1. 召回简介
谈召回离不开搜索推荐,通过用户搜索或者系统推荐获取客户想要的内容,从而提高用户的体验,提高商品转化率。当你浏览电商网站的时候是如何得到你想要的内容,搜索或者推荐,一是输入关键字通过搜索召回+排序的方式获取你想要的内容,或者是系统基于用户画像与内容画像通过算法模型推荐召回+排序的方式获取你想要的内容。
什么是召回,召回(match)就是指从全量的信息中尽可能多的获取相关的信息,召回这个词不太准确,匹配更好。比如电商的推荐召回就是根据用户画像以及商品画像进行匹配,当用户打开推荐的时候会从商品库中根据召策略获取一组与用户相关度较高的商品,商品库中存中商品数量很大,不可能把所有商品都推给用户,而是根据召回策略先匹配一部分商品,再把这部分商品排序返回给用户,既提升了排序效率又提高了用户体验。
下边这个召回排序流程图很好的反应了其工作流程及作用。
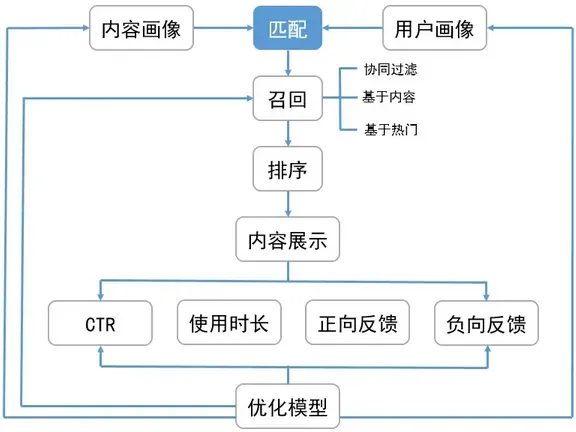
2. 召回指标
召回策略的评估主要根据两个评价指标:召回率和准确率。
召回率(Recall)= 系统检索到的相关内容 / 系统所有相关的内容总数
准确率(Precision)=系统检索到的相关内容 / 系统所有检索到的内容总数。
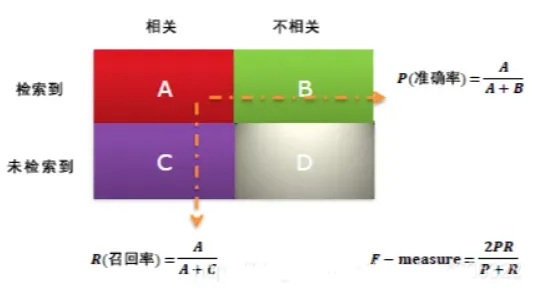
以搜索为例,系统中关于云平台的数据总共有4个,百度云,阿里云,华为云,腾讯云,权重都是1。用户通过搜索云平台得到百度云,古人云。
系统检索到的相关内容 :百度云。
系统所有相关的内容总数:百度云,阿里云,华为云,腾讯云。
系统所有检索到的内容总数:百度云,古人云。
召回率(Recall)=系统检索到的相关内容 / 系统所有相关的内容总数=1/4=25%
准确率(Precision)=系统检索到的相关内容 / 系统所有检索到的内容总数=1/2=50%
3. 召回策略
召回策略主要包含两大类,即基于内容匹配的召回和基于系统过滤的召回。
3.1 基于内容匹配的召回
内容匹配即将用户画像与内容画像进行匹配,又分为基于内容标签的匹配和基于知识的匹配。
1.基于内容标签的召回
例如,A用户的用户画像中有一条标签是“杨幂的粉丝”,那么在他看了《绣春刀2》这部杨幂主演的电影后,可以为他推荐杨幂主演的其他电影或电视剧,这就是“基于内容标签的匹配”。
2.基于知识的召回
“基于知识的匹配”则更进一步,需要系统存储一条“知识”——《绣春刀2》是《绣春刀1》的续集,这样就可以为看过《绣春刀2》的用户推荐《绣春刀1》。基于内容匹配的召回较为简单、刻板,召回率较高,但准确率较低(因为标签匹配并不一定代表真的感兴趣),比较适用于冷启动的语义环境。
3.2 基于协同过滤的召回
如果仅使用上述较简单的召回策略,推荐内容会较为单一,目前业界最常用的基于协同过滤的召回,它又分为基于用户、基于项目和基于模型的协同过滤。
1.基于用户的协同过滤(UserCF)
基于用户(User-based)的协同推荐是最基础的,它的基础假设是“相似的人会有相同的喜好”,推荐方法是,发现与用户相似的其他用户,用用户的浏览记录做相互推荐。
2.基于项目的协同过滤(ItemCF)
基于项目(Item-based)的协同过滤中的“项目”可以视场景定为信息流产品中的“内容”或者电商平台中的“商品”,其基础假设是“喜欢一个物品的用户会喜欢相似的物品”计算项目之间的相似性,再根据用户的历史偏好信息将类似的物品推荐给该用户。
3.基于模型的协同过滤(ModelCF)
基于模型的协同过滤推荐(Model-based)就是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测推荐。
总体来说,基于协同过滤的召回即建立用户和内容间的行为矩阵,依据“相似性”进行分发。这种方式准确率较高,但存在一定程度的冷启动问题。
在实际运用中,采用单一召回策略的推荐结果实际会非常粗糙,通用的解决方法是将规则打散,将上述几种召回方式中提炼到的各种细小特征赋予权重,分别打分,并计算总分值,预测CTR。
例如,根据内容匹配召回策略,用户A和内容甲的标签匹配度为0.6,同时,根据协同过滤召回策略,应该将内容甲推荐给用户A的可能性为0.7,那么就为0.6和0.7这两个数值分别赋予权重(这个权重可能会根据算法的具体情况来确定),得出总分,用它来预测用户可能点击的概率,从而决定是否返回该结果。
文章出处登录后可见!