论文地址:
FBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function
问题
尽管NAS在网路架构方面取得了非常好的结果,比如EfficientNet、MixNet、MobileNetV3等等。但无论基于梯度的NAS,还是基于super net的NAS,亦或基于强化学习的NAS均存在这几个缺陷:
- 忽略了训练超参数,即仅仅关注于网络架构而忽略了训练超参数的影响;
- 仅支持一次性应用,即在特定约束下只会输出一个模型,不同约束需要不同的模型。
为解决上述所提到的缺陷,作者提出了JointNAS,同时对网络架构与训练策略进行搜索,将网络架构与对应的训练策略通过NAS联合搜索,之前的NAS方法主要聚焦在网络架构,而没有在意网络性能验证时的训练参数的设置是否合适,这可能导致模型性能下降,而JointNAS可以在资源约束的情况下,搜索最准确的训练参数以及网络结构。
JointNAS
JointNAS,分粗粒度和细粒度两个阶段,对网络架构和训练超参都进行搜索。
JointNAS优化目标可公式化为:
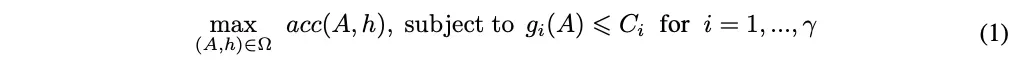
分别表示网络架构、训练策略以及搜索空间(见下表);
,
分别表示资源约束信息资源消耗计算和资源数量,acc计算当前结构和训练参数下的准确率
两个Stage的架构搜索(粗粒度+细粒度):

JointNAS的搜索过程如上图所示,将搜索分为两个阶段:
- 粗粒度阶段(coarse-grained),该阶段主要迭代式地寻找高性能的候选网络结构-超参数对以及训练准确率预测器。
- 细粒度阶段(fine-grained stages),借助粗粒度阶段训练的准确率预测器,对候选网络进行快速的进化算法搜索,该搜索集成了论文提出的超参数优化器AutoTrain。
粗粒度搜索
粗粒度搜索生成准确率预测器和一个高性能候选网络集,这个预测器是一个多层感知器构成的小型网络,包含了两个部分,一个代理预测器(Proxy Predictor),一个是准确率预测器(Accuracy Predictor)
预测器的结构如下图所示,包含一个结构编码器以及两个head,分别为辅助的代理head以及准确率head。代理head预测网络的属性(FLOPs或参数量等),主要在编码器预训练时使用,准确率head根据训练参数以及网络结构预测准确率,使用代理head预训练的编码器在迭代优化过程中进行fine-tuned。
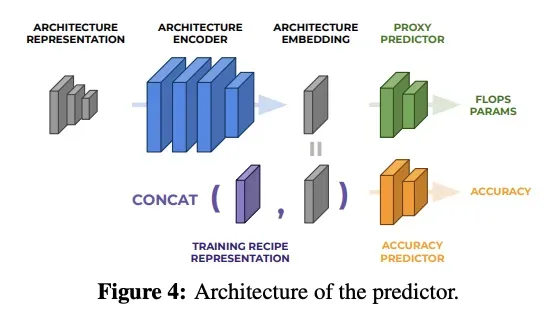
左边的architecture presentation指的是网络架构的编码描述,以one-hot或者int的形成一组矩阵向量,用来表示网络的结构(参考DARTS的架构参数),architecture encoder就是多层感知器,用来提取架构描述的特征,生成architecture embedding,也就是低维特征向量。这个低维特征向量首先用于Proxy Predictor的训练过程,由于任何一个网络架构描述都可以对应到一个实际的网络模型,同时也能对应它的计算量和参数量数值,所以在这个阶段的训练,并不需要额外的数据。
