


欢迎访问个人网络日志🌹🌹知行空间🌹🌹
论文:Old is Gold: Redefining the Adversarially Learned One-Class Classifier Training Paradigm
代码:https://github.com/xaggi/OGNet
presentation
简介
这篇是韩国科技大学在2020年CVPR上发表文章,聚焦在使用生成对抗网络做单分类如异常检测的任务,在MNIST等数据上取得了不错的效果。
以前的基于生成对抗式网络做异常检测时,都是在训练时使用生成器和对抗器,在测试推理阶段,则只使用生成器,然后计算输入数据和生成器输出之间的差异性,来评估输入数据是否是异常数据.这种方法的前提假设是网络只在正常数据上进行训练,因此不管何种数据输入生成器后,生成器的输出都更像正常数据。这种方法有个漏洞,就是在推理时使用的生成器有可能可以比较好的重建没见过的数据,简而言之就是输入是异常数据时还能比较好的恢复异常数据,这时输入和生成器的输出差异较小,导致异常检测判断失效。
一个自然的想法是同时使用生成器和判别器来做异常检测,但同时使用判别器和生成器时训练时,使用 项指标来判断何时停止训练也是一个问题,同时使用判别器和生成器训练时,可以看到模型的评估结果振荡的也比较厉害.
将判别器的作用从判断生成器的输出是否是真实数据改成评估生成器重建图像的效果对于异常检测应该 更合适,因仅使用了正常数据训练,因此对于正常数据的重建效果应该更好.根据这种想法,这篇文档的 方法为,分两阶段训练two stage,先按普通的方法训练生成器,再训练判别器,训练判别器的数据有 重建效果好的数据如real data 和 生成的正常数据,重建效果差的数据如异常数据的生成数据,异常数据增强模块输出的数据.
stage one 中的 low-epoch Generator被当作 G^{old},用于生成stage two 中的训练数据 anomaly data, 不需要特定epoch中的G,stage two中对D的训练,只需要较少的迭代即可实现,因为其已经在stage one中预训练过 了,stage two训练时会冻结G的权重。
模块介绍
(1).模型整体结构
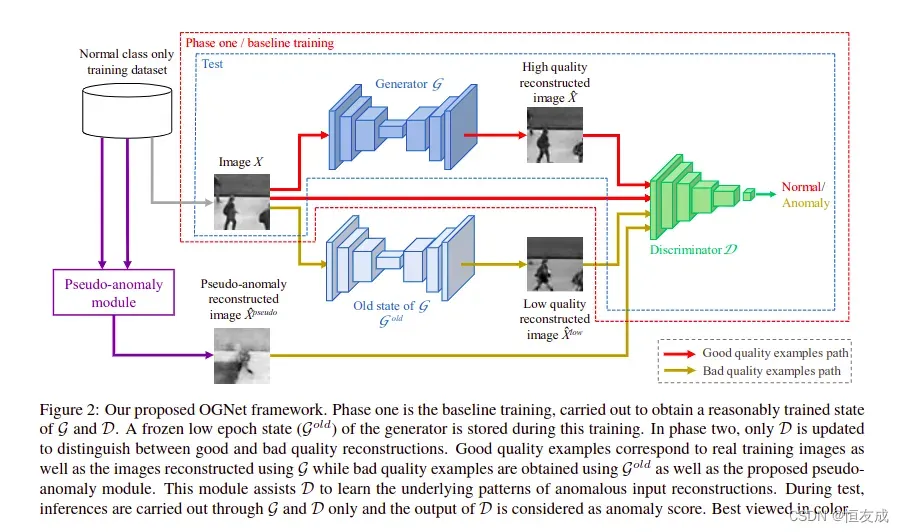

