系列文章目录
前言
上一篇吗博客完成了数据库的基本操作,实现了基本的登录,注册,注销功能:
这篇文章主要进度为安全的将每个模型载入到进程中
这篇文章的第二部分旨在利用基本库完成一个我们的自己的框架,并安全的将模型载入到进程中。之后将保持更新直到整个系统完善为一个智能大系统,并且保持开源(仅提供与学习,请勿用于商业利益等行为!)
github地址:传送门
一、安全
这里为什么说的是安全,我们都知道做架构,框架一定要对OS,C底层有一定的了解,这里所谓的安全指的是防止例如内存泄露,异步错误,资源未释放,僵尸进程等系统性的问题。
这里举个例子,假设我们要载入一个模型,大概分为如下几步
- 申请足够的内存
- 将模型一点一点的载入
- 关闭io并将模型保持在内存中
注意!这里的第二步和第三步是可能发生系统错误的,比如第二步的载入过程,模型的载入一般会需要几秒到十几秒根据机器性能不等,在正在写入模型的过程中,利用键盘信号停止,就会导致部分的内存泄露。第三部将模型保存在内存中,一般而言是保存在一个进程中,如果处理不当,会导致该进程变为僵尸进程,僵尸进程堆积过多直接影响系统性能。
二、方法
一般而言我们要采用信号控制的方法,python提供的siganl这样一个lib,它可以帮助我们解决这种类似的问题。
包含,如下信号等等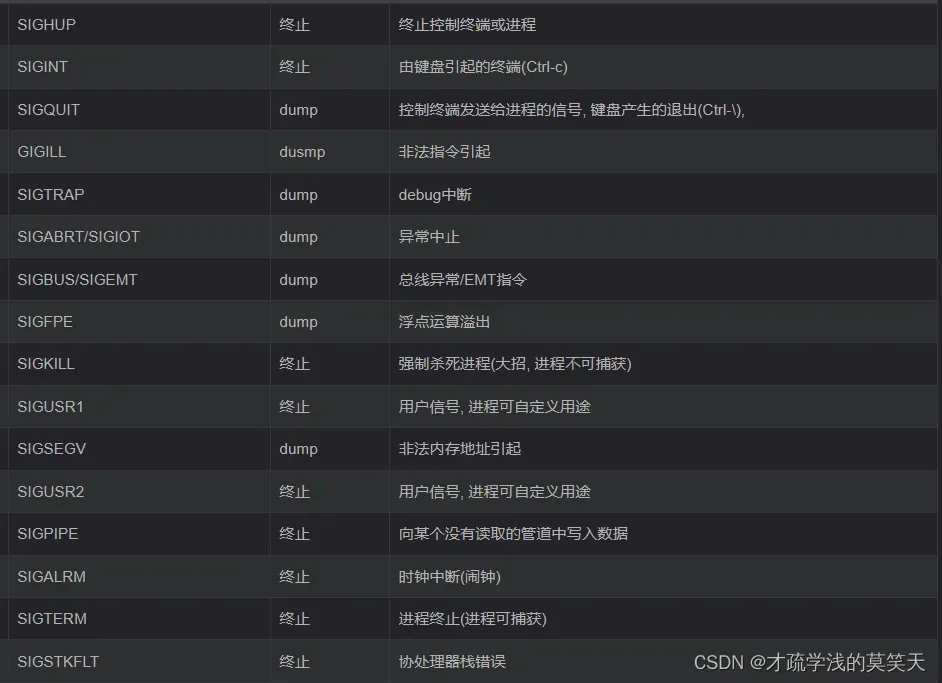
文档:传送门
实现
模型:
本人使用的是yolov5系列训练的红绿灯识别,模型,由于项目原因,模型不方便公开,大家这里根据方法调用自己的模型即可。
代码紧接上文
utils下的文件

这里主要是网络的文件,但我们的重心应该放在加载网络的方法上。
修改之前的system.yaml
postgres:
database: intersystem
user: postgres
password: root
host: localhost
port: 5432
minsize: 1
maxsize: 5
workers:
# 这里是设置模型的路径
max_workers: 1
model_path:
data: "model/data/traffic_light.names"
weights: "model/data/best_model_12.pt"
cfg: "model/data/yolov3-spp-6cls.cfg"
# 核心部分
# predefine the model
_model = None
# 这个函数的作用就是加载模型,它的事务是单纯的加载模型并返回,所以是不需要利用async去修饰的。
def load_my_model(model_path):
"""
load the torch model
:param model_path:
:return:
"""
# set the img_size 该参数用于设置传入网络的张量数据shape,好像是这样,我忘了。
img_size = 512
# load the cuda 该参数用于pytorch中的GPU使用设置
device_set = device('cuda:0')
# load the nets 这部分为加载网络结构,利用.cfg文件加载
model = Darknet(str(BASE_DIR / model_path['cfg']), img_size)
model = model_path
return model
# 该方法调用加载模型的方法并设置信号
def load_model_with_signal(model_path: str) -> None:
"""
:param model_path:
:return:
"""
# protect the ram
# 该过程为设置信号,SIG_IGN表示忽略该方法在执行期间收到的键盘信号,例如ctrl+c等,这样的话,就防止了模型在加载的过程中导致的内存泄露的问题,内存泄露在上面有说道。
signal(SIGINT, SIG_IGN)
global _model
if _model is None:
_model = load_my_model(model_path=model_path)
# 该方法是清理模型,在app关闭时,清理资源
def clean_model_with_signal() -> None:
"""
clean the model
:return:
"""
# SIG_DEL表示在接受到信号时,进行默认操作,例如ctrl+c则会进行一个进程的资源回收以及消亡。
signal(SIGINT, SIG_DFL)
global _model
_model = None
来看看更改后的utils.py,这里我直接写入了网络结构,主要是项目当前的分层还不是很好
from signal import signal, SIGINT, SIG_IGN, SIG_DFL
from system.settings import BASE_DIR
import math
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
from utils import torch_utils
from utils.parse_config import parse_model_cfg
from utils.layers import MixConv2d, Swish, Mish, FeatureConcat, WeightedFeatureFusion
ONNX_EXPORT = False
from torch import device
# predefine the model
_model = None
def load_my_model(model_path):
"""
load the torch model
:param model_path:
:return:
"""
# set the img_size
img_size = 512
# load the cuda
device_set = device('cuda:0')
# load the nets
model = Darknet(str(BASE_DIR / model_path['cfg']), img_size)
model = model_path
return model
def load_model_with_signal(model_path: str) -> None:
"""
:param model_path:
:return:
"""
# protect the ram
signal(SIGINT, SIG_IGN)
global _model
if _model is None:
_model = load_my_model(model_path=model_path)
def clean_model_with_signal() -> None:
"""
clean the model
:return:
"""
signal(SIGINT, SIG_DFL)
global _model
_model = None
def create_modules(module_defs, img_size, cfg):
"""
:param module_defs:
:param img_size:
:param cfg:
:return:
"""
# Constructs module list of layer blocks from module configuration in module_defs
img_size = [img_size] * 2 if isinstance(img_size, int) else img_size # expand if necessary
_ = module_defs.pop(0) # cfg training hyperparams (unused)
# 这里输入的通道数为3,初始化为一个列表对象,所以我全局排查了该列表对象的作用,发现这里根本没必要调用列表对象
# 因为,该参数仅在初始化中使用,列表对象内嵌套一个整形对象,是对缓存的浪费,而且调用也会费时间。一个cdg不会浪费多少,十几个cfg初始化下来
# 会影响整个类实例的速度
output_filters = [3] # input channels
module_list = nn.ModuleList()
routs = [] # list of layers which rout to deeper layers
yolo_index = -1
for i, mdef in enumerate(module_defs):
modules = nn.Sequential()
if mdef['type'] == 'convolutional':
bn = mdef['batch_normalize']
filters = mdef['filters']
k = mdef['size'] # kernel size
stride = mdef['stride'] if 'stride' in mdef else (mdef['stride_y'], mdef['stride_x'])
if isinstance(k, int): # single-size conv
modules.add_module('Conv2d', nn.Conv2d(in_channels=output_filters[-1],
out_channels=filters,
kernel_size=k,
stride=stride,
padding=k // 2 if mdef['pad'] else 0,
groups=mdef['groups'] if 'groups' in mdef else 1,
bias=not bn))
else: # multiple-size conv
modules.add_module('MixConv2d', MixConv2d(in_ch=output_filters[-1],
out_ch=filters,
k=k,
stride=stride,
bias=not bn))
if bn:
modules.add_module('BatchNorm2d', nn.BatchNorm2d(filters, momentum=0.03, eps=1E-4))
else:
routs.append(i) # detection output (goes into yolo layer)
if mdef['activation'] == 'leaky': # activation study https://github.com/ultralytics/yolov3/issues/441
modules.add_module('activation', nn.LeakyReLU(0.1, inplace=True))
elif mdef['activation'] == 'swish':
modules.add_module('activation', Swish())
elif mdef['activation'] == 'mish':
modules.add_module('activation', Mish())
elif mdef['type'] == 'BatchNorm2d':
filters = output_filters[-1]
modules = nn.BatchNorm2d(filters, momentum=0.03, eps=1E-4)
if i == 0 and filters == 3: # normalize RGB image
