络结构是在YoloV5里面使用到比较有趣的网络结构,具体操作是在一张图片中每隔一个像素拿到一个值,这个时候获得了四个独立的特征层,然后将四个独立的特征层进行堆叠,此时宽高信息就集中到了通道信息,输入通道扩充了四倍。拼接起来的特征层相对于原先的三通道变成了十二个通道.
class Focus(Layer):
def __init__(self):
super(Focus, self).__init__()
def compute_output_shape(self, input_shape):
return (input_shape[0], input_shape[1] // 2 if input_shape[1] != None else input_shape[1], input_shape[2] // 2 if input_shape[2] != None else input_shape[2], input_shape[3] * 4)
def call(self, x):
return tf.concat(
[x[..., ::2, ::2, :],
x[..., 1::2, ::2, :],
x[..., ::2, 1::2, :],
x[..., 1::2, 1::2, :]],
axis=-1
)
3.4、使用了SiLU激活函数,SiLU是Sigmoid和ReLU的改进版。SiLU具备无上界有下界、平滑、非单调的特性。SiLU在深层模型上的效果优于 ReLU。可以看做是平滑的ReLU激活函数。
class SiLU(Layer):
def __init__(self, **kwargs):
super(SiLU, self).__init__(**kwargs)
self.supports_masking = True
def call(self, inputs):
return inputs * K.sigmoid(inputs)
def get_config(self):
config = super(SiLU, self).get_config()
return config
def compute_output_shape(self, input_shape):
return input_shape
3.5、使用了SPP结构,通过不同池化核大小的最大池化进行特征提取,提高网络的感受野。在YoloV4中,SPP是用在FPN里面的,在YoloV5中,SPP模块被用在了主干特征提取网络中.
def SPPBottleneck(x, out_channels, name = ""):
x = DarknetConv2D_BN_SiLU(out_channels // 2, (1, 1), name = name + '.cv1')(x)
maxpool1 = MaxPooling2D(pool_size=(5, 5), strides=(1, 1), padding='same')(x)
maxpool2 = MaxPooling2D(pool_size=(9, 9), strides=(1, 1), padding='same')(x)
maxpool3 = MaxPooling2D(pool_size=(13, 13), strides=(1, 1), padding='same')(x)
x = Concatenate()([x, maxpool1, maxpool2, maxpool3])
x = DarknetConv2D_BN_SiLU(out_channels, (1, 1), name = name + '.cv2')(x)
return x
4.在小目标领域内的应用及原理
之前介绍过,可以参考我这篇文章,里面主要介绍了两种常用简单的思想以及他们代码。
(37条消息) yolov5小目标检测-提高检测小目标的检测精度_Hack Hui的博客-CSDN博客_yolov5小目标检测![]() https://blog.csdn.net/m0_58508552/article/details/124204882?spm=1001.2014.3001.5501 首先我们先明白一个事儿,啥叫小目标。人生三连问:怎么小,哪里小,为啥小。说白了啊,所谓小目标就是由于其自身的尺寸小,再加上采集的时候导致目标像素太小,一般认为20×20–40×40像素都可以认为是小目标。
https://blog.csdn.net/m0_58508552/article/details/124204882?spm=1001.2014.3001.5501 首先我们先明白一个事儿,啥叫小目标。人生三连问:怎么小,哪里小,为啥小。说白了啊,所谓小目标就是由于其自身的尺寸小,再加上采集的时候导致目标像素太小,一般认为20×20–40×40像素都可以认为是小目标。
那么咋办呢?问的好,再介绍个方法,在YOLOV5中有个锚框的定义,问题又来了,锚框是什么。所谓锚框就是网络能把目标物体圈出来的框框,这里又有两种方法。一种是在我上面链接里的文章写的自己根据自己的数据集去人为地规定好锚框大小,这需要你有耐心,一点点去改锚框尺寸大小以适应你自己的数据集。注意三个锚框从上到下分别为检测大、中、小目标的,至于为啥,一般都懂,不懂在下方评论问我吧。那么好,第二种就是在letterbox.py里面的自适应计算锚框了,他是根据遗传算法进行1000次的迭代更新找到最适合的锚框的。同样如果遗传算法也不懂,那你下方评论问我(放弃程序员吧)哈哈。
文章出处登录后可见!