点击下载论文
无监督视觉表征学习中的动量对比
摘要
我们提出了用于无监督视觉表征学习的动量对比度(MoCo)。从对比学习(29)作为字典查找的角度来看,我们构建了一个带有队列和移动平均编码器的动态字典。这使我们能够动态地构建一个大而一致的字典,从而促进对比无监督学习。MoCo在通用的线性协议下提供具有竞争力的ImageNet分类结果。更重要的是,MoCo学习到的表征能很好的转移到下游任务中去。在PASCAL VOC, COCO和其他数据集上,MoCo在7个检测/分割任务上胜过了与之相对应的有监督学习,有时大幅超越。这表明,在许多视觉任务中,无监督和有监督的表征学习之间的差距已基本消除。
1、引言
无监督表征学习在自然语言处理中非常成功,如GPT[50,51]和BERT[12]所示。但有监督(的预训练)学习在计算机视觉中仍然占主导地位,而无监督的方法通常落后于监督学习。原因可能源于它们各自信号空间的差异。语言任务在构建标记化词典时有离散的信号空间(单词、子单词单元等),无监督学习可以基于此。相比之下,计算机视觉更关心字典的构建,因为原始信号是连续的,高维空间,并且人类之间的交流是无结构的。最近的几项研究【61、46、36、66、35、56、2】使用对比损失的相关方法在无监督视觉表征学习方面取得了有希望的结果【29】。尽管受到各种动机的驱动,这些方法可以被认为是构建动态词典。字典中的“键”(标记)从数据(例如图像或图片块)中采样,代表着一个编码器网络。无监督学习训练编码器执行字典查找:一个“查询”的编码应该和与其匹配的键一样,与其他的不一样。学习的过程被认为是最小化对比损失[29]的过程。
从这个角度来看,我们假设我们希望构建的词典是:(i)大的,(ii)在培训过程中,它们的演变是一致的。直观地说,较大的字典可以更好地对底层的连续的高维视觉空间进行采样,而字典中的键应该由相同或类似的编码器表示,以便它们与查询的比较是一致的。然而,使用已存在的对比损失的方法可能受限于两个方面中的一个(在后面讨论)。
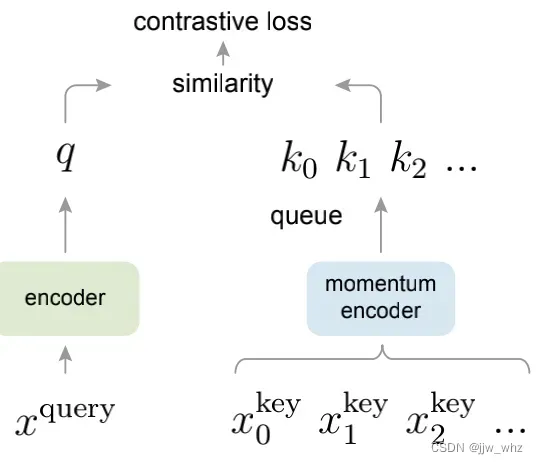
Figure 1.动量对比 (MoCo)用一个对比损失在一个键编码字典中通过匹配一个编码器查询q来训练一个视觉表征编码器。字典键{k0,k1,k2,…}由一组数据样本动态定义。将字典构建为一个队列,用当前的小批量入队,最先入队的小批量出队,将其从小批量大小中移除。键由慢处理编码器编码,由查询编码器的动量更新驱动。种方法可以创建一个大且连续的字典来学习视觉表征。
我们提出了动量对比(MoCo)作为一种构建大的和连续的字典用对比损失的无监督学习方法 (Figure 1)。我们将字典维护为数据样本队列:当前小批次的编码表征入队,最先入队的将出队。队列将字典大小从小批量大小中分离出来,允许它变大。此外,因为字典的键来自于先前的几个小批次,一个慢的处理键编码器,被实现作为一种基于动量的查询编码的移动平均,以保持连贯性。
MoCo是一种为对比学习构建动态词典的机制,可用于各种代理任务pretext(下文中也有相关解释)。在本文中,我们遵循一个简单的实例判别任务 [61, 63, 2]:来自同一图片的编码视图(比如不同的裁切块)的一个查询匹配一个键。使用这个代理任务,MoCo在ImageNet数据集上,在线性分类通用协议下表现出了竞争性的结果【11】。无监督学习的一个主要任务是预训练表征(即特征),可以通过微调转移到下游任务中。我们展示了与检测或者分割相关的7个下有任务,MoCo作为无监督预训练模型,能胜过在ImageNet上的与之对应的有监督学习的模型,有时候甚至大幅领先。在这些实验中,我们探索了在ImageNet或10亿Instagram图像集上预训练MoCo,证明MoCo可以在更真实的、10亿图片规模和相对未经处理的场景中很好地工作。这些结果表明,在许多计算机视觉任务中,MoCo在很大大的缩小了无监督和有监督表示学习之间的差距,并且可以在多个应用中替代基于ImageNet监督预训练算法。
2、相关工作
无监督/自监督学习算法通常涉及两个方面:代理任务和损失函数。术语‘pretext’意味着所解决的任务不是真正感兴趣的,真正的目的是学习一个好的数据表征。损失函数通常可以独立于代理任务进行调查。MoCo专注于损失函数部分,接下来我们讨论这两个方面的相关研究。
