一、思路
这段时间完成了又一个程序,唐宇迪的验证码识别。主要内容是通过程序自己生成随机的验证码,然后导入模型中进行训练。验证码可以由数字、大小写字母来组合,但考虑到电脑资源和程序复杂度的问题,只用了数字进行操作。验证码识别分为几个部分:数据生成,数据处理,建立模型,跑模型;数据生成是随机抽取4个数字进行组合,数据处理是将数字组合转换成图片,同时把标签转换成矩阵。总的处理思路是这样的:函数随机生成图片和验证码标签——对图片进行归一化,把标签转换位矩阵标签——建立模型——数据输入,开始循环。这里面的重点是把标签转换成矩阵,其实就是把验证码的每个数字或字母转换成ascii码,同时编码成one-hot格式,由于一共有4个数字,每个数字是从1-9中提取出来的,所以一个数字是1×10的标签。举例,本例用的是纯数字编码,所以每个数字的one-hot格式可以表示为1×10的格式,一共4个数字,就是一个4×10的矩阵,只有在数字对应的位置上才会显示为1,例如1,那么就是0100000000。
二、程序详解
1.随机生成数据
先通过random_captcha_text(char_set=number,captcha_size=4)函数,在number = [‘0′,’1′,’2′,’3′,’4′,’5′,’6′,’7′,’8′,’9′]中选出4个数字,随机生成一个验证码;然后gen_captcha_text_and_image()把验证码转换成图片格式以及标签,标签转为字符,方便后面转为ascii码用。’ ‘.join是在text中插入空格,类似于把text转成字符。
def random_captcha_text(char_set=number,captcha_size=4):
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append(c)
return captcha_text
def gen_captcha_text_and_image():
image = ImageCaptcha()
captcha_text = random_captcha_text()
# change captcha_text into string type
captcha_text = ''.join(captcha_text)
captcha = image.generate(captcha_text)
captcha_image = Image.open(captcha)
captcha_image = np.array(captcha_image)
return captcha_text,captcha_image2.数据处理
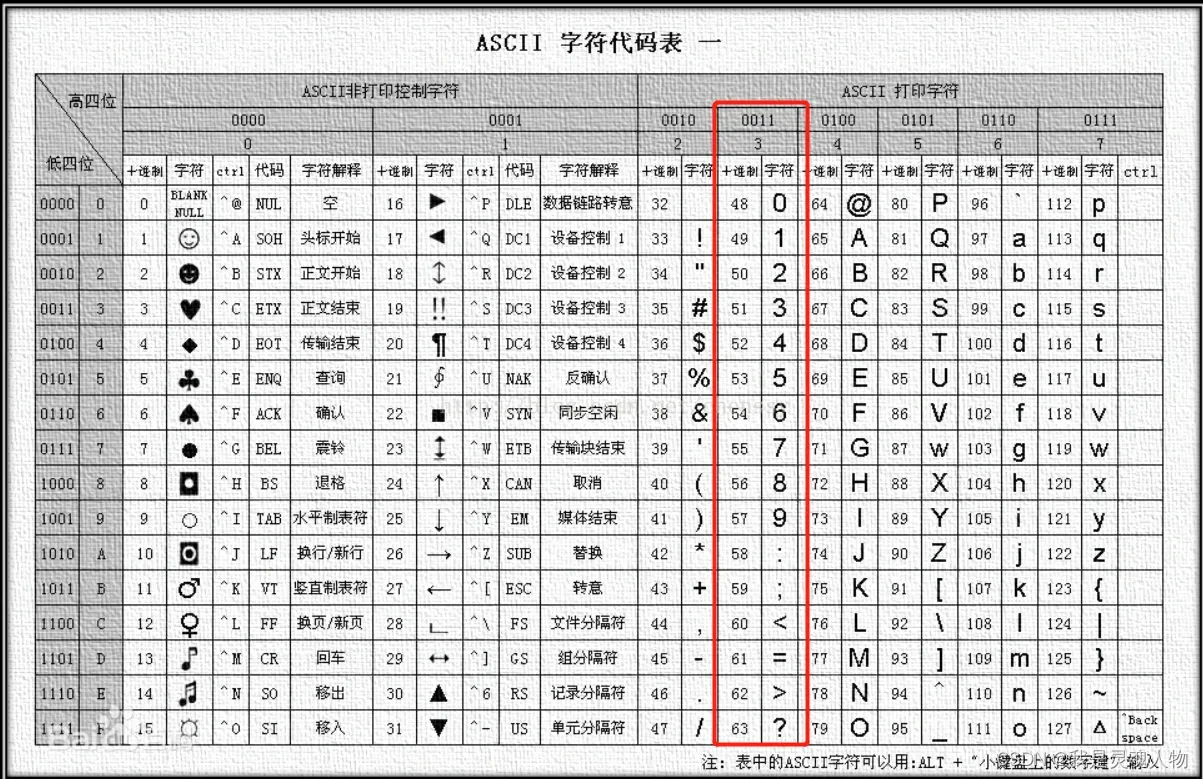
数据处理比较简单,先把图片都转成灰度图,然后求归一化,这里的归一化其实就是求了一个平均,其实不太准确;而转ASCII码这段刚开始还不太明白,后面对照这ASCII看了一下,因为这一段代码是可以0-9、A-Z、a-z全部转为ascii码的,所以先减去48,如果此时k还大于9的话,说明它是字符,那么就减去55转为大写字母,因为此时跳到26个大写字母了,我们要把A当作第11个数,所以应该是ord(c)-65+10,同理小写字母就是ord(c)-97+10+26。
def conver2gray(img):
if len(img.shape)>2:
gray = np.mean(img,-1)
return gray
else:
return img
# calculate the ascii code of number or string.
# turn the code into [4 10] one-hot.
def text2vec(text):
text_len = len(text)
if text_len > MAX_CAPTCHA:
raise ValueError('THE code is no longer than 4 char')
# for number:4*10
vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN)
def char2pos(c):
if c=='_':
k=62
return k
# ord:return ascii code
k = ord(c)-48
if k>9:
k = ord(c)-55
if k>35:
k=ord(c)-61
if k>61:
raise ValueError('no map')
return k
for i,c in enumerate(text):
idx = i*CHAR_SET_LEN+char2pos(c)
vector[idx]=1
return vector3.模型
这里采用了3层卷积层来做,每一层加一个Dropout,没有太多新的东西,卷积到现在就是卷积、池化、dropout为一个单元,多加几层而已。
4.跑模型
跑模型这里写了一个get_next_batch的函数,然后代入到sess里面去跑。这里需要说的是keep_pro参数的选择,我查了一下,keep_pro表示保留的比例;模型不再用迭代次数来循环,而是让模型自己跑,看看什么时候能达到预设的准确率,我这里设置的是0.98,而且试了几个keep_pro参数,低于0.75的可以达到,0.75跑了很久都达不到0.98。识别的结果还是比较可观的,试了好几次,都能稳定识别。代码和模型选择附上链接,有需要的自取:https://download.csdn.net/download/wenpeitao/85454673
def get_next_batch(batch_size=128):
batch_x = np.zeros([batch_size,IMAGE_WIDTH*IMAGE_HEIGHT])
batch_y = np.zeros([batch_size,MAX_CAPTCHA*CHAR_SET_LEN])
def wrap_gen_captcha_text_and_image():
while True:
text, image = gen_captcha_text_and_image()
if image.shape==(60,160,3):
return text,image
for i in range(batch_size):
text,image = wrap_gen_captcha_text_and_image()
image = conver2gray(image)
# flatten:eg,turn the [60,160,3]=60*160*3
batch_x[i,:] = image.flatten()/255
batch_y[i,:] = text2vec(text)
return batch_x,batch_y
def train_crack_captcha_cnn():
output = crack_captcha_cnn()
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output,labels=Y))
opt = tf.compat.v1.train.AdamOptimizer(learning_rate=0.001).minimize(loss)
predict = tf.reshape(output,[-1,MAX_CAPTCHA,CHAR_SET_LEN])
max_idx_p = tf.argmax(predict,2)
max_idx_l = tf.argmax(tf.reshape(Y,[-1,MAX_CAPTCHA,CHAR_SET_LEN]),2)
correct_pred = tf.equal(max_idx_p,max_idx_l)
accuracy = tf.reduce_mean(tf.cast(correct_pred,tf.float32))
saver = tf.compat.v1.train.Saver()
with tf.compat.v1.Session() as sess:
sess.run(tf.compat.v1.global_variables_initializer())
step = 0;
while True:
batch_x,batch_y = get_next_batch(64)
accuracy_,loss_,_ = sess.run([accuracy,loss,opt],feed_dict={X:batch_x,Y:batch_y,keep_pro:0.3})
print("step{} loss={} accuracy={}".format(step,loss_,accuracy_))
if accuracy_>0.98:
saver.save(sess,"./model/crack_capcha.model", global_step=step)
break
step+=15。数据预测
跑完了模型就要开始进行数据预测,数据预测我一共用了2个模型结果,分别是keep_pro为0.1和0.75的,并且准确率达到98%。其实所有的数据预测都跟前面模型很相似,区别就是预测时只放入一张图像,然后进行数据处理、转成向量、归一化、卷积,最后预测出它的结果。saver.restore(sess,”./model-keep_pro=0.5/crack_capcha.model-44362″),这句代码就是把跑出来的模型参数重新导入到sess里面,里面包含了w b等各种参数。把模型代入后随机生成一张图片然后进行识别,并且把结果打印出来,如下图所示,结果显示还是很准确的。
import numpy as np
import tensorflow as tf
from captcha.image import ImageCaptcha
import matplotlib.pyplot as plt
from PIL import Image
import random
tf.compat.v1.reset_default_graph()
tf.compat.v1.disable_eager_execution()
number = ['0','1','2','3','4','5','6','7','8','9']
def conver2gray(img):
if len(img.shape)>2:
gray = np.mean(img,-1)
return gray
else:
return img
def random_captcha_text(char_set=number,captcha_size=4):
captcha_text = []
for i in range(captcha_size):
c = random.choice(char_set)
captcha_text.append(c)
return captcha_text
def gen_captcha_text_and_image():
image = ImageCaptcha()
captcha_text = random_captcha_text()
# change captcha_text into string type
captcha_text = ''.join(captcha_text)
