AI-理论-吃瓜教程-基础-task2
(Datawhale37期组队学习)
1知识点
- 基本
- 线性回归
- 对数几率回归
- 线性判别分析
- 多分类学习
- 类别不平衡问题
2具体内容
2.1基本
线性模型的基本形式,学习w,b,拟合一条直线:
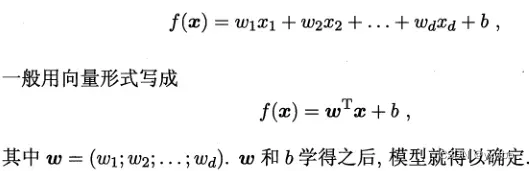
2.2线性回归
-
拟合直线尽可能准确预测输出
-
最小化fx与y差别:使均方误差最小化(回归常用性能度量)
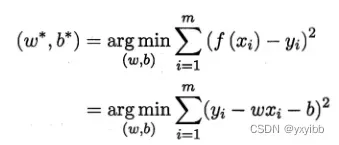
-
最小二乘法(least square method):基于均方误差最小化求解模型的方法
-
找到一条直线使得所有样本到直线的欧氏距离之和最小
-
求解w,b使E(w,b)最小化称为线性回归模型的最小二乘“参数估计”

-
求导置零得到w,b最优解的闭式解
-
-
更一般,求得列向量
,b,多元线性回归
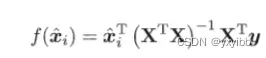
- 若
不是满秩(变量多于样本数),多个
- 若
-
若将模型预测逼近lny,对数线性回归,更一般的,考虑单调可微函数g(.),
2.3对数几率回归(分类)
- 单位阶跃函数(不连续)
- 对数几率函数-sigmoid函数(z接近0,1,在z=0处值陡变)
- 对数几率回归(logitstic regression):模型结果去逼近对数几率
,是分类方法
- 优势
- 直接对分类可能性建模,无需假设数据分布,避免假设分布不准确
- 近似概率预测,对利用概率辅助决策的任务有用
- 任意阶可导的凸函数,数值优化算法可直接求最优解
- 极大似然法估计w,b
- 确定概率质量函数(概率密度函数)
- 似然函数(对数似然函数)
- 最小化优化目标-》最大化似然函数相反数
最大化“对数似然”:
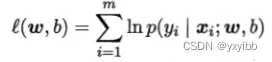
高阶可导连续凸函数,梯度下降发、牛顿法可求最优解
2.4线性判别分析(LDA)
- 线性学习方法,假设了各类样本的协方差矩阵相同且满秩
- Fisher判别分析
- 给定训练集,设法将样例投影到一条直线,使同类样例投影点尽可能接近、异类样例投影点尽可能远离(异类样本中心尽可能远,同类样本方差尽可能小)

- 当两类数据同先验、满足高斯分布且协方差相等时,LDA达到最优分类
- 可推广多分类任务

- LDA将样本投影到N-1维空间,远小于数据原有的属性数
- 监督降维
2.5多分类学习
- OvO
- OvR
- MvM-纠错输出码ECOC
2.6类别不平衡问题
分类任务重不同类别的训练样例数目差别很大
-
再缩放
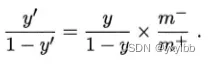
- 欠采样过多的类别用例
- 过采样过少的类别用例
- 基于原始训练集学习,预测时阈值移动加入决策
-
代价敏感学习
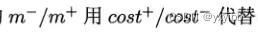
3待补充
-
正定矩阵:矩阵所有特征值都大于0
- 半正定:不小于0
- 负定:小于0
-
凸函数:
- 任意属于定义域的两个自变量x1和x2,且对于任意0 =< a <= 1,如果函数f(x)满足
- 几何意义:函数曲线上任意两点连线一定在曲线上方
- 多元函数的海塞矩阵半正定性就相当于一元函数二阶导非负性,因此凸函数的海塞矩阵一定是半正定
- 高斯泰勒展开式也可知
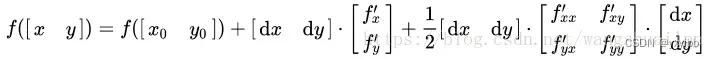
- 任意属于定义域的两个自变量x1和x2,且对于任意0 =< a <= 1,如果函数f(x)满足
-
机器学习三要素
- 模型:具体问题确定假设空间
- 策略:评价标准,确定选取最优模型的策略(loss函数)
- 算法:求loss,确定最优
-
一些公式
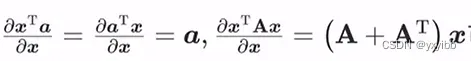
-
信息论
- 信息熵:值越大越不确定
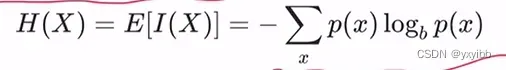
- 相对熵(KL散度):度量两个分布差异:度量理想分布p(x)和模拟分布q(x)之间差异
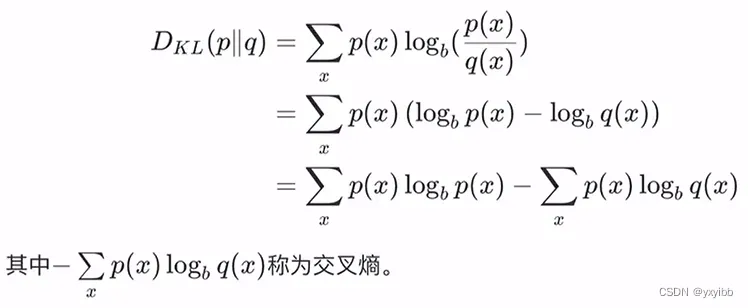
- 最优分布-》最小化相对熵-》最小化交叉熵
- 信息熵:值越大越不确定
-
对数几率回归算法的ML学习三要素
- 模型:线性模型,输出[0,1],近似阶跃的单调可微函数
- 策略:极大似然估计,信息论
- 算法:梯度下降,牛顿法
-
LDA分析

-
二范数:求模长
-
公式:
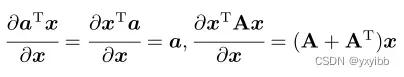 10. 广义瑞利商性质
10. 广义瑞利商性质

4Q&A
无
5code
无
6参考
- https://github.com/datawhalechina/pumpkin-book
文章出处登录后可见!
已经登录?立即刷新