损失函数 定义损失函数的一种常见方法是测量模型预测值与固定目标之间的差异,例如通过L1或L2损失重建输入像素(例如,自动编码器),或通过交叉熵或基于边缘的损失将输入分类为预定义类别(例如,八个位置[13],色位[64])。如下文所述,其他替代方案也是可能的。
对比损失[29]计算表征空间中样本对的相似度,而不是用输入匹配一个固定目标。在对比损失公式中,目标可以在训练期间动态变化,并且可以根据网络计算的数据表征进行定义【29】。对比学习是最近几项关于无监督学习的核心【61、46、36、66、35、56、2】,我们将在后面的详细阐述(第3.1节)。
对抗性损失【24】衡量概率分布之间的差异。它是一种非常成功的无监督数据生成技术。在[15,16]中探讨了表征学习的对抗性方法。生成性对抗网络与噪声对比估计(NCE)【28】之间存在关系(见【24】)。
代理任务 一系列的代理任务已经被提出来了。例如:包括在某些损坏情况下恢复输入,例如去噪自动编码器【58】、上下文自动编码器【48】或跨通道自动编码器(着色化)】【64、65】。一些代理任务通过变换单个(“示例”)图像【17】、补丁排序【13、45】、跟踪【59】或分割视频中的对象【47】或聚类特征【3、4】形成伪标签。
对比学习 vs. 代理任务.许多代理任务可以基于对比损失函数的某种形式。 实例判别法【61】与基于范例的任务【17】和NCE【28】有关。在对比预测编码(CPC)[46]中的代理任务是上下文自动编码的一种形式[48],而对比多视角编码(CMC)[56]中的代理任务与色彩化有关[64]。
3、方法
3.1、作为查字典的对比学习
对比学习[29]及其最新发展可以看作是在字典查找任务中训练一个编码器,如下所述。
考虑到一个编码查询q和一组编码样本 { , …}是一个字典的键。假设在字典中有一个唯一的键(记为
)与q匹配。对比损失是一个函数,当q 与他的真键
相似且与其他的键(可以认为是与q键不相似(对立))不相似时对比损失函数的值较低。通过点积来衡量相似度,本文考虑了一种对比损失函数,称为InfoNCE[46]
其中,
是一个温度超参数。总和超过一个正样本和K个负样本。直观地说,这种损失是(K+1)维基于softmax的分类器的对数损失,该分类器试图将q分类为
。对比损失函数也可以基于其他形式[29、59、61、36],例如基于边缘的损失和NCE损失的变体。
对比损失作为一个无监督的目标函数,用于训练表示查询和键的编码器网络【29】。通常,查询表示为,其中
是编码器网络,
是待查询的样本(同样,
)。它们的实例化取决于特定的代理任务。输入
和
可以是图片[29、61、63]、图块[46]或由一组图块组成的语境[46]。网络
和
可以相同[29、59、63]、部分共享[46、36、2]或不同[56]。
3.2 动量对比
从上述角度来看,对比学习是一种在高维连续输入像图片上构建一个离散字典的方法。字典是动态的,因为键是随机采样的,在训练期间键的编码器一直在进化。我们的假设是在一个大的字典中能学到好的特征,这个大字典应该包含一组丰富的负样本,同时,字典键的编码器应该尽可能的保持连贯性,虽然它在不断的进化。基于这个动机,我们提出了动量对比,如下所述。
字典作为一个队列 我们方法的核心是将字典作为数据样本队列进行维护。这允许我们重用上一刻小批量中的编码键。队列的引入将字典大小与小批量大小分离。我们的字典大小可以远远大于典型的小批量大小,并且可以灵活地独立设置为超参数。
字典中的样本将逐步替换。当前的小批量将排入字典队列,并删除队列中最先入队的小批量。字典表示所有数据的采样子集,而维护此字典的额外计算是可以控制的。而且,删除最先的小批量也是有益的,因为他的编码键是最先过时的,而且与最新的编码键最不一致。
动量更新 使用队列会使字典变大,但也会使通过反向传播更新键编码器变得困难(梯度应该传播到队列中的所有样本)。一个简单的解决方案是从查询编码器中复制键编码器
,忽略此梯度。但是这个方法在实验中产生了很差的结果(4.1部分)。我们认为这种失败是由快速变化的编码器导致的,编码器降低了键表示的一致性。我们提出了动量更新去解决这个问题。形式上,将
的参数表示为
,
的参数表示为
,我们通过以下方式更新
:
在这里
只有参数
通过反向传播更新。在方程式2中的动量更新让
进化的比
