一、引言
语音增强的主要目标是从含噪语音信号中提取纯净语音信号,在自动语音识别、助听器中有着 广泛的应用。深度语音增强方法可分为两大类:1) 基于映射的语音增强方法; 2) 基于掩模的语音增强方法。
二、基于映射的语音增强方法
基于映射的语音增强方法按不同的域(时域/频域)处理,可分为两大类:
1) 基于频谱映射的语音增强方法:通过神经网络学习含噪语音信号频谱到干净语音信号频谱之间的映射关系。
2) 端到端语音增强方法:通过神经网络学习含噪语音信号时域波形到干净语音信号时域波形之间的映射关系。
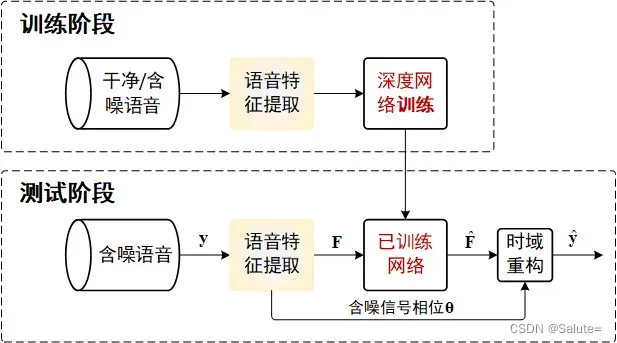
2.1 频谱映射系统模型
频谱映射系统模型如下图所示,
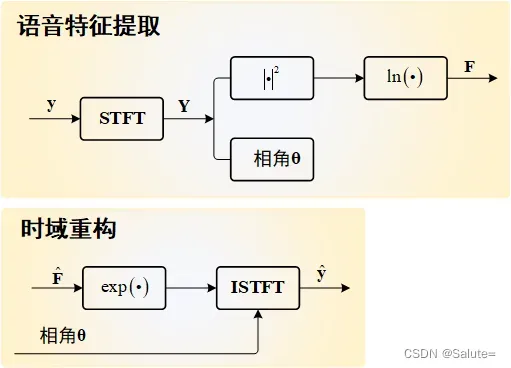
语音特征提取和时域重构具体流程如下所示,
训练阶段:
1) 输入:本文实验采用的输入特征为带噪语音信号对数幅度谱。值得注意的是,参照文献[1]采用扩帧技术,如输入5帧对数幅度谱数据时,网络输出为预测的第3帧对数幅度谱数据,如下图所示。
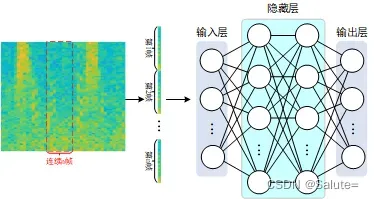
2) 标签:为干净语音信号的对数幅度谱,如当输入5帧对数幅度谱数据时,输出为预测的第3帧对数幅度谱数据。
3) 损失函数:MSE损失函数,
备注:对输入的对数幅度谱进行归一化可加速网络的收敛,且本文实验采用BN层对输入特征进行归一化。
三、实验分析
3.1 实验数据集及参数设置
训练所用干净语音信号:TIMIT-TRAIN中DR1所有干净语音信号;测试所用干净语音信号:TIMIT-TEST中DR1前10条干净语音信号;合成含噪语音信号信噪比(dB):[-5, 0, 5, 10];合成含噪语音信号所用噪声来源:NoiseX-92中的3种噪声 [‘babble’, ‘destroyerengine’, ‘factory1’] 。
