目录
1. 前言
本文是斯坦福cs231n-2022的第二次作业的第1个问题(Multi-Layer Fully Connected Neural Networks)。 第1个作业参见:
cs231n-2022-assignment1#Q5:Higher Level Representations: Image Features
课程内容参见:CS231n Convolutional Neural Networks for Visual Recognition
本作业的内容包括构建一个任意层次的全连接神经网络模型(其实就是DNN啦)及其训练,可以看作是assignment1#Q4:Two-Layer Neural Network,的一个自然扩充。
作业的原始starter code可以从Assignment 1 (cs231n.github.io)下载。建议有兴趣的伙伴读原文,过于精彩,不敢搬运。本文可以作为补充阅读材料,主要介绍作业完成过程所涉及一些要点以及关键代码解读。修改的文件涉及以下几个文件:
- cs231n/layers.py
- cs231n/data_utils.py
- cs231n/optim.py
- cs231n/classifiers/fc_net.py
- FullyConnectedNets.ipynb
2. 数据加载
继承assignment1中的做法,使用tensorflow.keras进行数据加载,对data_utils.get_CIFAR10_data()进行了一点修改,如下所示(细节此处不再赘述,可以参考assignment1博客)。
# # Load the raw CIFAR-10 data
# cifar10_dir = os.path.join(
# os.path.dirname(__file__), "datasets/cifar-10-batches-py"
# )
#X_train, y_train, X_test, y_test = load_CIFAR10(cifar10_dir)
(X_train, y_train), (X_test, y_test) = keras.datasets.cifar10.load_data()
y_train = np.squeeze(y_train)
y_test = np.squeeze(y_test)
X_train = X_train.astype('float')
X_test = X_test.astype('float')3. 实现多层全连接网络
主要就是修改layers.py(各affine和relu层组件)和fc_net.py(将各层组件像搭积木一样集成称为完整的网络)。layers.py中各层组件都可以直接集成assignment1的实现,包括softmax_loss,此处不再赘述。
fc_net.py的基本构成方法与assigment1-Q4大抵相同,但是assigment1-Q4中只有两层固定的,而本问题是要实现任意多层,所以主要需要一些coding实现的技巧,需要用for-loop循环的方式取代assignment1-Q4中的实现。在实现中需要特别仔细注意各层之间的数据和变量的传递和连接,为了防止出错,先画出一张图来,然后对照着图进行连接是一个明智的选择。如下图所示为一个3层网络的结构图示例:
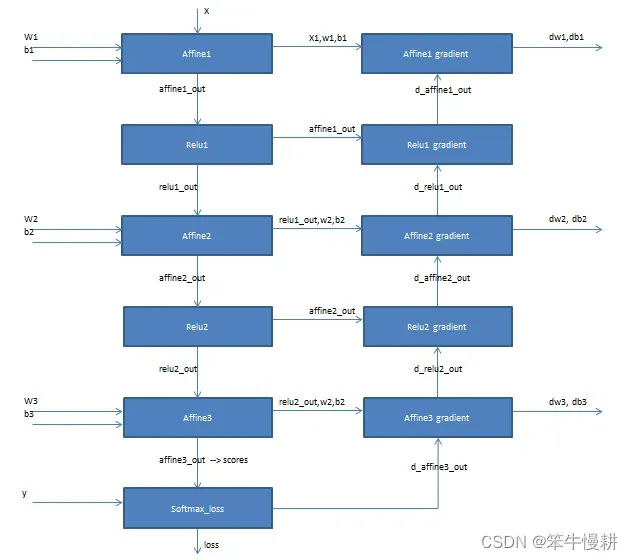
图1 3层全连接网络结构示意图
另外一个实现要点就是在forward/backward中第一层和最后一层的处理和其它中间层是不一样的。
def __init__()追加的代码如下所示:
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
self.params['W'+str(1)] = np.random.normal(loc=0.0, scale=weight_scale, size=(input_dim,hidden_dims[0]))
self.params['b'+str(1)] = np.zeros((hidden_dims[0],))
for k in range(2,self.num_layers):
self.params['W'+str(k)] = np.random.normal(loc=0.0, scale=weight_scale, size=(hidden_dims[k-2],hidden_dims[k-1]))
self.params['b'+str(k)] = np.zeros((hidden_dims[k-1],))
self.params['W'+str(self.num_layers)] = np.random.normal(loc=0.0, scale=weight_scale, size=(hidden_dims[-1],num_classes))
self.params['b'+str(self.num_layers)] = np.zeros((num_classes,))
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****forward处理和backward处理都集成在loss()中。
loss()#forward部分的代码如下所示:
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
# The first L-1 affine layer
# print(self.params.keys())
layer_in = X