更光滑。最终,虽然队列中的键由不同的编码器(在不同的小批量中)编码,但这些编码器之间的差异可能很小。在实验中,一个相对较大的动量(例如,m=0.999,我们的默认值)比一个较小值的动量(例如,m=0.9)工作得更好,这表明缓慢进化的键编码器是使用队列的核心。
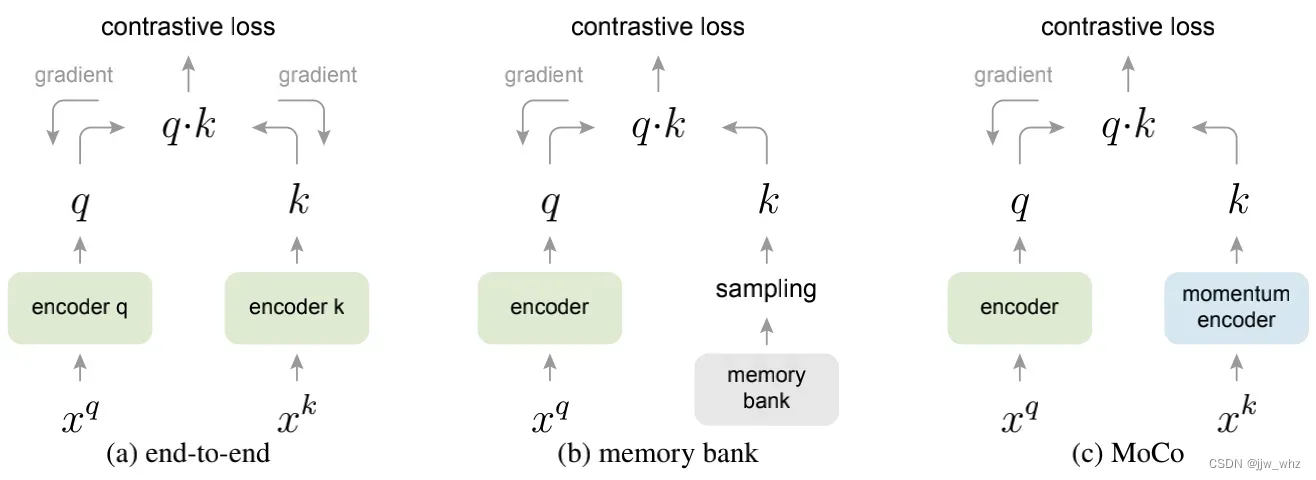
与以前的机制的关系 MoCo是用在对比损失上的一个常规机制。我们用两个已存在的常规机制和MoCo作对比,结果在Figure 2上。它们在字典大小和一致性方面表现出不同的特性。
通过反向传播进行端到端的更新是一种很自然的机制(例如,[29、46、36、63、2、35],图2a)。在当前的小批量中采样构成字典,因此键的编码是一致的(由相同的编码器参数集构成)。但字典大小与小批量大小相结合,受到GPU内存大小的限制。它还面临着大的小批量优化的挑战[25]。最近的一些方法[46,36,2]是基于局部位置驱动的代理任务,其中字典大小能通过多个位置做的更大,但这些代理任务可能需要特殊的网络设计,如修补输入[46]或定制感受野大小[2],这可能会使这些网络向下游任务的传输变得复杂。
另一个机制是在[61]中提出来的memory bank方法(Figure 2b)。一个memory bank由数据集中所有样本的表征组成。每个小批量的字典都是从memory bank中随机采样的,没有反向传播,因此它可以支持较大的字典。然而,在memory bank中的一个样本的表征当他被最后一次看到时已经被更新过了。因此采样的键基本上是关于过去每个epoch中多个不同步骤的编码器,因此不太一致。一个动量更新采用的是[61]中的memory bank。动量是在相同样本的表征上更新的而不是在编码器上。这个动量更新与我们的方法无关,因为MoCo并没有跟踪每个样本。此外,我们的方法具有更高的内存效率,并且可以在十亿规模的数据上进行训练,这对于memory bank来说是很困难的。
第四部分比较了这三种机制。
3.3、代理任务
对比学习可以驱动各种代理任务。本文的关注重点不是设计一个新的代理任务,所以我们使用了一个简单的代理任务,主要遵循了在[61]中的实例判别任务,和这些[63, 2]最近的工作相关。
根据[61],我们认为一个查询和一个键如果来自同一个图片则这个查询和键为一个正对,否则的话是负样本对。根据[63, 2],在随机数据增强下,我们在同一幅图像中随机取两个“图”,形成一正图对。查询和键是分别被他们的编码器和
编码。编码器可以是任何的卷积神经网络[39]。
Algorithm 1 MoCo的伪代码用pytorch实现

Algorithm 1提供了MoCo中的关于代理任务的伪代码。对于当前的小批量,我们对查询及其对应的键进行编码,从而形成正样本对。负样本来自队列。
技术细节 我们采用ResNet[33]作为编码器,其最后一个全连接层(在全局平均池化层之后)具有固定的维输出(128-D[61])。该输出向量通过L2范数进行归一化[61]。这是查询或者键的表征。在Eqn.(1)中的温度设置为 0.07[61]。数据增强的设置遵循 [61]:从随机的一张已调整大小的图片中裁切一个224×224的像素块,然后进行随机颜色抖动、随机水平翻转和随机灰度转换,所有这些都可以在PyTorch的torchvision软件包中获得。
打乱批量归一化 我们的编码器和
都有批量归一化 (BN),这和标准的ResNet一样[33]。在实验中,我们发现使用BN会阻止模型学习好的表征,正如[35]中所述(避免使用BN)。模型似乎“欺骗”了代理任务,很容易找到低损失的解决方案。这可能是因为同一批次样本之间的信息交流(由BN造成的),导致了信息的泄露。
我们通过打乱BN来解决这个问题。我们使用多个GPU进行训练,在每个GPU的样本上执行BN(和常规做法一样)。对于键编码器,我们先在当前小批量中打乱样本顺序,然后再将其分配给GPU(在编码后打乱);对于查询编码器中的小批量样本顺序没有改变。这确保了用于计算查询及其正键的批次统计信息来自两个不同的子集。这有效地解决了欺骗问题,并使训练从BN中受益。
我们在我们的方法和它的端到端消融试验的方法中都使用了打乱BN (Figure 2a)。与memory bank中的对应方法无关(图2b),它不受此问题的影响,因为正键在过去是来自不同的小批量。
4、实验
我们研究的无监督训练是在下边几个数据集上执行的:
ImageNet-1M (IN-1M): 这是imageNet训练数据集,这个数据集包含大约有128万个图片,1000个类别(通常称为 ImageNet-1K,我们计算图像数量,因为类不会被无监督学习利用)。该数据集的类分布非常均衡,其图像通常包含对象的图标。
Instagram-1B (IG-1B): 根据 [44],这个数据集大约有10亿(9亿4000万个)个来自 Instagram的公开图片,图片大约有1500个类别这和ImageNet的类别有关。与IN-1M数据集相比,该数据集相对来说没有固化,并且拥有真实世界数据的分布长尾性和不平衡性。这个数据集即包含了物体的图标和场景等级图片。
训练:我们用SGD作为我们的优化器,SGD的权重衰退是 0.0001,动量为0.9。在IN-1M数据集上,我们在8个GPU,用的小批量大小为256(N在Algorithm 1),0.03的初始学习率。我们总共训练了200个epochs,在第120和160个epochs时让学习率乘以0.1, 用ResNet-50训练了大约53个小时。对于IG-1B数据集,我们用了64个GPU,小批量大小为1024,学习率为0.12并且学习率是指数衰减每62.5k个迭代后学习率乘以0.9,我们用ResNet-50训练了125万个迭代花了大约6天。
4.1、线性分类协议
我们按照一个通用协议,在冻结特征上通过线性分类来验证我们的方法。在本小节中,我们在In-1M上执行无监督的预训练。然后冻结特征训练一个有监督的线性分类器(softmax后接一个全连接层)。我们用 ResNet的全局平均池化特性训练这个分类器,训练了100个epoch。我们在 ImageNet验证数据集上做了 1-crop, top-1分类精度的报告。
对于这个分类器,我们执行了一个网格搜索,发现最好的初始化学习率为30,权重衰减是0(和 [56]中的报告相似)。这些超参数在本小节中介绍的所有消融条目中都表现很好。这些超参数值意味着特征分布(例如,大小)可能与在ImageNet上进行的有监督训练的分布有很大不同,我们将在4.2中重新讨论这个问题。
消融:对比损失机制。在图二中我们比较了三种机制。为了关注对比损失机制的效果,我们实现了所有的这些机制,用相同的代理任务,如3.3部分描述的那样。我们还使用了与InfoNCE格式相同的对比损失函数 Eqn.(1)。因此,仅就这三种机制进行比较。
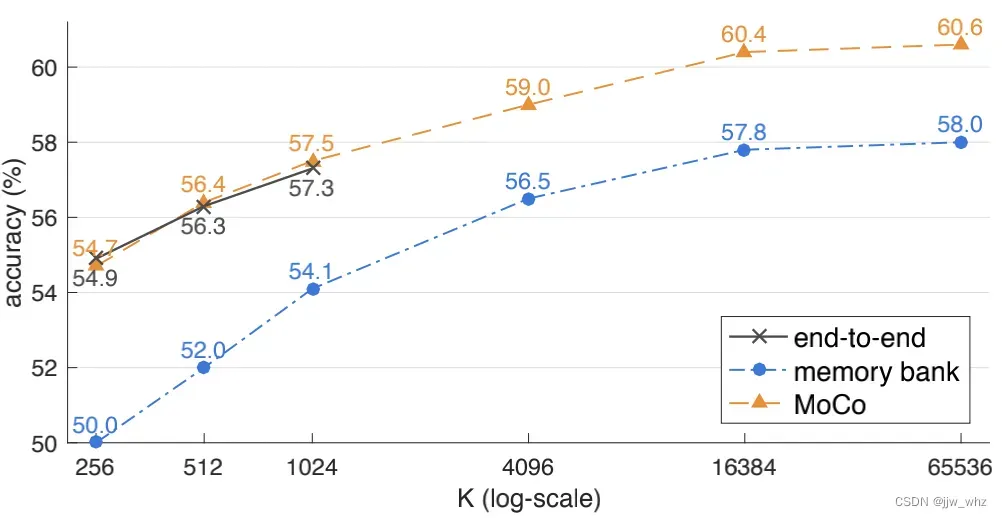
在 Figure 3中的为结果。总的来说:这三种机制都受益于更大的K。在memory bank机制下,在[61, 56]观察到了一个相似的趋势。在这里我们展示的一种趋势更普遍,能在所有的机制中被看到。这些结果让我们有个构建大字典的动机。
当K很小时,端到端机制的性能和MoCo类似。然而,由于端到端的要求,字典大小受到小批量大小的限制。在这里,一台高端机器(8 Volta 32GB GPU)能承受的最大小批量是1024。更重要的是,大的小批量训练是一个公开的问题:我们发现有必要在这里使用线性学习率缩放规则[25],没有该规则,准确率会下降(大约2%(1024小批量)。但是,用一个更大的小批量进行优化是更困难的,即使内存充足,这种趋势是否可以外推到更大的K值也是值得怀疑的。
memory bank [61]机制支持一个更大的字典。但是它的结果比MoCo低了2.6%。这符合我们的假设: memory bank中的键是来自过去各个epoch的不同的编码器,它们不是连续的。注意,58.0%的 memory bank结果反映了我们改进了[61]的实现。
消融:动量.
下边的表格显示的是,在预训练中不同MoCo动量值(在Eqn.(2)中为m)情况下ResNet-50的精度(这里K=4096):
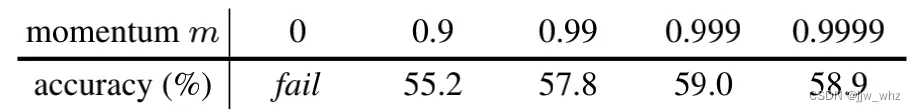
和以前结果的对比.与以前的无监督学习方法在模型大小上可能存在很大差异。为了进行公平和全面的比较,我们做了精度和参数之间的权衡的一个报告。除了 ResNet-50(R50),我们按照 [38]也做了他的变种–2倍、4倍宽(即更多的通道) 。我们设置K = 65536,m = 0.999。Table 1是对比结果。 MoCo使用R50表现的相当具有竞争力,达到了60.6%的精度,比其他所有参与比较的相同模型大小(大约2400万)的模型都好。MoCo用 R50w4×在大模型上达到了 68.6%的精度。值得注意的是,我们使用标准的ResNet-50实现了有竞争力的结果,并且不需要特定的架构设计。例如,修补输入[46,35],精心定制的感受野[2],或组合两个网络[56]。通过使用没有特定代理任务的架构,可以更容易地将特征转移到各种视觉任务中,并进行比较,这将在下一小节中进行研究。