异常数据增强模块,pseudo-anomaly module,


(2).目标函数
- Phase One
phase one 是训练生成对抗网络,与生成对抗卷积网络中使用的目标函数相同,

上式中
除了上面的常规GAN的目标函数,本文中还引入了均方误差作为生成器图像重建效果Reconstruction的衡量:
综合方程(1)和(2),则Phase One使用的目标损失函数可写为:
- Phase Two
phase two冻结生成器G的参数,只更新判别器D的参数,以使判别器具备评估图像重建效果的能力。phase two训练使用的数据包括质量比较好的数据,质量比较差的数据,异常数据增强模块生成的数据。质量比较好的数据由原始输入
综上,phase two的目标函数写为:
3.模型测试
测试时对于单分类任务,使用判别器的输出
总结一下本文的工作:
- 网络架构,分两阶段训练将判别器用于衡量图像的重建效果
- 训练数据增强方法,使用
low epoch的
实验
本文原作者在Caltech-256,MNIST,USCD Ped2数据集上都做了实验,取得了SOTA的结果。在MNIST数据集上对论文进行了复现,但对论文开源的代码稍做了修改。原文中在MNIST数据集上取0这个类别作为normal class,其余每个类别取一定的数据作为anomaly class,验证效果如下图:
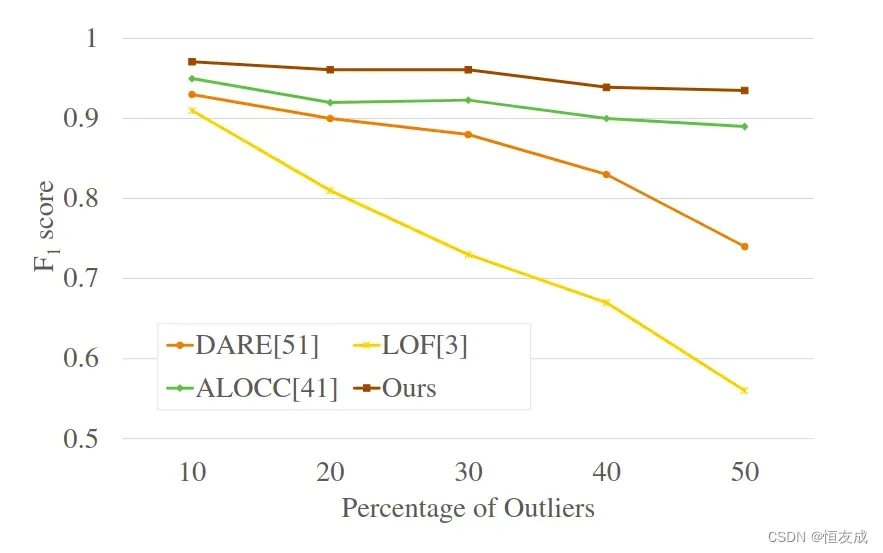

复现的结果:


源码分析
github上作者开源的代码使用的时pytroch 1.2,版本比较老了。
模型的训练使用的时model.py中的train方法
d_fake_output = self.d(g_output)
d_real_output = self.d(input)
d_fake_loss = F.binary_cross_entropy(torch.squeeze(d_fake_output), fake)
d_real_loss = F.binary_cross_entropy(torch.squeeze(d_real_output), valid)
d_sum_loss = 0.5 * (d_fake_loss + d_real_loss)
d_sum_loss.backward(retain_graph=True)
d_optim.step()
g_optim.zero_grad()
##############################################
g_recon_loss = F.mse_loss(g_output, input)
g_adversarial_loss = F.binary_cross_entropy(d_fake_output.squeeze(), valid)
g_sum_loss = (1-self.adversarial_training_factor)*g_recon_loss + self.adversarial_training_factor*g_adversarial_loss
g_sum_loss.backward()
g_optim.step()
这段代码在新版本的pytorch上会报错,因d_optim.step会更新判别器的参数,而g_sum_loss中使用了d_fake_output故g_sum_loss.backward() 时会去计算判别器参数的梯度,因判别器的参数已被更新,还使用旧的输出计算梯度。将得到错误的梯度,故将报错。
本文中GAN的实现与pytorch 给出的DCGAN示例中的实现方式有所不同
DCGAN例子中在更新生成器参数时使用的d_fake_out是基于更新后的判别器参数重新计算的,即
d_fake_output = self.d(g_output.detach()) # mutation 1
d_real_output = self.d(input)
d_fake_loss = F.binary_cross_entropy(torch.squeeze(d_fake_output), fake)
d_real_loss = F.binary_cross_entropy(torch.squeeze(d_real_output), valid)
d_sum_loss = 0.5 * (d_fake_loss + d_real_loss)
d_sum_loss.backward() # mutation 2
d_optim.step()
g_optim.zero_grad()
##############################################
d_fake_output = self.d(g_output) # mutation 3
g_recon_loss = F.mse_loss(g_output, input)
g_adversarial_loss = F.binary_cross_entropy(d_fake_output.squeeze(), valid)
g_sum_loss = (1-self.adversarial_training_factor)*g_recon_loss + self.adversarial_training_factor*g_adversarial_loss
g_sum_loss.backward()
g_optim.step()
上述代码对原作者开源的代码做了三处改动,其实这里有个疑问,更新生成器参数计算梯度时,会计算判别器的梯度,而计算的梯度并没有用来更新判别器的参数,在进行下一个iteration的训练之前又被.zero_grad的置0,这应该造成了资源的浪费。
此外,在复现论文结果时,使用的方法与原代码有所不同,原作者的方式是每个一定的epoch进行一次phase two的训练,复现中使用的是先取phase one在100个epoch训练过程中AUC最大的权重,再基于此训练phase two,取phase two中AUC最大的权重作为最终的训练结果,测试效果见上图,在单分类上只使用正常数据训练取得这样的结果,算十分不错的。
参考资料
欢迎访问个人网络日志🌹🌹知行空间🌹🌹
文章出处登录后可见!