captcha = image.generate(captcha_text)
captcha_image = Image.open(captcha)
captcha_image = np.array(captcha_image)
return captcha_text,captcha_image
def crack_captcha_cnn(w_alpha = 0.01,b_alpha = 0.1):
x = tf.reshape(X,shape=[-1,IMAGE_HEIGHT,IMAGE_WIDTH,1])
w_c1 = tf.compat.v1.Variable(w_alpha*tf.compat.v1.random_normal([3,3,1,32]))
b_c1 = tf.compat.v1.Variable(b_alpha*tf.compat.v1.random_normal([32]))
conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x,w_c1,strides=[1,1,1,1],padding='SAME'),b_c1))
conv1 = tf.nn.max_pool(conv1,ksize=[1,2,2,1],strides=[1,2,2,1],padding='SAME')
# conv1 = tf.nn.dropout(conv1,keep_pro)
w_c2 = tf.compat.v1.Variable(w_alpha * tf.compat.v1.random_normal([3, 3, 32, 64]))
b_c2 = tf.compat.v1.Variable(b_alpha * tf.compat.v1.random_normal([64]))
conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2))
conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# conv2 = tf.nn.dropout(conv2, keep_pro)
w_c3 = tf.compat.v1.Variable(w_alpha * tf.compat.v1.random_normal([3, 3, 64, 64]))
b_c3 = tf.compat.v1.Variable(b_alpha * tf.compat.v1.random_normal([64]))
conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3))
conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# conv3 = tf.nn.dropout(conv3, keep_pro)
w_d = tf.compat.v1.Variable(w_alpha * tf.compat.v1.random_normal([8*32*40, 1024]))
b_d = tf.compat.v1.Variable(b_alpha * tf.compat.v1.random_normal([1024]))
dense = tf.reshape(conv3,[-1,w_d.get_shape().as_list()[0]])
dense = tf.nn.relu(tf.add(tf.matmul(dense,w_d),b_d))
# dense = tf.nn.dropout(dense,keep_pro)
w_out = tf.compat.v1.Variable(w_alpha * tf.compat.v1.random_normal([1024,MAX_CAPTCHA*CHAR_SET_LEN]))
b_out = tf.compat.v1.Variable(b_alpha * tf.compat.v1.random_normal([MAX_CAPTCHA*CHAR_SET_LEN]))
out = tf.add(tf.matmul(dense,w_out),b_out)
return out
def crack_captcha(captcha_image):
output = crack_captcha_cnn()
saver = tf.compat.v1.train.Saver()
with tf.compat.v1.Session() as sess:
saver.restore(sess,"./model-keep_pro=0.5/crack_capcha.model-44362")
# saver.restore(sess, "./model-810/crack_capcha.model-810")
predict = tf.argmax(tf.reshape(output,[-1,MAX_CAPTCHA, CHAR_SET_LEN]),2)
text_list = sess.run(predict,feed_dict={X:[captcha_image]})
text = text_list[0].tolist()
return text
if __name__ == '__main__':
number = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9']
# alphabet = ['a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i', 'j', 'k', 'l', 'm', 'n', 'o', 'p', 'q', 'r', 's', 't', 'u',
# 'v', 'w', 'x', 'y', 'z']
# ALPHABET = ['A', 'B', 'C', 'D', 'E', 'F', 'G', 'H', 'I', 'J', 'K', 'L', 'M', 'N', 'O', 'P', 'Q', 'R', 'S', 'T', 'U',
# 'V', 'W', 'X', 'Y', 'Z']
text,image = gen_captcha_text_and_image()
f = plt.figure()
ax = f.add_subplot(111)
ax.text(0.1,0.9,text,ha='center',va='center',transform=ax.transAxes)
plt.imshow(image)
plt.show()
IMAGE_HEIGHT = 60
IMAGE_WIDTH = 160
MAX_CAPTCHA = len(text)
char_set = number
CHAR_SET_LEN = len(char_set)
X = tf.compat.v1.placeholder(tf.float32,[None,IMAGE_WIDTH*IMAGE_HEIGHT])
Y = tf.compat.v1.placeholder(tf.float32,[None,MAX_CAPTCHA*CHAR_SET_LEN])
# keep_pro = tf.compat.v1.placeholder(tf.float32)
image = conver2gray(image)
image = image.flatten()/255
pre_text = crack_captcha(image)
print("correct:{} predict:{}".format(text,pre_text))
print('------------message------------')
print('run successfully')

文章出处登录后可见!