本文的重点是关注的是普通对比学习的机制;我们不探索可能进一步提高准确性的正交因素(例如特定的借口任务)。如例子 “MoCo v2” [8],这个手稿的初级版本的一个拓展,在数据增强和输出投影头上做了微小的改变,使用 R50达到了71.1%的精度(以前是 60.6%)。我们认为,这一额外的结果显示了MoCo框架的通用性和健壮性
4.2、特征转换
无监督学习的主要目标是学习可转移的特征。当作为下游任务微调的初始化时,ImageNet有监督的预训练最具影响力。接下来,我们将比较MoCo和有监督预训练的ImageNet,转换到多个任务中包括 PASCAL VOC [18], COCO [42],等。作为先决条件,我们讨论了涉及的两个重要问题【31】:归一化和调度。
归一化正如4.1部分所述,与ImageNet监督预训练相比,无监督预训练产生的特征可能具有不同的分布。但是一个下游任务经常会为有监督预训练选择超参数(比如:学习率)。为了解决这个问题,我们在微调期间采用了特征归一化:我们使用经过训练的BN进行微调(跨GPU同步[49]),而不是通过仿射层将其冻结[33]。我们还在新初始化的层中使用BN(例如,FPN[41]),这有助于校准等级。
我们在微调有监督和无监督的预训练模型时执行归一化。MoCo使用与ImageNet有监督相对应的相同的超参数。
调度 如果微调调度足够长,则来自训练检测器的随机初始化参数可能具有很强的基线,能在CoCo上匹配与在ImageNet上相对应的有监督模型。我们的目标是研究特征的可转移性,因此我们的实验是在受控的调度上进行的,例如,1倍或者2倍调度在CoCo上,与 [31]中的6倍或者9倍对比。在VOC等较小的数据集上,进行更长时间的训练可能赶不上 [31]。
尽管在我们的微调中,MoCo使用与ImageNet有监督对应的模型的相同的调度,并提供随机初始化结果作为参考。
总的来说,我们的微调使用与有监督的预训练相同的设置。这可能会使MoCo处于不利地位。即便如此,MoCo仍具有竞争力。这样做还可以在多个数据集/任务上进行比较,而无需额外的超参数搜索。
4.2.1、PASCAL VOC 物体检测。
设置 检测器是以f R50-dilated-C5 或者 R50-C4(细节看附录)为主干,使用BN微调的 Faster R-CNN,实现在 [60]中。我们微调了所有的端到端层。在训练期间的图片比例在 [480, 800]像素之间。推理是800像素。所有的模型设置都一样,包括有监督的预训练模型。我们默认在VOC上使用进行评估,(即IoU阈值为50%),更严格的是使用AP和
的CoCo-style进行度量。在VOC test2007上进行评估。
消融:骨架 Table 2展示了在trainval07+12(大约1万6500张图片)上微调的结果。对于R50-dilatedC5 (Table 2a)。在 IN-1M上 MoCo 的预训练结果和有监督预训练的模型的结果旗鼓相当。在IG-1B上则MoCo超过了有监督的模型。对于 R50-C4 (Table 2b)。MoCo在 IN-1M 或者 IG-1B上是比有监督模型要好。达到+0.9 AP50, +3.7 AP, 和 +4.9 AP75。
有意思的是:迁移精度取决于检测器结构。对于C4的骨架,默认是用已存在的基于ResNet的结果 [14, 61, 26, 66]。无监督预训练的优势是更大。预训练与检测器架构之间的关系过去一直被掩盖,应该是一个考虑因素。
消融:对比损失机制这些结果是部分的,因为我们为对比学习建立了坚实的检测基准。为了指出在对比学习中使用MoCo机制所带来的收益, 我们使用与MoCo相同的微调设置,对使用端到端或memory bank机制预训练模型进行微调,这两种机制我们都实现了(即图3显示了最好的)。
