可解释机器学习:黑盒模型可解释性理解指南
作者: 【德】 Christoph Molnar
出版社: 电子工业出版社
译者: 朱明超英文版(作者在持续更新):Interpretable Machine Learning
原书github:GitHub – christophM/interpretable-ml-book: Book about interpretable machine learning
注意:原书使用R语言,本文的Python代码为我自己开发。内容基本参考原书,我进行了结构调整,并且添加了自己的理解和其他书籍的知识。
本案例模型简述
模型:最基础的多元线性归回
特征选择:无
特征交互:无
本案例数据集简述
目标变量:自行车租赁量,连续型,因此为回归问题
分类特征处理方式: 进行one-hot编码,其中未出现的取值(例如春、晴)作为参照类别
连续特征处理方式:使用原始值(不进行标准化和归一化)
目录
线性回归介绍
1.线性:线性回归的最大优势(使其为可解释模型),也是它最大的劣势。线性方程在模块化水平(即权重)上有易于理解的解释,并且权重带有置信区间(权重范围的估计)。如怀疑有特征交互项或特征与目标呈非线性关系,则可考虑添加交互项或使用回归样条。
2.正态性:假设目标结果服从正态分布,如违反,则特征权重的估计置信区间无效。
3.同方差性:假设误差项的方差在整个特征空间内是恒定的。这种假设经常与现象相违背。比如预测房价,预测大别墅时的价格波动空间比普通两居室更大。
4.独立性:每个实例独立于其他实例。不独立的情况举例:对每个患者进行重复测量,此时可使用混合效应模型或广义估计方程。
5.固定特征:指的是输入的特征值没有测量误差。
6.不存在多重共线性:强相关特征会扰乱对权重的估计和解释(但这通常不会影响模型)。举例:房子面积和房间数量是强相关的,回归的结果可能是房子面积和房价的正相关,但是房间数量和房价负相关。
第一节.准备数据集
数据集地址:UCI Machine Learning Repository: Bike Sharing Dataset Data Set
原始数据集:

按照作者的处理方式,对数据集用python进行处理,数据处理要点:
①未使用全部特征。
②分类变量(季节、天气情况)进行one-hot编码,其中未出现的取值(春、晴)作为参照类别。
③原始数据集中的温度、湿度、风速进行了标准化和归一化,本次处理时将取值恢复了原始值。
④链接中的原始数据集修正过季节,但是为了和书上的数据相对应,我使用了旧版的数据集,因此后续对季节的解释可能不符合实际情况。
import numpy as np
import pandas as pd
import time #统计运行时间用
import copy #深拷贝的时候用
import _pickle as cPickle
import gc #释放内存使用
import datetime #处理时间数据
import os
from sklearn.preprocessing import OneHotEncoder
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus']=False #用来正常显示负号
import seaborn as sns
%matplotlib inline
import warnings
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.filterwarnings("ignore")
pd.set_option('display.max_columns',100)
pd.set_option('max_colwidth',100)
# OneHotEncoder:Encode categorical features as a one-hot numeric array(aka 'one-of-K' or 'dummy')
#Reshape your data either using array.reshape(-1, 1) if your data has a single feature or array.reshape(1, -1) if it contains a single sample.
#1.对特征进行独热编码(可以是'one-of-K' or 'dummy'),适用于无序的类别特征。如果对标签进行编码则使用LabelBinarizer
#2.sparse : bool, default=True,默认为稀疏矩阵形式
#3.可以通过参数handle_unknown规定fit中未出现但是transform中出现的值进行'ignore'
#4.可以通过参数categories指定需要保留的取值(指定后可以通过ohe.categories_查看)
#5.灵活使用drop参数,控制如何drop掉多余的列
#更多信息参见ohe?