# imagenet mean and var https://pytorch.org/docs/stable/torchvision/models.html#classification
modules.running_mean = torch.tensor([0.485, 0.456, 0.406])
modules.running_var = torch.tensor([0.0524, 0.0502, 0.0506])
elif mdef['type'] == 'maxpool':
k = mdef['size'] # kernel size
stride = mdef['stride']
maxpool = nn.MaxPool2d(kernel_size=k, stride=stride, padding=(k - 1) // 2)
if k == 2 and stride == 1: # yolov3-tiny
modules.add_module('ZeroPad2d', nn.ZeroPad2d((0, 1, 0, 1)))
modules.add_module('MaxPool2d', maxpool)
else:
modules = maxpool
elif mdef['type'] == 'upsample':
if ONNX_EXPORT: # explicitly state size, avoid scale_factor
g = (yolo_index + 1) * 2 / 32 # gain
modules = nn.Upsample(size=tuple(int(x * g) for x in img_size)) # img_size = (320, 192)
else:
modules = nn.Upsample(scale_factor=mdef['stride'])
elif mdef['type'] == 'route': # nn.Sequential() placeholder for 'route' layer
layers = mdef['layers']
filters = sum([output_filters[l + 1 if l > 0 else l] for l in layers])
routs.extend([i + l if l < 0 else l for l in layers])
modules = FeatureConcat(layers=layers)
elif mdef['type'] == 'shortcut': # nn.Sequential() placeholder for 'shortcut' layer
layers = mdef['from']
filters = output_filters[-1]
routs.extend([i + l if l < 0 else l for l in layers])
modules = WeightedFeatureFusion(layers=layers, weight='weights_type' in mdef)
elif mdef['type'] == 'reorg3d': # yolov3-spp-pan-scale
pass
elif mdef['type'] == 'yolo':
yolo_index += 1
stride = [32, 16, 8] # P5, P4, P3 strides
if any(x in cfg for x in ['panet', 'yolov4', 'cd53']): # stride order reversed
stride = list(reversed(stride))
layers = mdef['from'] if 'from' in mdef else []
modules = YOLOLayer(anchors=mdef['anchors'][mdef['mask']], # anchor list
nc=mdef['classes'], # number of classes
img_size=img_size, # (416, 416)
yolo_index=yolo_index, # 0, 1, 2...
layers=layers, # output layers
stride=stride[yolo_index])
# Initialize preceding Conv2d() bias (https://arxiv.org/pdf/1708.02002.pdf section 3.3)
try:
j = layers[yolo_index] if 'from' in mdef else -1
# If previous layer is a dropout layer, get the one before
if module_list[j].__class__.__name__ == 'Dropout':
j -= 1
bias_ = module_list[j][0].bias # shape(255,)
bias = bias_[:modules.no * modules.na].view(modules.na, -1) # shape(3,85)
bias[:, 4] += -4.5 # obj
bias[:, 5:] += math.log(0.6 / (modules.nc - 0.99)) # cls (sigmoid(p) = 1/nc)
module_list[j][0].bias = torch.nn.Parameter(bias_, requires_grad=bias_.requires_grad)
except:
print('WARNING: smart bias initialization failure.')