这些比赛者的表现的也不错,他们的带有C4骨架的AP和也高于ImageNet有监督的相对应的模型Table 2b,但是其他指标更低,他们在所有的指标中都低于MoCo。这显示了MoCo的优越性。除此之外,在大数据集上如何去训练这些竞争者的模型也是一个公开的问题。他们可能不能在IG-1B数据集上取得好结果。

和以前结果对比根据竞争者使用的数据集,我们在 trainval2007(大约有5千张图片)使用 C4作为骨架进行微调,在Table 4中进行了对比。
对于 的指标,之前的任何方法都赶不上其各自的有监督训练的模型。MoCo在 IN-1M, IN-14M (full ImageNet), YFCC-100M [55], 和 IG-1B数据集上的任何一个预训练的结果都要比有监督的好。在更严格的数据集中能看到大的进步。达到了 +5.2 AP and +9.0
这些进步是比在trainval07+12上的更大。
4.2.2、CoCo物体检测和分割
设置: 模型是具有 FPN或者 C4骨架,用BN作微调的 Mask R-CNN,在 [60]中实现了。在训练期间图片被缩放到了[640, 800]像素。推理图片是800像素。我们微调了所有端到端的层。我们在 train2017数据集(大约11.8万张图片)上进行了微调,评估在数据集val2017上。调度是默认在 [22].中的1倍或者两倍。
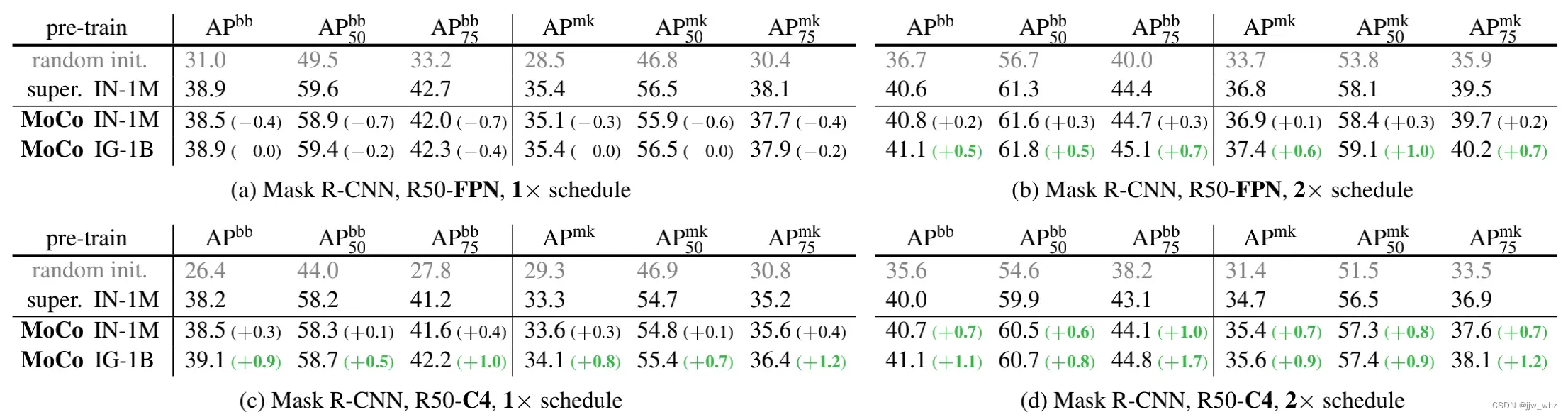
结果: Table 5显示的是在CoCo数据集上用FPN(Table 5a, b)和 C4 (Table 5c, d)作为骨架的结果。用1倍的调度算法。所有模型(包括ImageNet有监督的相对应的模型)都严重缺乏训练,这可以从与2×调度的情况下有大约2点差距中看出。在2x调度下,MoCo在两个骨架下,在所有的指标中都比ImageNet监督模型要好。
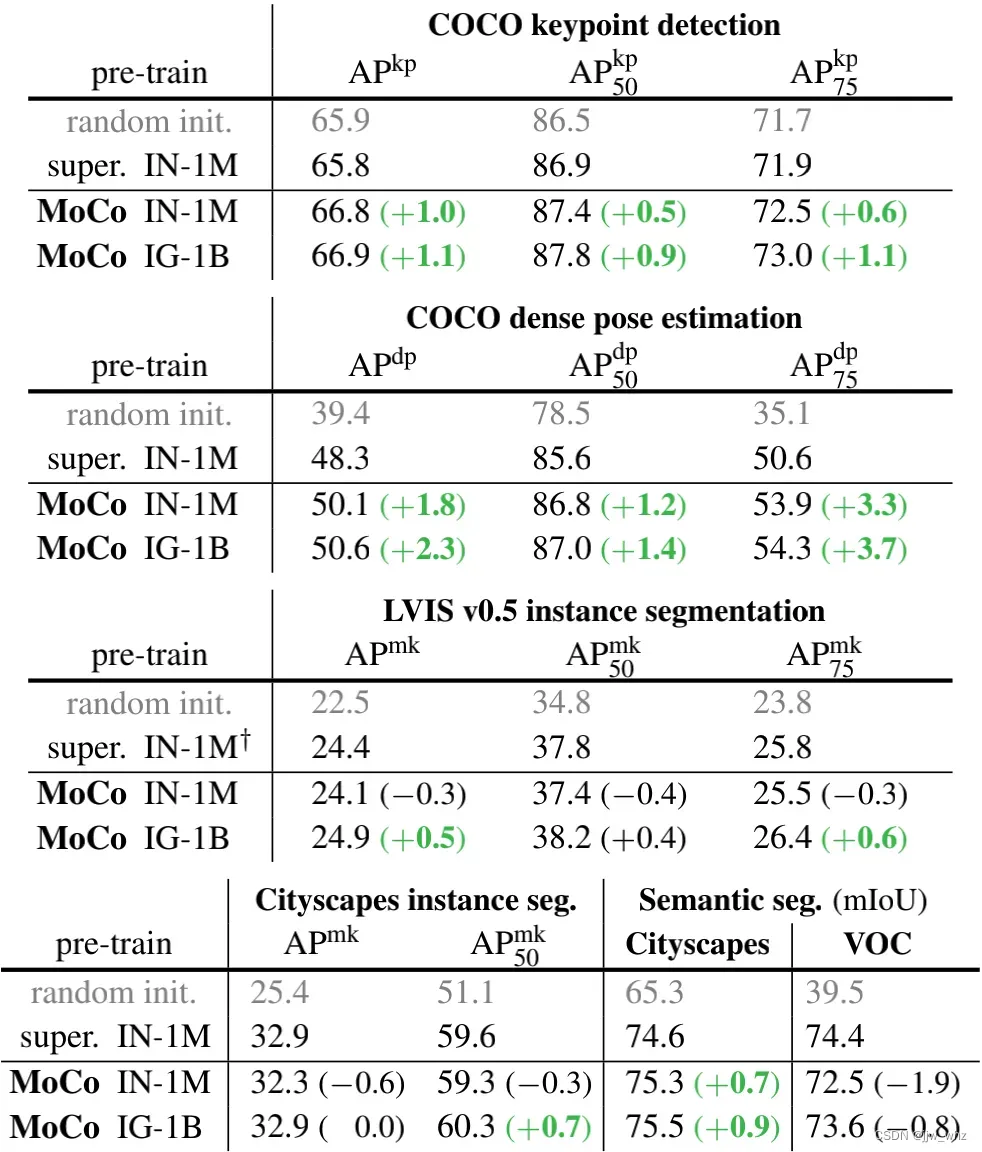
4.2.3 更多的下游任务
Table 6展示了更多的下游任务(在附录中有实现细节)。总的来说, MoCo 与 ImageNet上的有监督预训练模型相比,MoCo 表现出了竞争力。
COCO关键点检测:有监督预训练在随机初始化上毫无优势,然而MoCo在所有标准上都胜出了。
COCO密集姿态估计 [1]:MoCo大大优于有监督预训练。例如:在上高出了3.7个点,在高度局部敏感任务中。
LVIS v0.5实例分割:这个任务大约有1000个长尾分布类别。特别的,在以 ImageNet有监督为基线的LVIS,我们发现用冻结的 BN(24.4 )做微调要比可调的BN(细节在附录中)要好。因此我们在这次任务中比较了 MoCo和较好的有监督预训练模型的变化。MoCo在IG-1B上在所有的指标上都胜出了。
城市景观实例分割[10]:MoCo 在 IG-1B数据集上,与对应的有监督预训练模型在指标上平分秋色。在
上要更高。
语义分割:在城市景观上 MoCo胜过了有监督预训练模型达到了0.9个点。但是在VOC语义分割上,MoCo是至少低了 0.8个点。这是我们观察到的一个负面情况。
概述 总的来说,MoCo在七个检测或者分割任务中能胜过与之对应的有监督预训练模型。除此之外,MoCo在城市景观的实例分割方面能与之平分秋色,在VOC语义分割上落后腿,我们在附录中展示了另一种关于iNaturalist的比较情况。总的来说,MoCo在很大程度上缩小了在多个视觉任务中无监督和有监督表征学习之间的差距。
显著地,在这些所有任务中,MoCo在IG-1B上的预训练要比 MoCo在IN-1M上的好。这表明MoCo能在大比例、相对未固化的数据集上执行的更好,这代表了一种面向现实世界无监督学习的场景。
5、讨论和结论
我们的方法在各种计算机视觉任务和数据集中显示了无监督学习的积极结果。少量的公开问题是值得讨论的。MoCo从IN-1M到IG-1B的改善一直很明显,但相对较小。这表明可能没有充分利用更大规模的数据。我们希望有一个高级的代理任务能改进这些。除了简单的实例判别任务,在语言和视觉任务中,还可以采用MoCo来执行诸如屏蔽自动编码之类的代理任务。我们希望MoCo能对其他涉及对比学习的代理任务有所帮助。
参考文献
[1] Rıza Alp Guler, Natalia Neverova, and Iasonas Kokkinos. ¨
DensePose: Dense human pose estimation in the wild. In
CVPR, 2018.
