一、个人需求
需求:
- 靠游戏手柄(用户)以虚拟人物的根轨迹trajectory来控制用户朝向,同时通过控制输入来合成出人难以做到的动作。
- 若缺少数据集,可以用强化学习来完成一些靠手柄来控制的动作如飞踢,还要可以完成用户指哪踢到哪的需求,而身体其他部位的动作靠动捕完成(可以考虑不同人物动作风格),即每一种语义必须由用户来决定。
- 考虑过插帧的方法,即用不同来源动作库、游戏控制、捕捉等来组合进行插帧,经讨论过后还是决定采用第二点。
现有问题:
动捕数据比较贵缺少大的数据集,并且已有的数据集比如人物动画目前动捕数据位移不完善,动捕是无法让角色在VR中无限行走,动捕也无法让用户完成飞跃等动作,这也是通过用户控制输入来合成动作完成的…
二、角色动画(Character Animation)的现状与趋势
- 状态机动画,工程量大、过渡容易失真,脚步打滑穿模等;
- Motion Matching,通过算法去选择动画的“状态”,需要大量动捕数据讲究匹配速度;
- 基于数据驱动的AI方法,PFNN等,引入深度学习由神经网络记忆动捕动画来预测下一帧的动画,训练时采用动捕数据片段的下一帧作为标签;
这一类被称为运动学动画(Kinematic-based Animation),主要都是Daniel Holden及他的师兄弟的工作。它的局限性在于所有的动画样本都是预设的(比如动捕录制),AI学的也是这些预设动作,在输出动画时AI并没有考虑虚拟的物理环境对角色的影响。 物理动画(Physics-based Animation)
物理动画驱动角色的方式和运动学动画的方式是完全不同的。对于运动学动画,我们直接对角色的姿态进行赋值,比如它的关节位置;而对于物理动画,我们则是像驱动机器人一样控制每一个关节的电机,由关节电机输出扭矩来改变关节的位置,同时这个过程严格受物理定律影响。
这块的开山之作是Xuebin Peng的DeepMimic,以一段动捕数据作为输入,然后用DRL训练得到一个控制策略,然后利用这个控制策略让模拟的agent在物理引擎中复现这个动作。DeepMimic提供了一套可扩展的的DRL框架来模仿学习不同的motion skill。
后续几年的大多工作基本都基于DeepMimic,这些工作大同小异,想法都是用一个基于kinematic-based的motion generator (PFNN等神经网络或者motion matching等传统技术)来生成refenece motion,然后用physical-based的方法来track这些reference motion。
1. 运动学动画
Phase-functioned neural networks for character control’17
https://blog.csdn.net/zb1165048017/article/details/103990505
本文使用Phase Function相位函数去周期性循环动态改变权重,这个Phase在文中是用于指定脚的落地状态即右脚着地时相位为0,左脚着地时相位为π,下次右脚着地时相位为2 π。
在做动捕时,通常会用某个控制参数去改变训练完毕的神经网络的权重,将下一帧的运动风格导向到指定行为状态。比如本来是走运动,如果输入一直是走,权重又不变,那么后面所有生成的动画帧都很难过渡到跑或者其它运动风格。通过某个控制参数去动态指向性地调整权重,就能将运动从走的特征空间拉到跑的隐特征空间,再从特征空间重构骨骼动画数据(欧拉角、3D坐标等)。
所以当多个运动片段被插值合成一个新的运动时,通过调整混合权值可以构建一个平滑自然的大范围变化的运动。
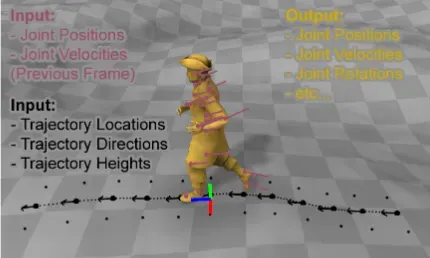
如上图所示,粉色是前一帧中角色关节的位置和速度。黑色部分为下采样轨迹位置、方向和高度。黄色是角色的网格,使用系统输出的关节位置和旋转进行变形。
数据集:
动捕各种地形(障碍物,斜坡,平台等),各种行为(走、慢跑、跑、蹲伏、跳跃、不同步长等),大约一个小时的数据,60FPS,1.5G。CMU的BVH动捕数据格式,包括30个关节的旋转角,1个根关节的位置。
数据标签:
- 相位标签:
当脚着地时间得到了以后,把右脚刚着地时的相位phase标记为0,把左脚刚着地时的相位标记为π,把下次右脚着地的相位标记为2 π。 - 步态标签:
二值标签向量,表示不同场景中的8种不同运动风格,需要人工标记。
Neural State Machine for Character-Scene Interactions’19