elif mdef['type'] == 'dropout':
perc = float(mdef['probability'])
modules = nn.Dropout(p=perc)
else:
print('Warning: Unrecognized Layer Type: ' + mdef['type'])
# Register module list and number of output filters
module_list.append(modules)
output_filters.append(filters)
routs_binary = [False] * (i + 1)
for i in routs:
routs_binary[i] = True
return module_list, routs_binary
def get_yolo_layers(model):
"""
:param model:
:return:
"""
return [i for i, m in enumerate(model.module_list) if m.__class__.__name__ == 'YOLOLayer'] # [89, 101, 113]
class YOLOLayer(nn.Module):
def __init__(self, anchors, nc, img_size, yolo_index, layers, stride):
super(YOLOLayer, self).__init__()
self.anchors = torch.Tensor(anchors)
self.index = yolo_index # index of this layer in layers
self.layers = layers # model output layer indices
self.stride = stride # layer stride
self.nl = len(layers) # number of output layers (3)
self.na = len(anchors) # number of anchors (3)
self.nc = nc # number of classes (80)
self.no = nc + 5 # number of outputs (85)
self.nx, self.ny, self.ng = 0, 0, 0 # initialize number of x, y gridpoints
self.anchor_vec = self.anchors / self.stride
self.anchor_wh = self.anchor_vec.view(1, self.na, 1, 1, 2)
if ONNX_EXPORT:
self.training = False
self.create_grids((img_size[1] // stride, img_size[0] // stride)) # number x, y grid points
def create_grids(self, ng=(13, 13), device='cpu'):
self.nx, self.ny = ng # x and y grid size
self.ng = torch.tensor(ng, dtype=torch.float)
# build xy offsets
if not self.training:
yv, xv = torch.meshgrid([torch.arange(self.ny, device=device), torch.arange(self.nx, device=device)])
self.grid = torch.stack((xv, yv), 2).view((1, 1, self.ny, self.nx, 2)).float()
if self.anchor_vec.device != device:
self.anchor_vec = self.anchor_vec.to(device)
self.anchor_wh = self.anchor_wh.to(device)
def forward(self, p, out):
ASFF = False # https://arxiv.org/abs/1911.09516
if ASFF:
i, n = self.index, self.nl # index in layers, number of layers
p = out[self.layers[i]]
bs, _, ny, nx = p.shape # bs, 255, 13, 13
if (self.nx, self.ny) != (nx, ny):
self.create_grids((nx, ny), p.device)
# outputs and weights
# w = F.softmax(p[:, -n:], 1) # normalized weights
w = torch.sigmoid(p[:, -n:]) * (2 / n) # sigmoid weights (faster)
# w = w / w.sum(1).unsqueeze(1) # normalize across layer dimension
# weighted ASFF sum
p = out[self.layers[i]][:, :-n] * w[:, i:i + 1]
for j in range(n):
if j != i:
p += w[:, j:j + 1] * \
F.interpolate(out[self.layers[j]][:, :-n], size=[ny, nx], mode='bilinear', align_corners=False)
elif ONNX_EXPORT:
bs = 1 # batch size
else:
bs, _, ny, nx = p.shape # bs, 255, 13, 13
if (self.nx, self.ny) != (nx, ny):
self.create_grids((nx, ny), p.device)
# p.view(bs, 255, 13, 13) -- > (bs, 3, 13, 13, 85) # (bs, anchors, grid, grid, classes + xywh)
p = p.view(bs, self.na, self.no, self.ny, self.nx).permute(0, 1, 3, 4, 2).contiguous() # prediction
if self.training:
return p
elif ONNX_EXPORT:
# Avoid broadcasting for ANE operations
m = self.na * self.nx * self.ny
ng = 1. / self.ng.repeat(m, 1)
grid = self.grid.repeat(1, self.na, 1, 1, 1).view(m, 2)
anchor_wh = self.anchor_wh.repeat(1, 1, self.nx, self.ny, 1).view(m, 2) * ng
p = p.view(m, self.no)
