在特征提取领域,近似熵、样本熵、排列熵和模糊熵是比较经常出现的概念。
首先一句话总结一下:这几个熵值都是用来表征信号序列复杂程度的无量纲指标,熵值越大代表信号复杂度越大。信号复杂程度的表征在机械设备状态监测、故障诊断以及心率、血压信号检测中都十分有用;能够抵抗环境干扰的影响,广泛应用于特征提取的领域当中。
从本篇开始,将依次介绍上述几个熵特征的概念和靠谱的MATLAB代码实现。
今天从近似熵开始。
一、近似熵
近似熵(Approximate Entropy,ApEn)概念最早是由 Steven M. Pincus 于 1991年从衡量信号序列复杂性的角度提出的[1],用于度量信号中产生新模式概率的大小,越复杂的时间序列对应的近似熵越大,越规则的时间序列对应的近似熵则越小。
近似熵的计算也可理解为求取一个时间序列在模式上的自相似程度。对于一个信号序列的变化,可以利用近似熵值的改变达到有效识别的目的。近似熵的计算最大的优点是不需要很长的数据量,多数实测的时间序列都能够满足要求,得到的结果稳健可靠 [2]。
1.1 近似熵的含义[2]
下面相对形象但不那么严谨地解释一下近似熵的含义。
假设待分析信号序列为x(1),x(2),…,x(N)。
(1)【序列定义】给定模式维数m,可以构造出一组m维矢量:
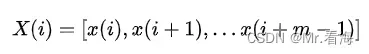
其中i=1~N-m+1,通常m取2,当m取2的时候:
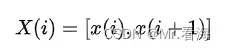
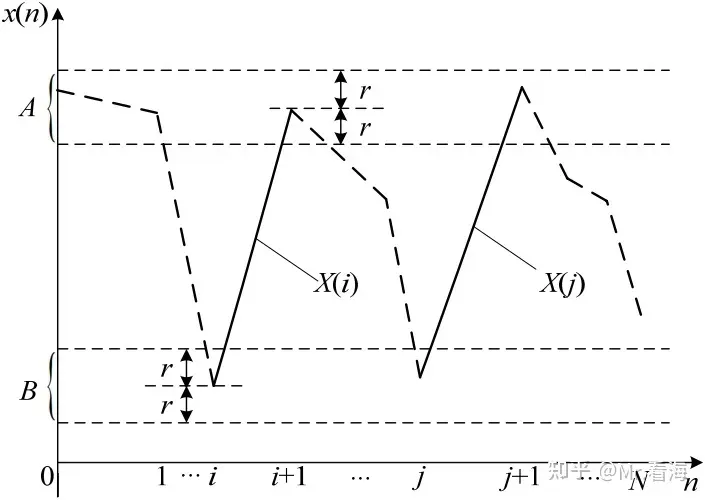
近似熵的物理本质
(2)【近似的含义】上图中的折线是待分析信号(m取2),X(i)和X(j)是图中实线部分。
X(i)的端点处设置一个相似容限阈值r,图中A、B区间分别表示x(i)和x(i+1)的容限范围,如果X(j)的对应端点都在容限范围内,则认为2维特征向量X(i)和X(j)的模式在r下近似。
在确定的i值下,遍历所有的X(i)和X(j)的组合(包括i与j相等的情况,总共会有N-m+1种),记录出近似的数量。
(3)【近似比例】将近似数量与总数量的比值记为 ![]()
(4)此时再求得: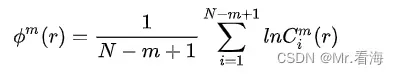
(5)将维数加1变为m+1,重复以上步骤,得到 ![]()
(6)【近似熵】求得信号序列的近似熵为: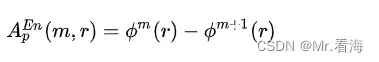
上式中m通常取2,r通常取(0.1~0.25)SD(x),其中SD(x)代表信号序列的标准差。
1.2 近似熵的特点
结合近似熵的数学定义可见,近似熵的物理本质就是衡量当维数变化时信号序列中新模式出现的对数条件概率均值,因此理论上近似熵在表征信号序列的不规则性和复杂性方面具有较大的意义。需要指出的是,在实际应用中,我们更关注的是各信号近似熵值的 相对大小。
① 近似熵具有较好的抗噪及抗干扰的能力。因为产生这类干扰的数据点所具有的独特性,使得这些数据点与相邻点所构成的线段与x(i)的距离较远,容限阈值r 使得这些干扰点得到有效去除。
② 近似熵的分析效果比均差、方差、标准差等统计算法 更加有效,因为近似熵保留了原始信号序列中的时间序列信息,反映了信号序列在结构分布上的特性。这一特性使得近似熵测度能够更加准确有效地提取出故障信号中的特征信息。
③ 近似熵只需要较少的数据点,就可达到对信号序列从统计性角度描述的目的。
④ 近似熵分析具有较强的通用能力,可用于随机信号、确定性信号以及两者的混合所组成的信号。
1.3 近似熵的参数选择
近似熵在计算之前我们需要对影响近似熵值大小的3个参数m 、r 、N 来进行确定。
1) m的选择。m可以被称之为模式维数,它是用来计算近似熵的时序列的窗口长度。在一般情况下,选择m=2会优于m=1,因为在序列的联合概率在动态重构时候,就会有更多的信息。我们一般不会选择m>2 ,因为在m>2 时,N就应该在数千个点之上,然而我们一般不会让N大于5000,因为当N大于5000时,就不能确保事物的状态有相同的性质;相反,在N选定之后,在m>2的情况下,同时我们还想获得比较理想的结果下,r就必须较大,在分析想要得到的序列的分布就会不得不失去很多信息。因此,我们通常选择m=2 。