上一篇文章强制使用一个固定的相位函数来分解网络权值[Holden et al. 2017],这只适合周期性的循环运动。在这篇论文中,作者提出了一种神经状态机,来建模广泛的周期性和非周期性运动,包括运动、坐、站、提升和避免碰撞。
本文相较于上面一篇文章,主要处理更复杂的游戏场景的交互,比如搬箱子、坐凳子之类的动作。
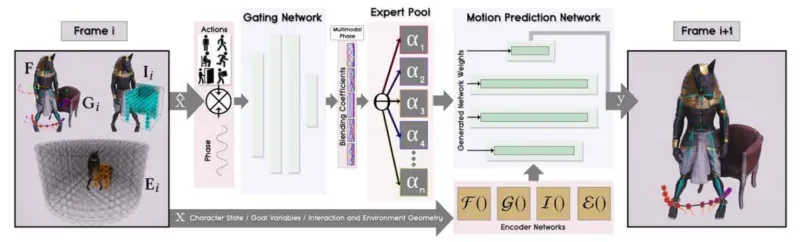
如上图所示,系统结构由Gating Network和Motion Prediction Network两个模块组成。门控网络以当前状态参数子集和目标动作向量作为输入,输出专家混合系数作为预测网络的weights,然后用于生成运动预测网络。运动预测网络把前一帧的姿态轨迹控制变量、目标参数、交互 参数、环境参数作为输入来预测当前帧。
比如用户只需要指示“坐在椅子上”作为期望的目标动作。然后将此输入到门控网络,激活它所需的专家权重以产生下一帧的动作。
数据集:
作者通过道具环境来捕捉一个人靠近和坐在椅子上、行走时避开障碍物、开门和穿过门、拿起、搬运和放下一个箱子的动作构建了一个数据集。并且构建了一些更复杂的场景,比如坐在一张部分位于桌子下方的椅子上,这样人物需要伸展腿或把手放在桌子上才能完成的坐的动作。由XSens惯性运动捕捉系统采集并输出共94分钟的运动捕捉数据。
数据标签:
- 动作标签:
每一帧数据都用一个当前和目标动作标签注释。比如“空闲”、“行走”、“运行”、“坐”、“打开”、“爬”或“携带”,或两个组合(“携带+闲置”、“携带+行走”),它们描述了当前帧的运动类型。通过使用目标标签作为目标参数G()的一部分来训练系统。 - 相位标签:
对于周期性运动,根据左/右/左脚着地时的相位定义为0、π和2π,中间的相位通过插值计算得到。对于像坐这样的非周期性运动,在转换开始和结束的坐标系中,相位被定义为0和2π,中间部分再次通过插值计算。
learned motion matching’20
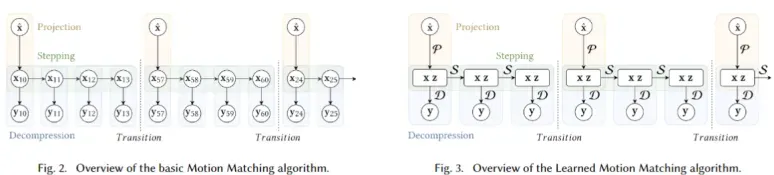
从左下图中可以看出,传统的运动匹配算法包括三个主要阶段:
Projection: 用最近邻搜索找到最佳匹配的特征向量匹配数据库中的查询向量;
Stepping: 将匹配数据库中的索引向前推进;
Decompression: 在动画数据库中查找与匹配数据库中当前索引对应的相关姿态而后进行匹配。
右下图是用神经网络来预测下一帧的方法,其中用来代替数据库Motion Matching的网络可拆解为三个独特的神经网络P、S、D。
- P网络负责根据查询向量 搜索出数据库中匹配的x,z;
- S网络负责根据前一帧轨迹x,z预测出下一帧的x,z;
- D网络负责根据当前帧的x, z 预测当前帧的姿势信息y。
最近的方法表明,基于神经网络的模型可以有效地应用于在许多困难的情况下生成真实的运动,包括在崎岖地形上导航[Holden等人2017年,上一篇],四足动物运动[Zhang等人2018年],以及与环境或其他角色的交互[Lee等人2018年;Starke et al. 2019]。然而,这样的模型往往难以控制,行为不可预测,训练时间长,并可能产生比原始训练集质量更低的动画[Büttner 2019;Zinno 2019]。
作者还使用了一种数据增强技术,Carpet unrolling for character control on uneven terrain 这篇论文使用的一种被称为“地毯展开”的自动数据增强技术,可以产生各种各样的转弯以及在崎岖地形上的移动。其结果是一个包含约700000帧动画的广泛数据库。然而当与基本的运动匹配时这个大的增强的数据库是非常低效的,但很容易适应作者的方法。
当环境是由不平坦的地形和巨大的障碍组成时,这个问题就更具有挑战性了,因为这需要角色执行各种步进、攀爬、跳跃或躲避动作,以便遵循用户的指示。在这种情况下,需要一个可以从大量高维运动数据中学习的框架,因为不同的运动轨迹和相应的几何形状可能存在一个大的组合。
2. 物理学动画
DeepMimic: Example-Guided Deep Reinforcement Learning’18
ubuntu下的环境配置
bvh2mimic强化学习训练集格式
这篇文章以一段motion capture作为输入,然后用DRL训练得到一个控制策略,然后利用这个控制策略让模拟的agent在physics simulation中复现这个动作。DeepMimic提供了一套scalable的DRL框架来模仿学习不同的motion skill。