def f_ohe(df,col,new_names=None,keep_cate='auto'):
'''
【功能】对一个特征进行独热编码
【参数】df:dataframe,数据集
col:str,需要进行独热编码的特征名
new_names: dic,如果需要对取值重命名(使特征名更能表达真实意思),则新建一个字典,默认None则特征名为col_取值
keep_cate: list,需要保留的取值,如果取值是数值型则需要先排序,例如[1,3,4];默认'auto'表示保留所有值
【返回】dataframe
【举例】t=f_ohe(df=bike,col='season',new_names={1:'winter',3:'summer',4:'fall'},keep_cate=[1,3,4])
'''
ohe=OneHotEncoder(dtype=np.int8,handle_unknown='ignore',sparse=False,categories=[keep_cate])
ohe.fit(df[col].values.reshape(-1,1))
tmp=pd.DataFrame(ohe.transform(df[col].values.reshape(-1,1)))
org_names=ohe.get_feature_names_out([col]).tolist() #col作为新生成字段的前缀
if new_names is None:
tmp.columns=org_names
else:
new_names_keys=list(new_names.keys()) #获取输入的keys
new_names_keys=[col+'_'+str(item) for item in new_names_keys] #输入的keys加上col前缀
# print(new_names_keys)
new_names=dict(zip(new_names_keys,list(new_names.values()))) #加上前缀的keys和输入的values重新打包为字典
# print(new_names)
a=list(pd.Series(data=org_names).map(new_names).values) #list不能直接map,把原特征名map转为Series后映射为新特征名
tmp.columns=[col+'_'+str(item) for item in a] #加上col前缀
return tmp
path='../data/'
#原始数据集
bike=pd.read_csv(path+'Bike-Sharing-Dataset/day.csv',parse_dates=['dteday'])
#目前下载的原始数据,季节被更新了,无法与作者书中的数字保持一致,因此导入旧数据集
bike_oldseason=pd.read_csv(path+'Bike-Sharing-Dataset/bike_oldseason.csv' )
bike['season']=bike_oldseason['season'].map({'WINTER':1,'SPRING':2,'SUMMER':3,'FALL':4})
bike.head()
#添加特征days_since_2011,自数据集中第一天(20110101)起的天数),引入此特征为了考虑随时间变化的趋势
bike['days_since_2011']= (bike['dteday']-min(bike['dteday'])).dt.days
#原始数据集中的几个特征进行了标准化,这里还原到原始值