cache = dict()
for k in range(1,self.num_layers):
W = self.params['W'+str(k)]
b = self.params['b'+str(k)]
affine_out, affine_cache = affine_forward(layer_in,W,b)
relu_out, relu_cache = relu_forward(affine_out)
layer_in = relu_out
cache['affine_cache'+str(k)] = affine_cache
cache['relu_cache'+str(k)] = relu_cache
# The last affine layer, without relu
W = self.params['W'+str(self.num_layers)]
b = self.params['b'+str(self.num_layers)]
affine_out, affine_cache = affine_forward(layer_in,W,b)
scores = affine_out
cache['affine_cache'+str(self.num_layers)] = affine_cache
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****loss()#backward部分的代码如下所示:
# *****START OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****
loss, d_affine_out = softmax_loss(scores, y)
for k in range(1,self.num_layers+1):
W = self.params['W'+str(k)]
#b = self.params['b'+str(k)]
loss += 0.5 * self.reg * np.sum(np.square(W))
# Backward processing for the last layer
W = self.params['W'+str(self.num_layers)]
#b = self.params['b'+str(self.num_layers)]
affine_cache = cache['affine_cache'+str(self.num_layers)]
d_relu_out,dw,db = affine_backward(d_affine_out, affine_cache)
dw += self.reg * W
grads['W'+str(self.num_layers)] = dw
grads['b'+str(self.num_layers)] = db
# Backward processing for all but the last layers
for k in range(self.num_layers-1,0,-1):
W = self.params['W'+str(k)]
affine_cache = cache['affine_cache'+str(k)]
relu_cache = cache['relu_cache'+str(k)]
d_affine_out = relu_backward(d_relu_out, relu_cache)
d_relu_out,dw,db = affine_backward(d_affine_out, affine_cache)
dw += self.reg * W
grads['W'+str(k)] = dw
grads['b'+str(k)] = db
# *****END OF YOUR CODE (DO NOT DELETE/MODIFY THIS LINE)*****4. Sanity check
4.1 用小数据集训练一个三层网络
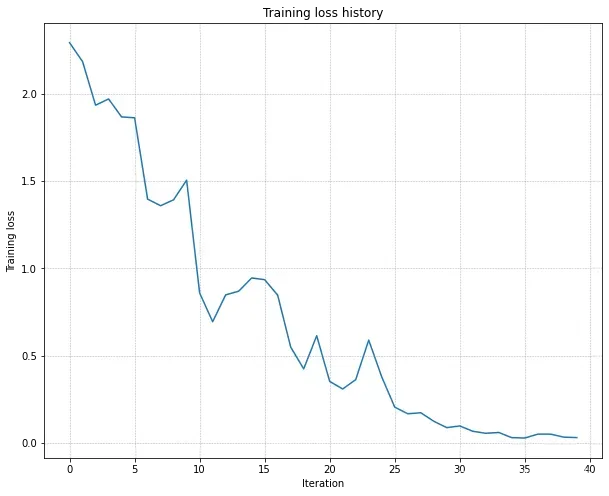
完成了以上模型后,构建一个三层网络(两个中间层各100个节点)针对一个只有50个样本的小训练集进行试行训练,用于对模型进行基本的正确性验证(此即sanity check)。可以看到在训练集上轻松达到了100%的准确度,但是在验证集上只有可怜的17%,这当然意味着严重的overfit。
(Iteration 31 / 40) loss: 0.096088 (Epoch 16 / 20) train acc: 1.000000; val_acc: 0.171000 (Epoch 17 / 20) train acc: 1.000000; val_acc: 0.176000 (Epoch 18 / 20) train acc: 1.000000; val_acc: 0.173000 (Epoch 19 / 20) train acc: 1.000000; val_acc: 0.171000 (Epoch 20 / 20) train acc: 1.000000; val_acc: 0.173000
4.2 用小数据集训练一个五层网络
接下来同样在小数据集上训练一个五层网络[100, 100, 100, 100]。这个实验的目的是获得一个关于深度神经网络训练的难度随着模型规模(复杂度)增加而增加的一个感性认识。
五层网络不再像三层网络一样随意地指定一些参数就可以轻松达到100%的训练集性能。以下写了一个循环对learning_rate和weight_scale进行若干组合的扫描实验:
# TODO: Use a five-layer Net to overfit 50 training examples by
# tweaking just the learning rate and initialization scale.
num_train = 50
small_data = {
'X_train': data['X_train'][:num_train],
'y_train': data['y_train'][:num_train],
'X_val': data['X_val'],
'y_val': data['y_val'],
}
best_train_acc = 0
for learning_rate in [5e-2,1e-2,5e-3,2.5e-3,1e-3]: # Experiment with this!
for weight_scale in [1e-1, 5e-2, 2.5e-2, 1e-2]: # Experiment with this!
model = FullyConnectedNet(
[100, 100, 100, 100],
weight_scale=weight_scale,
dtype=np.float64
)
solver = Solver(
model,
small_data,
print_every=10,
num_epochs=20,
batch_size=25,
update_rule='sgd',
optim_config={'learning_rate': learning_rate},
verbose=False
)
solver.train()
print('learning_rate={0}, weight_scale={1}, train_acc={2}'\
.format(learning_rate,weight_scale,solver.train_acc_history[-1]))
if best_train_acc < solver.train_acc_history[-1]:
best_train_acc = solver.train_acc_history[-1]
best_lr, best_ws = learning_rate, weight_scale结果如下所示。可以看出,这个网络对于learning_rate和weight_scale非常地敏感,在某些参数组合中,在这个那个的模块里会出现overflow的问题。 只有weight_scale=0.1或者0.05跟learning_rate的某些组合情况下能够达到100%的训练集准确度。而在3层网络中使用weight_scale=0.01用在这里的话只能获得不到20%的训练集准确度。
F:\DL\cs231n\assignment2_chenxy\cs231n\layers.py:28: RuntimeWarning: overflow encountered in matmul out = np.reshape(x, (x.shape[0], -1)) @ w + b F:\DL\cs231n\assignment2_chenxy\cs231n\layers.py:146: RuntimeWarning: invalid value encountered in subtract scores = scores - np.max(scores,axis=1,keepdims=True)learning_rate=0.05, weight_scale=0.1, train_acc=0.08F:\DL\cs231n\assignment2_chenxy\cs231n\layers.py:28: RuntimeWarning: invalid value encountered in matmul out = np.reshape(x, (x.shape[0], -1)) @ w + b F:\DL\cs231n\assignment2_chenxy\cs231n\layers.py:61: RuntimeWarning: invalid value encountered in matmul dw = np.reshape(x, (x.shape[0], -1)).T @ doutlearning_rate=0.05, weight_scale=0.05, train_acc=0.08 learning_rate=0.05, weight_scale=0.025, train_acc=0.54 learning_rate=0.05, weight_scale=0.01, train_acc=0.16F:\DL\cs231n\assignment2_chenxy\cs231n\classifiers\fc_net.py:209: RuntimeWarning: overflow encountered in square loss += 0.5 * self.reg * np.sum(np.square(W)) F:\DL\cs231n\assignment2_chenxy\cs231n\classifiers\fc_net.py:209: RuntimeWarning: invalid value encountered in double_scalars loss += 0.5 * self.reg * np.sum(np.square(W))learning_rate=0.01, weight_scale=0.1, train_acc=0.08 learning_rate=0.01, weight_scale=0.05, train_acc=1.0 learning_rate=0.01, weight_scale=0.025, train_acc=0.42 learning_rate=0.01, weight_scale=0.01, train_acc=0.16 learning_rate=0.005, weight_scale=0.1, train_acc=0.08 learning_rate=0.005, weight_scale=0.05, train_acc=1.0 learning_rate=0.005, weight_scale=0.025, train_acc=0.3 learning_rate=0.005, weight_scale=0.01, train_acc=0.16 learning_rate=0.0025, weight_scale=0.1, train_acc=1.0 learning_rate=0.0025, weight_scale=0.05, train_acc=1.0 learning_rate=0.0025, weight_scale=0.025, train_acc=0.3 learning_rate=0.0025, weight_scale=0.01, train_acc=0.16 learning_rate=0.001, weight_scale=0.1, train_acc=1.0 learning_rate=0.001, weight_scale=0.05, train_acc=0.94 learning_rate=0.001, weight_scale=0.025, train_acc=0.3 learning_rate=0.001, weight_scale=0.01, train_acc=0.12
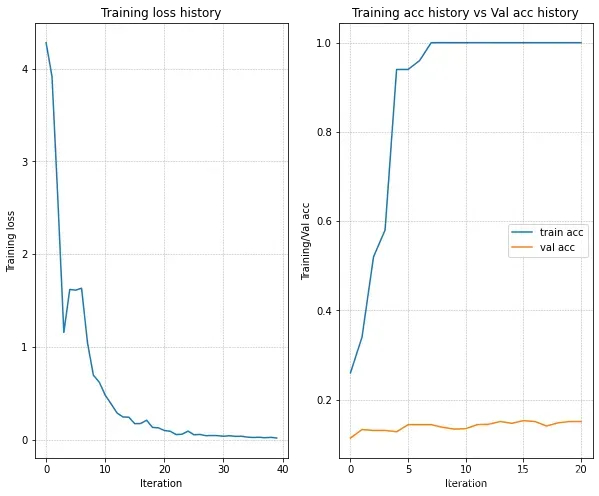
在参数组合{learning_rate=0.01, weight_scale=0.05}条件下的loss和acc的变化趋势图如下所示:
5. 更新规则
作业要求中所提的SGD+momentum、RMSProp and Adam其实在assignment1中都已经实现了,详细参见cs231n-2022-assignment1#Q4:Two-Layer Neural Network(Part2)
但是在测试中发现SGD+momentum无法通过一致性验证,仔细检查了以下,发现本作业中所描述SGD+momentum更新规则与我之前实现的不要一样。我在assigment1中实现的动量梯度下降的更新规则如下:
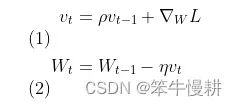
但是, 本作业中所给出的更新规则是这样的:
# Momentum update v = mu * v - learning_rate * dx # integrate velocity x += v # integrate position
虽然形式上不同,但是应该都能达到相同的效果,即数学意义上是等价的。
6. Train a Good Model!
做了以上准备工作后,是时候在这个训练一个深度神经网络看看能不能在cifar10数据集上获得比之前两层神经网络更好的分类准确度性能。搜索过程略过,最后得到一个3层网络,在以下参数配置条件下可以在验证集上得到55%的准确度。
# Search for the best model using adam optimizer
learning_rates = {'rmsprop': 1e-4, 'adam': 1e-4}
#for update_rule in ['adam', 'rmsprop']:
solvers = dict()
for update_rule in ['adam']:
print('Running with ', update_rule)
model = FullyConnectedNet(
[256,100],
weight_scale=1e-3
)
solver = Solver(
model,
data, # Note: return to full cifar10 dataset instead of setsmall_data,
num_epochs=10,
batch_size=256,
update_rule=update_rule,
lr_decay=0.95,
optim_config={'learning_rate': learning_rates[update_rule]},
verbose=True
)
solvers[update_rule] = solver
solver.train()
fig, axes = plt.subplots(3, 1, figsize=(15, 15))
axes[0].set_title('Training loss')
axes[0].set_xlabel('Iteration')
axes[1].set_title('Training accuracy')
axes[1].set_xlabel('Epoch')
axes[2].set_title('Validation accuracy')
axes[2].set_xlabel('Epoch')
for update_rule, solver in solvers.items():
axes[0].plot(solver.loss_history, label=f"{update_rule}")
axes[1].plot(solver.train_acc_history, label=f"{update_rule}")
axes[2].plot(solver.val_acc_history, label=f"{update_rule}")
for ax in axes:
ax.legend(loc='best', ncol=4)
ax.grid(linestyle='--', linewidth=0.5)
plt.show() 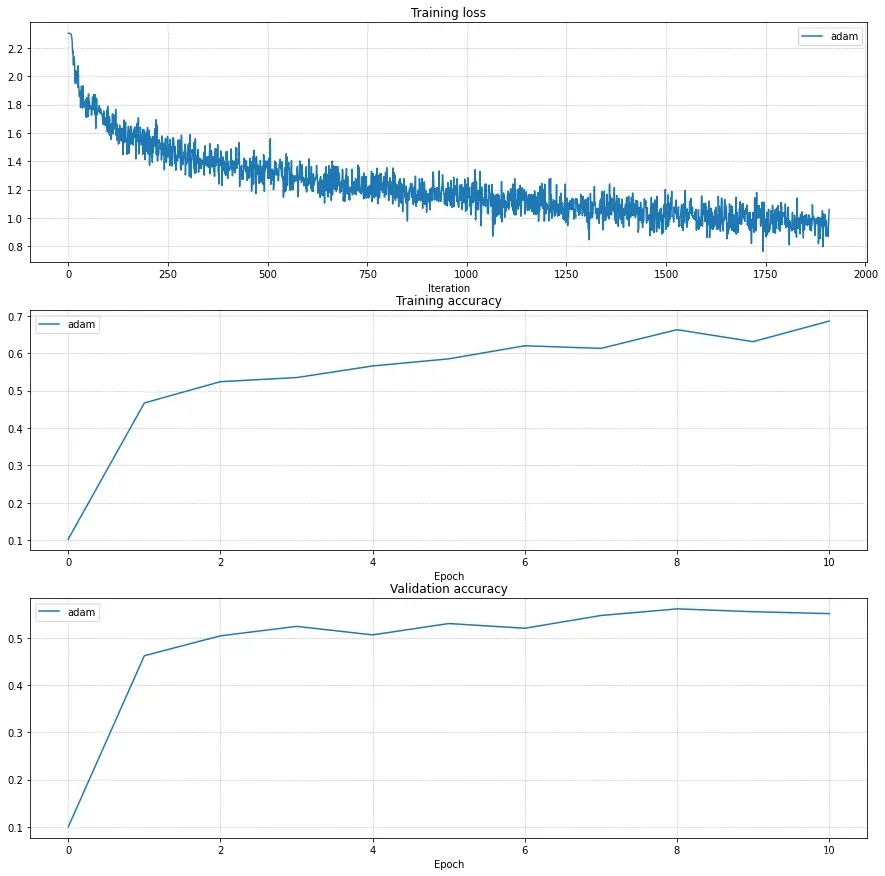
同样在测试集上也可以得到55%的准确度。
以上结果其实是有明显的过拟合现象,但是追加了reg=0.1的正则化,虽然训练集上的准确度下降了,但是验证集上的准确度也下降了。有待进一步调查。
本作业assignment2将在全部完成之后统一上传。
文章出处登录后可见!