xy = torch.sigmoid(p[:, 0:2]) + grid # x, y
wh = torch.exp(p[:, 2:4]) * anchor_wh # width, height
p_cls = torch.sigmoid(p[:, 4:5]) if self.nc == 1 else \
torch.sigmoid(p[:, 5:self.no]) * torch.sigmoid(p[:, 4:5]) # conf
return p_cls, xy * ng, wh
else: # inference
io = p.clone() # inference output
io[..., :2] = torch.sigmoid(io[..., :2]) + self.grid # xy
io[..., 2:4] = torch.exp(io[..., 2:4]) * self.anchor_wh # wh yolo method
io[..., :4] *= self.stride
torch.sigmoid_(io[..., 4:])
return io.view(bs, -1, self.no), p # view [1, 3, 13, 13, 85] as [1, 507, 85]
class Darknet(nn.Module):
# YOLOv3 object detection model
def __init__(self, cfg, img_size=(416, 416), verbose=False):
super(Darknet, self).__init__()
self.module_defs = parse_model_cfg(cfg)
self.module_list, self.routs = create_modules(self.module_defs, img_size, cfg)
self.yolo_layers = get_yolo_layers(self)
# torch_utils.initialize_weights(self)
# Darknet Header https://github.com/AlexeyAB/darknet/issues/2914#issuecomment-496675346
self.version = np.array([0, 2, 5], dtype=np.int32) # (int32) version info: major, minor, revision
self.seen = np.array([0], dtype=np.int64) # (int64) number of images seen during training
self.info(verbose) if not ONNX_EXPORT else None # print model description
def forward(self, x, augment=False, verbose=False):
if not augment:
return self.forward_once(x)
else: # Augment images (inference and test only) https://github.com/ultralytics/yolov3/issues/931
img_size = x.shape[-2:] # height, width
s = [0.83, 0.67] # scales
y = []
for i, xi in enumerate((x,
torch_utils.scale_img(x.flip(3), s[0], same_shape=False), # flip-lr and scale
torch_utils.scale_img(x, s[1], same_shape=False), # scale
)):
# cv2.imwrite('img%g.jpg' % i, 255 * xi[0].numpy().transpose((1, 2, 0))[:, :, ::-1])
y.append(self.forward_once(xi)[0])
y[1][..., :4] /= s[0] # scale
y[1][..., 0] = img_size[1] - y[1][..., 0] # flip lr
y[2][..., :4] /= s[1] # scale
# for i, yi in enumerate(y): # coco small, medium, large = < 32**2 < 96**2 <
# area = yi[..., 2:4].prod(2)[:, :, None]
# if i == 1:
# yi *= (area < 96. ** 2).float()
# elif i == 2:
# yi *= (area > 32. ** 2).float()
# y[i] = yi
y = torch.cat(y, 1)
return y, None
def forward_once(self, x, augment=False, verbose=False):
img_size = x.shape[-2:] # height, width
yolo_out, out = [], []
if verbose:
print('0', x.shape)
str = ''
# Augment images (inference and test only)
if augment: # https://github.com/ultralytics/yolov3/issues/931
nb = x.shape[0] # batch size
s = [0.83, 0.67] # scales
x = torch.cat((x,
torch_utils.scale_img(x.flip(3), s[0]), # flip-lr and scale
torch_utils.scale_img(x, s[1]), # scale
), 0)
for i, module in enumerate(self.module_list):
name = module.__class__.__name__
if name in ['WeightedFeatureFusion', 'FeatureConcat']: # sum, concat
if verbose:
l = [i - 1] + module.layers # layers
sh = [list(x.shape)] + [list(out[i].shape) for i in module.layers] # shapes
str = ' >> ' + ' + '.join(['layer %g %s' % x for x in zip(l, sh)])
x = module(x, out) # WeightedFeatureFusion(), FeatureConcat()
elif name == 'YOLOLayer':
yolo_out.append(module(x, out))
else: # run module directly, i.e. mtype = 'convolutional', 'upsample', 'maxpool', 'batchnorm2d' etc.