[2] Philip Bachman, R Devon Hjelm, and William Buchwalter.
Learning representations by maximizing mutual information
across views. arXiv:1906.00910, 2019.
[3] Mathilde Caron, Piotr Bojanowski, Armand Joulin, and
Matthijs Douze. Deep clustering for unsupervised learning
of visual features. In ECCV, 2018.
[4] Mathilde Caron, Piotr Bojanowski, Julien Mairal, and Armand Joulin. Unsupervised pre-training of image features
on non-curated data. In ICCV, 2019.
[5] Ken Chatfield, Victor Lempitsky, Andrea Vedaldi, and Andrew Zisserman. The devil is in the details: an evaluation of
recent feature encoding methods. In BMVC, 2011.
[6] Liang-Chieh Chen, George Papandreou, Iasonas Kokkinos,
Kevin Murphy, and Alan L Yuille. DeepLab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected CRFs. TPAMI, 2017.
[7] Ting Chen, Simon Kornblith, Mohammad Norouzi, and Geoffrey Hinton. A simple framework for contrastive learning
of visual representations. arXiv:2002.05709, 2020.
[8] Xinlei Chen, Haoqi Fan, Ross Girshick, and Kaiming He.
Improved baselines with momentum contrastive learning.
arXiv:2003.04297, 2020.
[9] Adam Coates and Andrew Ng. The importance of encoding
versus training with sparse coding and vector quantization.
In ICML, 2011.
[10] Marius Cordts, Mohamed Omran, Sebastian Ramos, Timo
Rehfeld, Markus Enzweiler, Rodrigo Benenson, Uwe
Franke, Stefan Roth, and Bernt Schiele. The Cityscapes
dataset for semantic urban scene understanding. In CVPR,
2016.
[11] Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li,
and Li Fei-Fei. ImageNet: A large-scale hierarchical image
database. In CVPR, 2009.
[12] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina
Toutanova. BERT: Pre-training of deep bidirectional transformers for language understanding. In NAACL, 2019.
[13] Carl Doersch, Abhinav Gupta, and Alexei A Efros. Unsupervised visual representation learning by context prediction. In
ICCV, 2015.
[14] Carl Doersch and Andrew Zisserman. Multi-task selfsupervised visual learning. In ICCV, 2017.
[15] Jeff Donahue, Philipp Krahenb ¨ uhl, and Trevor Darrell. Ad- ¨
versarial feature learning. In ICLR, 2017.
[16] Jeff Donahue and Karen Simonyan. Large scale adversarial
representation learning. arXiv:1907.02544, 2019.
[17] Alexey Dosovitskiy, Jost Tobias Springenberg, Martin Riedmiller, and Thomas Brox. Discriminative unsupervised
feature learning with convolutional neural networks. In
NeurIPS, 2014.
[18] Mark Everingham, Luc Van Gool, Christopher KI Williams,
John Winn, and Andrew Zisserman. The Pascal Visual Object Classes (VOC) Challenge. IJCV, 2010.
[19] Spyros Gidaris, Praveer Singh, and Nikos Komodakis. Unsupervised representation learning by predicting image rotations. In ICLR, 2018.
[20] Ross Girshick. Fast R-CNN. In ICCV, 2015.
[21] Ross Girshick, Jeff Donahue, Trevor Darrell, and Jitendra
Malik. Rich feature hierarchies for accurate object detection
and semantic segmentation. In CVPR, 2014.
[22] Ross Girshick, Ilija Radosavovic, Georgia Gkioxari, Piotr
Dollar, and Kaiming He. Detectron, 2018. ´
[23] Aidan N Gomez, Mengye Ren, Raquel Urtasun, and Roger B
Grosse. The reversible residual network: Backpropagation
without storing activations. In NeurIPS, 2017.
[24] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing
Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and
Yoshua Bengio. Generative adversarial nets. In NeurIPS,
2014.
[25] Priya Goyal, Piotr Dollar, Ross Girshick, Pieter Noord- ´
huis, Lukasz Wesolowski, Aapo Kyrola, Andrew Tulloch,
Yangqing Jia, and Kaiming He. Accurate, large minibatch
SGD: Training ImageNet in 1 hour. arXiv:1706.02677, 2017.
[26] Priya Goyal, Dhruv Mahajan, Abhinav Gupta, and Ishan
Misra. Scaling and benchmarking self-supervised visual representation learning. In ICCV, 2019.
[27] Agrim Gupta, Piotr Dollar, and Ross Girshick. LVIS: A
dataset for large vocabulary instance segmentation. In CVPR,
2019.
[28] Michael Gutmann and Aapo Hyvarinen. Noise-contrastive ¨
estimation: A new estimation principle for unnormalized statistical models. In AISTATS, 2010.
[29] Raia Hadsell, Sumit Chopra, and Yann LeCun. Dimensionality reduction by learning an invariant mapping. In CVPR,
2006.
[30] Bharath Hariharan, Pablo Arbelaez, Lubomir Bourdev, ´
Subhransu Maji, and Jitendra Malik. Semantic contours from
inverse detectors. In ICCV, 2011.
[31] Kaiming He, Ross Girshick, and Piotr Dollar. Rethinking ´
ImageNet pre-training. In ICCV, 2019.
[32] Kaiming He, Georgia Gkioxari, Piotr Dollar, and Ross Gir- ´
shick. Mask R-CNN. In ICCV, 2017.
[33] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Deep residual learning for image recognition. In CVPR,
2016.
[34] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun.
Identity mappings in deep residual networks. In ECCV,
2016.
