#先随便创建一个具有相关性的数据集
import numpy as np
from matplotlib import pyplot as plt
from numpy import linalg
np.random.seed(2)
#构造数据集
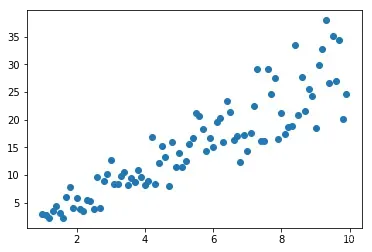
x1=[i for i in np.arange(1,10,0.1)]
x2=[np.random.uniform(2,4)*i+np.random.randn() for i in x1]
plt.scatter(x1,x2)
#zeros创建一个符合shape的随机矩阵,其实不是全0矩阵,也可能是一些随机的数字
#将数据集转化成矩阵形式
x=np.zeros((90,2))
x[:,0]=np.array(x1)
x[:,1]=np.array(x2)
x.shape
#(90, 2)
第一步中心化
#axis参数是选择计算行方向的均值还是列方向的均值
data_array=x
mean_array=np.mean(data_array,axis=0)
center_array=data_array-mean_array
#或者用subtract
center_array=np.subtract(data_array,np.mean(data_array,axis=0) )
第二步计算协方差矩阵和特征值、特征向量
#rowvar参数是选择行为一个样本还是列为样本
cov_array=np.cov(center_array,rowvar=False)
eig_vals, eig_vects = linalg.eig(cov_array)
"""
#特征值
(array([ 1.23589914, 80.95385223]),
#特征向量
array([[-0.96430755, -0.26478471],
[ 0.26478471, -0.96430755]]))
其中特征值 1.23589914对应的特征向量是array([-0.96430755,0.26478471])
"""
#这里应该选取前K个最大的特征值也就是主成分
#方便理解算法这里选取了所有特征值
#获取特征值排序的索引
val_index=np.argsort(eig_vals)
#逆序
val_index=val_index[::-1]
#选取对应的特征向量
eig_vect=eig_vects [:,val_index]
#这里选取第一个主成分矩阵
np.dot(center_array, eig_vect)[:,0]
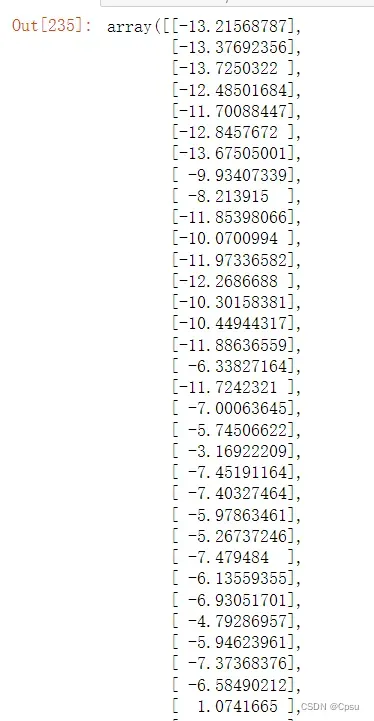
调用sklearn模块进行验证
from sklearn.decomposition import PCA
data_mat = x
pca = PCA(n_components=1)
pca.fit(data_mat)
x_p=pca.fit(data_mat).transform(data_mat)
x_p
#结果是一致的
文章出处登录后可见!
已经登录?立即刷新