后续几年的大多工作基本都基于DeepMimic,这些工作大同小异,想法都是用一个基于kinematic-based的motion generator (PFNN等神经网络或者motion matching等传统技术)来生成refenece motion,然后用physical-based的方法来track这些reference motion。
整个DeepMimic所需要的input分为三部分:一个被称为Character的Agent模型;想要Agent学习的参考动作(reference motion);想要Agent完成的任务(task)所定义的reward function。训练之后会得到一个可以控制Agent同时满足与参考动作相似且可以完成任务的控制器(controller)。DeepMimic的物理环境用的是Bullet 。
State: 身体各部分的位置,转动角度,角速度等等。
Action: 每个关节所需要转到的方向(目标角度),之后将角度转化为力矩等信息输入到物理环境中。
Reward: 分为两个部分,第一部分鼓励Character模仿学习所提供的的reference motion;第二部分驱动Character去完成所设定的任务。
更多结果:
-
总的来说,作者仅仅通过为人形动物提供不同的参考动作,就能够学习超过24种技能。

-
除了模仿动作捕捉之外,还可以训练人形执行一些额外的任务,例如踢随机放置的目标,或将球扔向目标。

-
在没有动捕数据的情况下。作者通过手动制作一些霸王龙的关键帧的动画,然后训练一个策略来模仿这些关键帧。
trick1:
参考状态初始化(Reference State Initialization,RSI)
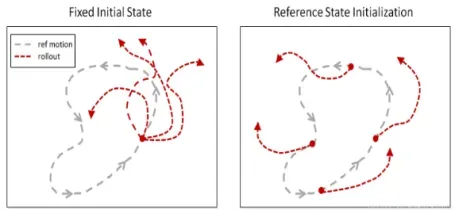
RSI 通过将智能体初始化至从参考动作随机采样的状态,为它提供丰富的初始状态分布。(包括直接从半空中开始)
trick2:
提前终止(Early Termination,ET)
如果智能体在某个状态被困住了,不再可能成功学习到动作,那么该 episode 将提前终止,以避免继续模拟。

左:RSI+ET;中:无 RSI;右:无 ET
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control’21
pytorch版本实现
本文给定一个定义角色所需运动风格的参考运动数据集,系统用Gan判别器训练一个运动先验,在训练期间为policy策略指定风格reward𝑟𝑆𝑡。这些风格奖励与任务奖励相结合,用于训练使模拟角色能够满足特定任务目标 g 的策略。
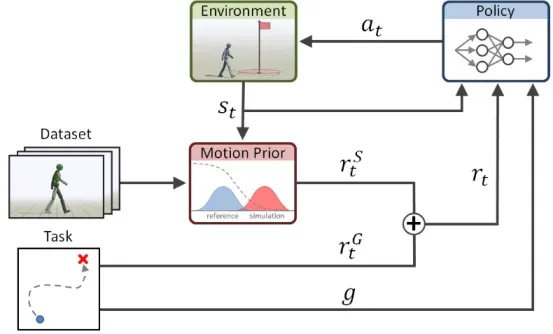
相比于之前的Deepmimic,此系统可以直接应用于原始运动数据,而不需要任务注释或者将剪辑分割成个人技能。风格目标充当与任务无关的运动先验,独立于特定任务,并且鼓励策略生成类似于数据集中描述的行为的动作。最终训练一个既能实现high level task(飞踢,扔球),又能让motion去拟合low level motion database(style,动捕数据)的网络。
三、附录
Motion Matching的基本概念:
数据预处理:
为了节省运行时的计算量,首先要对动捕数据做预计算,导出一份 Motion Matching 所需的用于加速搜索的数据集,对于基础移动而言一般需要对每帧动作预计算以下数据:
每帧动作都对应一个姿态数据(pose)和包含未来一段时间角色的运动轨迹(trajectory)
class Pose
{
Vector3 RootVelocity;
Vector3 LeftFootPosition;
Vector3 LeftFootVelocity;
Vector3 RightFootPosition;
Vector3 RightFootVelocity;
}
class TrajectoryPoint
{
Vector3 Position;
Vector3 Velocity;
}
class Trajectory
{
TrajectoryPoint[]points=new\ trajectoryPoint[3];
}
match算法运行:
输入:根据玩家手柄输入,给出角色预期的Trajectory
输出:去database中搜索匹配下一帧应该播放的动作,需要满足以下两个条件,
- 从下一帧动作开始,未来帧的Trajectory和输入的预期轨迹一致。
- 即将播放的姿态可以平滑衔接当前姿态,没有跳变。
文章出处登录后可见!