[35] Olivier J Henaff, Ali Razavi, Carl Doersch, SM Eslami, and ´
Aaron van den Oord. Data-efficient image recognition with
contrastive predictive coding. arXiv:1905.09272, 2019. Updated version accessed at https://openreview.net/
pdf?id=rJerHlrYwH.
[36] R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon,
Karan Grewal, Adam Trischler, and Yoshua Bengio. Learning deep representations by mutual information estimation
and maximization. In ICLR, 2019.
[37] Sergey Ioffe and Christian Szegedy. Batch normalization:
Accelerating deep network training by reducing internal covariate shift. In ICML, 2015.
[38] Alexander Kolesnikov, Xiaohua Zhai, and Lucas Beyer. Revisiting self-supervised visual representation learning. In
CVPR, 2019.
[39] Yann LeCun, Bernhard Boser, John S Denker, Donnie
Henderson, Richard E Howard, Wayne Hubbard, and
Lawrence D Jackel. Backpropagation applied to handwritten zip code recognition. Neural computation, 1989.
[40] Sungbin Lim, Ildoo Kim, Taesup Kim, Chiheon Kim, and
Sungwoong Kim. Fast AutoAugment. arXiv:1905.00397,
2019.
[41] Tsung-Yi Lin, Piotr Dollar, Ross Girshick, Kaiming He, ´
Bharath Hariharan, and Serge Belongie. Feature pyramid
networks for object detection. In CVPR, 2017.
[42] Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays,
Pietro Perona, Deva Ramanan, Piotr Dollar, and C Lawrence ´
Zitnick. Microsoft COCO: Common objects in context. In
ECCV, 2014.
[43] Jonathan Long, Evan Shelhamer, and Trevor Darrell. Fully
convolutional networks for semantic segmentation. In
CVPR, 2015.
[44] Dhruv Mahajan, Ross Girshick, Vignesh Ramanathan,
Kaiming He, Manohar Paluri, Yixuan Li, Ashwin Bharambe,
and Laurens van der Maaten. Exploring the limits of weakly
supervised pretraining. In ECCV, 2018.
[45] Mehdi Noroozi and Paolo Favaro. Unsupervised learning of
visual representations by solving jigsaw puzzles. In ECCV,
2016.
[46] Aaron van den Oord, Yazhe Li, and Oriol Vinyals. Representation learning with contrastive predictive coding.
arXiv:1807.03748, 2018.
[47] Deepak Pathak, Ross Girshick, Piotr Dollar, Trevor Darrell, ´
and Bharath Hariharan. Learning features by watching objects move. In CVPR, 2017.
[48] Deepak Pathak, Philipp Krahenbuhl, Jeff Donahue, Trevor
Darrell, and Alexei A Efros. Context encoders: Feature
learning by inpainting. In CVPR, 2016.
[49] Chao Peng, Tete Xiao, Zeming Li, Yuning Jiang, Xiangyu
Zhang, Kai Jia, Gang Yu, and Jian Sun. MegDet: A large
mini-batch object detector. In CVPR, 2018.
[50] Alec Radford, Karthik Narasimhan, Tim Salimans, and Ilya
Sutskever. Improving language understanding by generative
pre-training. 2018.
[51] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario
Amodei, and Ilya Sutskever. Language models are unsupervised multitask learners. 2019.
[52] Shaoqing Ren, Kaiming He, Ross Girshick, and Jian Sun.
Faster R-CNN: Towards real-time object detection with region proposal networks. In NeurIPS, 2015.
[53] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR,
2015.
[54] Josef Sivic and Andrew Zisserman. Video Google: a text
retrieval approach to object matching in videos. In ICCV,
2003.
[55] Bart Thomee, David A Shamma, Gerald Friedland, Benjamin Elizalde, Karl Ni, Douglas Poland, Damian Borth, and
Li-Jia Li. YFCC100M: The new data in multimedia research.
Communications of the ACM, 2016.
[56] Yonglong Tian, Dilip Krishnan, and Phillip Isola. Contrastive multiview coding. arXiv:1906.05849, 2019. Updated
version accessed at https://openreview.net/pdf?
id=BkgStySKPB.
[57] Grant Van Horn, Oisin Mac Aodha, Yang Song, Yin Cui,
Chen Sun, Alex Shepard, Hartwig Adam, Pietro Perona, and
Serge Belongie. The iNaturalist species classification and
detection dataset. In CVPR, 2018.
[58] Pascal Vincent, Hugo Larochelle, Yoshua Bengio, and
Pierre-Antoine Manzagol. Extracting and composing robust
features with denoising autoencoders. In ICML, 2008.
[59] Xiaolong Wang and Abhinav Gupta. Unsupervised learning
of visual representations using videos. In ICCV, 2015.
[60] Yuxin Wu, Alexander Kirillov, Francisco Massa, Wan-Yen
Lo, and Ross Girshick. Detectron2. https://github.
com/facebookresearch/detectron2, 2019.
[61] Zhirong Wu, Yuanjun Xiong, Stella Yu, and Dahua Lin. Unsupervised feature learning via non-parametric instance discrimination. In CVPR, 2018. Updated version accessed at:
https://arxiv.org/abs/1805.01978v1.
[62] Saining Xie, Ross Girshick, Piotr Dollar, Zhuowen Tu, and ´
Kaiming He. Aggregated residual transformations for deep
neural networks. In CVPR, 2017.
[63] Mang Ye, Xu Zhang, Pong C Yuen, and Shih-Fu Chang. Unsupervised embedding learning via invariant and spreading
instance feature. In CVPR, 2019.
[64] Richard Zhang, Phillip Isola, and Alexei A Efros. Colorful
image colorization. In ECCV, 2016.
[65] Richard Zhang, Phillip Isola, and Alexei A Efros. Split-brain
autoencoders: Unsupervised learning by cross-channel prediction. In CVPR, 2017.
[66] Chengxu Zhuang, Alex Lin Zhai, and Daniel Yamins. Local
aggregation for unsupervised learning of visual embeddings.
In ICCV, 2019. Additional results accessed from supplementary materials.
文章出处登录后可见!