Double Machine Learning——一种去偏方法
DML是一种处理基于观测数据进行因果建模的方法。
大家已知的是,观测数据是有偏的,即存在特征X既影响目标outcome Y,又影响Treatment T。那么在进行因果建模之前,我们需要进行去偏处理,使得Treatment Y独立于特征X,此时的观测数据近似相当于RCT数据,之后我们就可以使用因果模型进行CATE评估了。
HTE旨在量化Treatment对不同人群的差异影响,进而通过人群定向/数值策略的方式进行差异化处理。Double Machine Learning–DML是在研究HTE (Heterogenous Treatment Effect)过程中,通过残差估计矩(服从Neyman orthogonality),即使W(nuisance parameter)估计有偏,依旧可以得到无偏ATE估计的算法框架
构建模拟数据
在介绍DML之前,我们首先给定模拟数据——冰淇淋价格和销量之间的因果效应评估数据集。
该数据集中,特征X包括温度、成本和一周中的周几三个变量,Treatment T为价格,outcome Y为销售量。其中,T影响Y,X影响T和Y,即存在混淆。
探索冰淇淋销量和价格之间的关系,可以看到weekday是confounder,周末时价格和销量均更高。如果要得到准确的causal effect,需要矫正confounders带来的偏差。此数据集中包含的confounders有温度、周几、成本
我们使用观测数据进行训练,在RCT数据上进行模型评估。(一种正确而标准的因果建模评估流程)
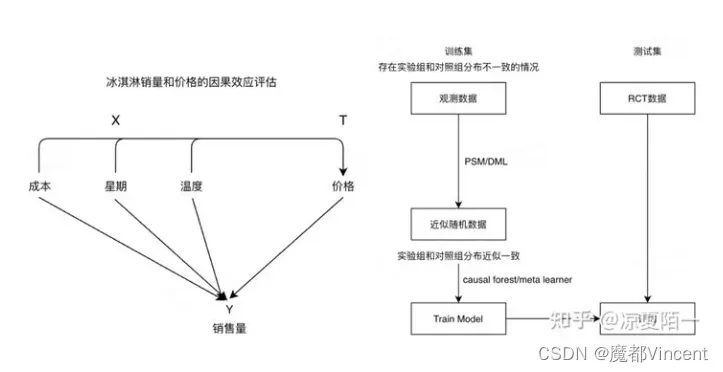
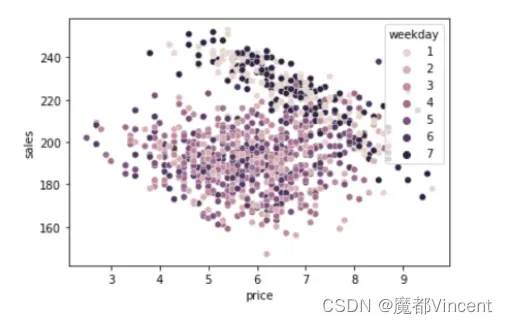
通过可视化,我们可以很明显看到,在周末(weekday=1和7)的时候,价格比平常要高很多,即存在混淆。
1.从线性回归说起
一种简单的去偏方法就是线性回归,我们拟合一个线性回归模型,然后固定其他变量不变,去估计平均因果效应(ATE)。
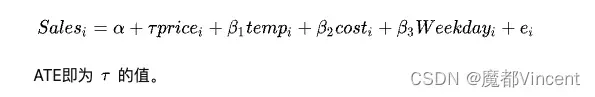
是我们唯一需要关注的,因为
是需要求的价格对销量的因果效应,其他变量我们并不关心,但是在线性模型中需要正确对待,否则得到的
但特征X与Y的关系可能是非线性的,如温度temp。当温度升高时,人们可能都去沙滩玩耍,买冰淇淋吃,销量Y升高,但当温度过高时,人们可能只想呆在家,这时销量Y就下降了。
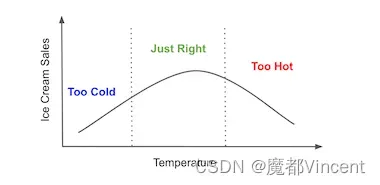
因此,我们需要利用一个线性回归的非常重要的特性:
假设现在有一个LR模型,以及特征集 X1 和特征集X2 . 我们可以通过以下两种方式来估计参数,而这两种方式估计出来的参数是相同的
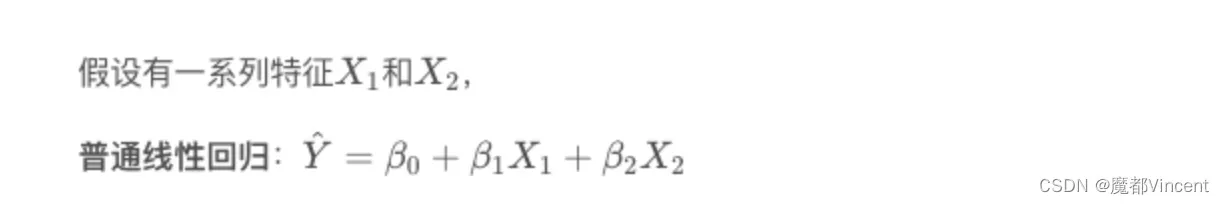


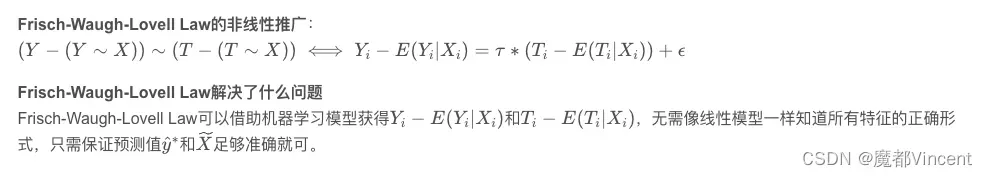
文章出处登录后可见!