2) r的选择。r即相似容限阈值。当r的值较大时,会丢失较多的信息,而当r的值较小时,又会不能理想的估计出系统的统计特性。在经过Pincus等人的不懈努力,总结得到当r 在0.1和0.25SD(x)(SD(x)是序列的标准差)之间, ApEn有比较合理的统计特性。
3) N的选择。Pincus等人通过大量的实验表明,对于给定的数据,一般输入点数要控制在100到5000这个范围内才能保证会有有效的统计特性以及较小的误差。
1.4 近似熵算法的局限性
第一点。简单地说,上边第(2)步中求X(i)和X(j)的近似时,是将自身数据段也算在其中了,比如X(1)和X(1)之间必然是相似的,而这一个相似也被计入到近似的总数量当中了,这样做是为了避免![]() 等于0的情况,而ln0显然是没有意义的。但是,将自身数据段引入到计算当中又不可避免地会带来计算偏差。
等于0的情况,而ln0显然是没有意义的。但是,将自身数据段引入到计算当中又不可避免地会带来计算偏差。
第二点。上边讲到了,当数据长度N在100-5000的范围内近似熵才可以得到有效的计算结果,也就是说计算样本熵值收到数据长度制约,这也限制了该算法的使用范围。
因此其后研究者们又提出了不同的改进方法,这就是后边的文章要讲的了。
2.MATLAB代码实现
近似熵的代码有两个源头,一个是matlab2018a以上版本内置了approximateEntropy函数;另外一个是网上流传的ApproximateEntropy.m函数文件。这两个代码笔者做了对比和测试,运行结果是相同的。
在此笔者采用了后者,因为这个函数实现并不是十分复杂,我在这个代码上逐行添加了注释,并与上述文章中的算法步骤做了对照讲解。我将其命名为kApproximateEntropy,如下:

为了特征提取代码的易用性,笔者对一系列熵特征提取进行了封装,包括上边添加注释的代码都集中到一起。由于搞科研写论文时,对特征提取的需要往往是集中性的、多种类的、需求各异的,所以我把之前介绍过的熵特征值和后边将会降到的集中熵特征进行了打包:
熵特征值共7个——功率谱熵、奇异谱熵、能量熵、 近似熵、样本熵、排列熵、模糊熵
以上7种全都集中到一个封装函数里,实现一行代码完成特征提取。
比如提取数据“近似熵”就可以像这样写:
fea = genFeatureEn(data,{'ApEn'}) %对data求近似熵如果提取数据“功率谱熵、奇异谱熵、能量熵、近似熵、样本熵、排列熵、模糊熵”这全部7种特征,就可以这样写:
fea =genFeatureEn(data,{'psdE','svdpE','eE', 'ApEn', 'SpEn','PeEn','FuzzyEn'});
%调用genFeature函数,完成特征提取,算出的特征值会保存在fea变量里也就是说需要提取哪个特征,在函数中直接指定就可以了。输出的fea变量里就会得到相应的这些特征值,顺序也是与输入的排序保持一致的。
这个函数的介绍如下:
function fea = genFeatureEn(data,featureNamesCell,options)
% 熵相关算法的信号特征提取函数
% 输入:
% data:待特征提取的时域信号,可以是二维数据,维度为m*n,其中m为数据组数,n为每组数据的长度。即每行数据为一组。行列方向不可出错
% options:其他设置,使用结构体的方式导入。目前可设置变量包括:
% -svdpEn:即奇异值的窗口长度。
% -Apdim:近似熵参数,Apdim为近似熵的模式维度
% -Apr:近似熵参数,Apr为近似熵的阈值
% -Spdim:样本熵参数,Spdim为样本熵的模式维度
% -Spr:Spr为样本熵的阈值
% -Fuzdim:模糊熵参数,Fuzdim为模糊熵模式维度
% -Fuzr:模糊熵参数,Fuzr为模糊熵的阈值
% -Fuzn:模糊熵参数,Fuzn为模糊熵权重
% -Pedim:排列熵参数,Pedim为排列熵模式维度
% -Pet:排列熵参数,Pet为排列熵的时间延迟
% featureNamesCell:拟进行特征提取的特征名称,该变量为cell类型,其中包含的特征名称为字符串,特征名称需要在下边列表中:
% 目前支持的特征(2022.5.23,共7种):
% psdE:功率谱熵
% svdpE:奇异谱熵
% eE:能量熵
% ApEn:近似熵
% SampleEn:样本熵
% FuzzyEn:模糊熵