x = module(x)
out.append(x if self.routs[i] else [])
if verbose:
print('%g/%g %s -' % (i, len(self.module_list), name), list(x.shape), str)
str = ''
if self.training: # train
return yolo_out
elif ONNX_EXPORT: # export
x = [torch.cat(x, 0) for x in zip(*yolo_out)]
return x[0], torch.cat(x[1:3], 1) # scores, boxes: 3780x80, 3780x4
else: # inference or test
x, p = zip(*yolo_out) # inference output, training output
x = torch.cat(x, 1) # cat yolo outputs
if augment: # de-augment results
x = torch.split(x, nb, dim=0)
x[1][..., :4] /= s[0] # scale
x[1][..., 0] = img_size[1] - x[1][..., 0] # flip lr
x[2][..., :4] /= s[1] # scale
x = torch.cat(x, 1)
return x, p
def fuse(self):
# Fuse Conv2d + BatchNorm2d layers throughout model
print('Fusing layers...')
fused_list = nn.ModuleList()
for a in list(self.children())[0]:
if isinstance(a, nn.Sequential):
for i, b in enumerate(a):
if isinstance(b, nn.modules.batchnorm.BatchNorm2d):
# fuse this bn layer with the previous conv2d layer
conv = a[i - 1]
fused = torch_utils.fuse_conv_and_bn(conv, b)
a = nn.Sequential(fused, *list(a.children())[i + 1:])
break
fused_list.append(a)
self.module_list = fused_list
self.info() if not ONNX_EXPORT else None # yolov3-spp reduced from 225 to 152 layers
def info(self, verbose=False):
torch_utils.model_info(self, verbose)
将模型读入到app中
# model.py
from aiohttp import web
from asyncio import get_event_loop, gather, shield
from concurrent.futures import ProcessPoolExecutor
from utils.utils import clean_model_with_signal, load_model_with_signal
async def init_models(app: web.Application, ) -> ProcessPoolExecutor:
"""
:param app:
:return:
"""
conf = app['conf']['workers']
# get the model path
model_path = conf['model_path']
# get the num_workers
max_workers = conf['max_workers']
# set the max executors num 设置进程池最大同时工作数
executor = ProcessPoolExecutor(max_workers=max_workers)
# create the loop 创建事务循环
loop = get_event_loop()
run = loop.run_in_executor
# set the executor in runing 将方法在执行器中运行,完成了每个进程的模型读入
fs = [run(executor, load_model_with_signal, model_path) for i in range(max_workers)]
# gather可以并发运行序列中的可等待对象。
await gather(*fs)
# 该方法为关闭app后要对应的清理这些进程内的模型
async def close_executor(app: web.Application, ) -> None:
# set the cleaning model in executor
fs = [run(executor, clean_model_with_signal) for i in range(max_workers)]
# protect the fs from being cancelled
await shield(gather(*fs))
# until all events done wait=True表示直到所有的事务全部结束后,才会回收资源。
executor.shutdown(wait=True)
# on_cleanup中添加的是app关闭时应当执行的方法。
app.on_cleanup.append(close_executor)
app['executor'] = executor
# 返回执行器
return executor
修改main.py
# main.py
from aiohttp import web
from routes import setup_routes
from settings import config, BASE_DIR
from db import pg_context
from asyncio import SelectorEventLoop
from utils.model import init_models
import aiohttp_jinja2
import jinja2
async def init_app():
"""
init the app
:return:
"""
# create a app
app = web.Application()
# setup the route
setup_routes(app=app)
app['conf'] = config
aiohttp_jinja2.setup(app, loader=jinja2.FileSystemLoader(str(BASE_DIR / 'system' / 'templates')))
# link the database
app.cleanup_ctx.append(pg_context)
# init the model, make the executor to use the model
executor = await init_models(app=app)
print(app['executor'])
return app
async def get_app():
"""
return the app
:return:
"""
app = await init_app()
return app
if __name__ == '__main__':
# create loop
loop = SelectorEventLoop()
# get the app and add it to the loop
app = loop.run_until_complete(init_app(), )
# start the app service
web.run_app(app=app, loop=loop)
如上整个过程就完了,其他几个部分都是神经网路的需求文件,在这里不是重点,请移步本人的github
群聊
本人联合朋友创建了一个小白的群聊,里面包含了各种python,java开发书籍资源,需要学习的小伙伴可以通过群聊加入,需要什么书籍或者讨论问题,代码bug也可以直接找我们哈。群聊二维码在下面。欢迎读者加入。

文章出处登录后可见!