参数设置:短时傅里叶变换长度:N_fft = 512, 窗长:win_length=512, 窗移:hop_length=128 , 窗函数:‘hamming’;训练相关参数epoch=30, lr=1e-4, batch_size=16。
3.1 实验结果
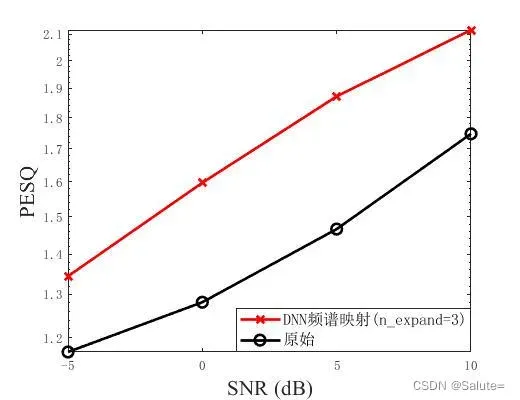
3.1.1 扩帧参数(n_expand=3)
帧扩张参数,也即输入网络的帧数为
,
时的PESQ评分和STOI值如下所示。
3.1.2 不同扩帧参数(n_expand=1, 3, 5, 7)
讨论帧扩张参数对频谱映射语音增强性能的影响:
(1) n_expand=1, 3, 5, 7时,各个snr下的PESQ值和STOI值,如下图所示。
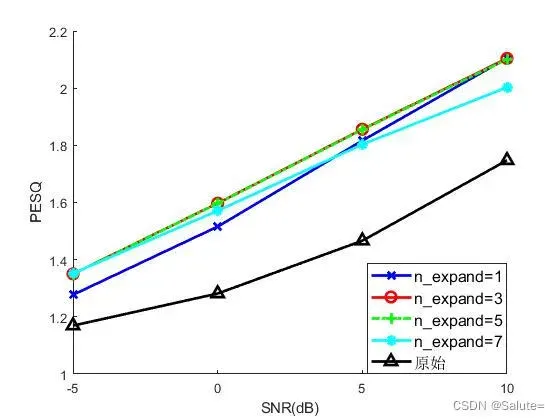
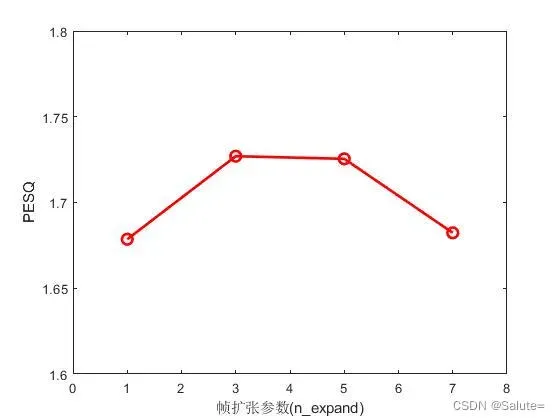
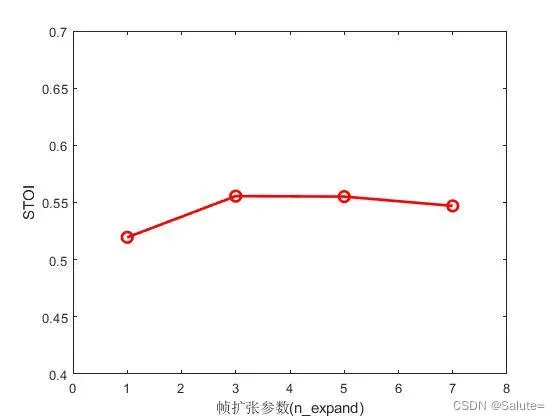
【结论:在当前实验条件下,n_expand=3的语音增强性能最佳。】
四、参考文献
[1]An Experimental Study on Speech Enhancement Based on Deep Neural Networks
[2]蓝天,彭川,李森,钱宇欣,陈聪,刘峤.基于RefineNet的端到端语音增强方法[J].自动化学报,2022,48(02):554-563.
[3]基于深度学习的单通道语音增强
[4]鲁东大学于泓老师语音增强课程
[5]参考代码
文章出处登录后可见!