% PerEn:排列熵
%
% 输出:
% fea:数据data的特征值数组,其特征值顺序与featureNamesCell一一对应
% 需要上边这个函数文件以及测试代码的同学,可以在下面链接获取:
3.其他:时域、频域特征提取的MATLAB代码实现
除了上述熵特征的提取,笔者还对之前文章中讲到过的时域和频域特征进行了代码实现,具体包括:
有量纲特征值8个——最大值、最小值、峰峰值、均值、方差、标准差、均方值、均方根值(RMS)
无量纲特征值6个——峭度、偏度、波形因子、峰值因子、脉冲因子、裕度因子
频域特征值5个——重心频率、均方频率、均方根频率、频率方差、频率标准差
谱峭度特征4个——谱峭度的均值、谱峭度的标准差、谱峭度的偏度、谱峭度的峭度
以上23种全都集中到一个封装函数里,实现一行代码完成特征提取。
比如提取数据“重心频率”就可以像这样写:
fea = genFeatureTF(data,{'FC'}) %对data数据求重心频率如果提取数据“最大值、最小值、峰峰值、均值、方差、标准差、均方值…”这全部22种特征,就可以这样写:
fea =genFeatureTF(data,{'max','min','mean','peak','arv','var','std','kurtosis',...
'skewness','rms','waveformF','peakF','impulseF','clearanceF',...
'FC','MSF','RMSF','VF','RVF',...
'SKMean','SKStd','SKSkewness','SKKurtosis'}); %调用genFeature函数,完成特征提取,算出的特征值会保存在fea变量里也就是说需要提取哪个特征,在函数中直接指定就可以了。输出的fea变量里就会得到相应的这些特征值,顺序也是与输入的排序保持一致的。
这个函数的介绍如下:
function fea = genFeatureTF(data,fs,featureNamesCell)
% 时域、频域相关算法的信号特征提取函数
% 输入:
% data:待特征提取的时域信号,可以是二维数据,维度为m*n,其中m为数据组数,n为每组数据的长度。即每行数据为一组。行列方向不可出错
% fs:采样频率,如果不提取频域特征,fs值可以设置为1
% featureNamesCell:拟进行特征提取的特征名称,该变量为cell类型,其中包含的特征名称为字符串,特征名称需要在下边列表中:
% 目前支持的特征(2022.5.23,共23种):
% max :最大值
% min :最小值
% mean :平均值
% peak :峰峰值
% arv :整流平均值
% var :方差
% std :标准差
% kurtosis :峭度
% skewness :偏度
% rms :均方根
% waveformF :波形因子
% peakF :峰值因子
% impulseF :脉冲因子
% clearanceF:裕度因子
% FC:重心频率
% MSF:均方频率
% RMSF:均方根频率
% VF:频率方差
% RVF:频率标准差
% SKMean:谱峭度的均值
% SKStd:谱峭度的标准差
% SKSkewness:谱峭度的偏度
% SKKurtosis:谱峭度的峭度
%
% 输出:
% fea:数据data的特征值数组,其特征值顺序与featureNamesCell一一对应需要上边这个函数文件以及测试代码的同学,可以在下边链接中获取:
上述2个函数(熵特征提取函数“genFeatureEn”和时频特征提取函数“genFeatureTF”)会持续更新,有哪些想要加进去的特征指标,同学们可以在评论区留言,笔者会考虑纳入到这个“特征提取指标全家桶”中。
参考
- ^[1]Pincus, S. M . Approximate entropy as a measure of system complexity.[J]. Proceedings of the National Academy of Sciences of the United States of America, 1991, 88(6):2297-2301.
- ^ab[1]沈刚. 基于近似熵分析和小波变换的IGBT模块键合线故障特征分析[D]. 重庆大学.
文章出处登录后可见!