在预训练好第一排的网络后,就要来迭代训练第二排的准确率预测器了,这个预测器的输入数据为训练超参表示加上低维特征向量,而输出数据则是这个网络架构+训练超参的结果准确率。迭代优化的算法参考图2中Stage1部分,具体迭代步骤为:
- 基于已经预测的准确率,选择一组候选集,选择的方法为quosi蒙特卡洛(QMC);
- 训练和评估候选集的网络模型,得到评估准确率;
- 使用所有历史候选集的准确率和表示输入(架构+超参)去更新这个预测器。
在第一步迭代的时候,还要确定早停方案,早停主要是为了找到样本训练(网络本身的训练,不是对Predictor的训练)的epoch参数,确定方法为:
- 选取n个网络,对完整训练的结果和早停训练的结果分别作排序;
- 计算两种排序的相关性;
- 如果早停epoch达到某个值时,两种排序的相关性达到阈值(文中是0.92),则认为确定好了早停的epoch,否则重新加大epoch,进入步骤1重新开始。
使用早停策略得到的网络准确率,就可以用来训练更新预测器了,在更新预测器时也有几点tricks。首先,使用Huber Loss减少不正常样本的影响;其次,开始时冻结embedding层,只训练accuracy Predictor,50个epoch;最后,再训练整个Predictor,逐步减少学习率,50个epoch。
细粒度搜索
细粒度搜索的空间是网络架构+训练超参,搜索的方法是自适应遗传算法,如图2中的Stage所示,搜索步骤为:
- 选择最好的几个样本作为种群(第一代从粗粒度中选);
- 在给定约束的条件下,对这些样本使用变异的方法产生一个子代的种群;
- 使用准确率预测器生成子代种群的得分,如果最好的个体不再更新了,就停止迭代,否则进入步骤1。
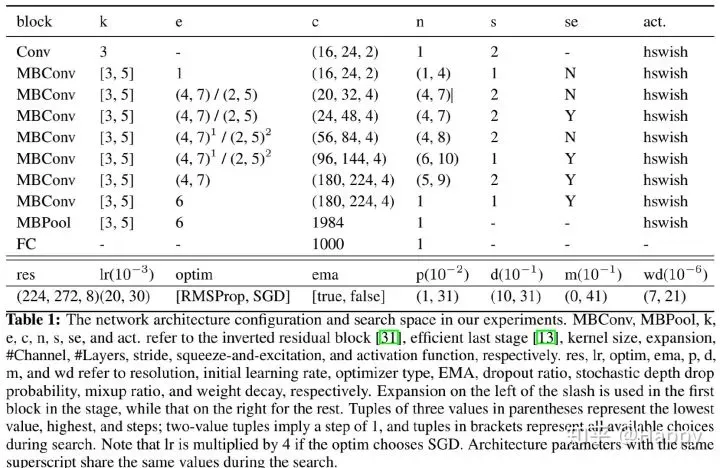
FBNetV3的搜索空间包括了训练超参和网络架构。训练超参的搜索空间包括了优化器类型、初始学习率、参数正则化比例、mixup比例、dropout比例、随机深度drop比例和是否使用EMA等。网络架构的搜索空间是逆残差模型的参数,包括输入分辨率、卷积核大小、中间通道放大比例、每一stage网络的通道数和深度等。
实验
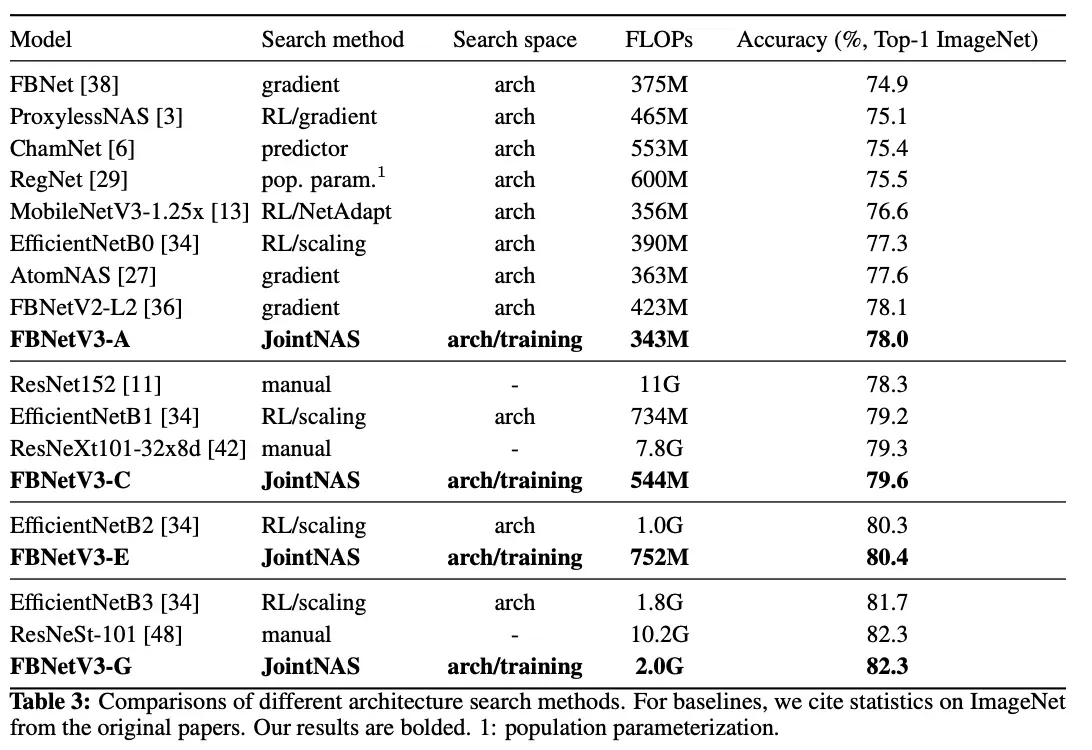
FBNetV3不同计算量级别的实验结果以及与其他网络的对比:
总结
将训练参数加入到了搜索过程中,提升性能;
设想:将参数初始化方式加入到搜索空间
参考
FBNet/FBNetV2/FBNetV3:Facebook在NAS领域的轻量级网络探索 | 轻量级网络
仅为学习记录,侵删!
文章出处登录后可见!