# denormalize weather features:
# temp : Normalized temperature in Celsius. The values are derived via (t-t_min)/(t_max-t_min), t_min=-8, t_max=+39 (only in hourly scale)
bike['temp'] = bike['temp'] * (39 - (-8)) + (-8)
# windspeed: Normalized wind speed. The values are divided to 67 (max)
bike['windspeed'] = 67 * bike['windspeed']
# hum: Normalized humidity. The values are divided to 100 (max)
bike['hum'] = 100 * bike['hum']
#保留的特征:租赁数量cnt(目标变量),季节,是否假期(1是,0不是),是否工作日(1是,0不是),天气情况(晴、雾、雨雪),温度(单位为℃),湿度(相对湿度百分比0~100%),风速(单位为km/h),天数
select_cols=['cnt','season','holiday', 'workingday', 'weathersit', 'temp', 'hum', 'windspeed', 'days_since_2011']
bike=bike[select_cols]
bike.to_csv(path+'处理完数据集/bike.csv',index=False,encoding='utf_8_sig')
#对于取值有两类的特征(是否假期holiday、是否工作日workingday),由于本身已是0/1编码,因此不作进一步处理
#对于取值>2类的特征(季节season、天气情况weathersit),进行one-hot编码
#季节,以春(取值2)作为参照类别,参照类别不保留
t_season=f_ohe(df=bike,col='season',new_names={1:'冬',3:'夏',4:'秋'},keep_cate=[1,3,4])
t_season
#天气情况,以晴天(取值1)作为参照类别,参照类别不保留
t_weathersit=f_ohe(df=bike,col='weathersit',new_names={2:'雾',3:'雨雪'},keep_cate=[2,3])
t_weathersit
bike_ohe=pd.concat((bike[['cnt','holiday', 'workingday', 'temp', 'hum', 'windspeed', 'days_since_2011']],
t_season,t_weathersit),axis=1)
bike_ohe
bike_ohe.to_csv(path+'处理完数据集/bike_ohe.csv',index=False,encoding='utf_8_sig')数据处理结果如下图:
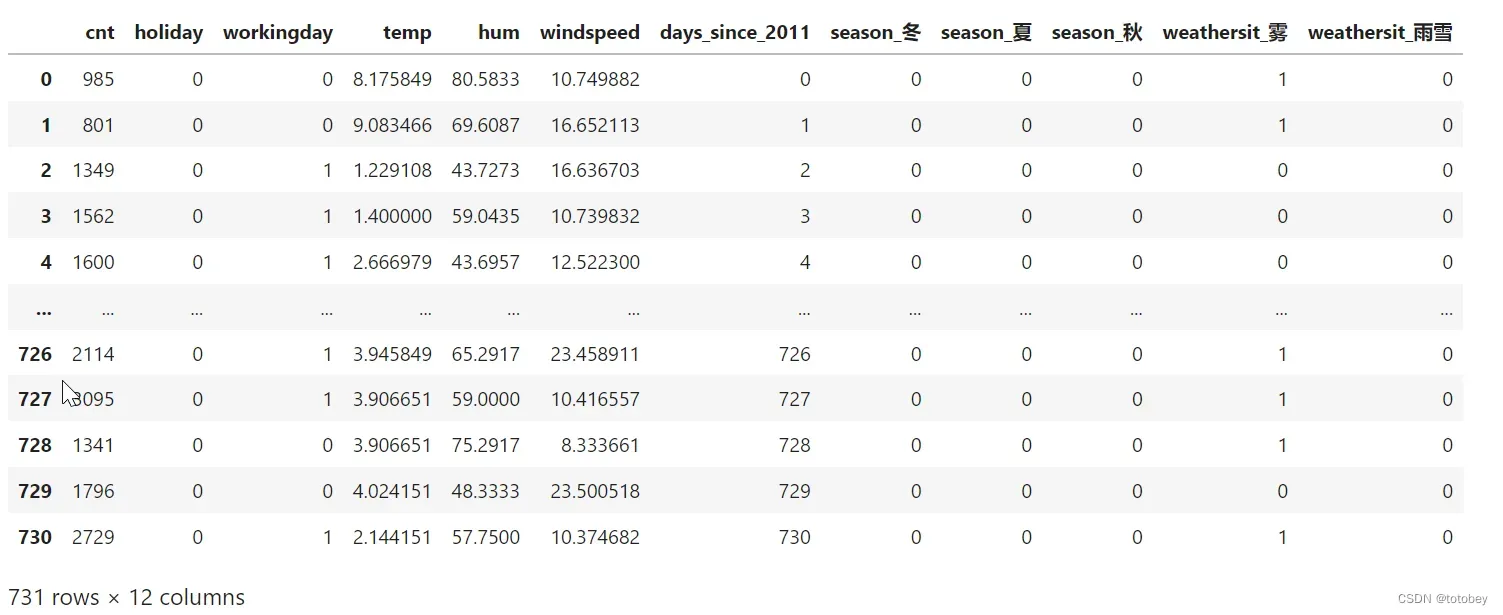
每一行代表某一天的情况。
cnt:自行车租赁数量(目标变量)
holiday:是否假期(1是,0不是)
workingday:是否工作日(1是,0不是),除了假期和双休日的为工作日
temp:温度(单位为℃)
hum:湿度(相对湿度百分比0~100%)
windspeed:风速(单位为km/h)
days_since_2011:自数据集中第一天(20110101)起的天数,引入此特征为了考虑随时间变化的趋势
season_冬、season_夏、season_秋:季节特征(1是,0不是),其中春未出现,可由其他三个季节推知,将春作为参照类别
weathersit_雾、weathersit_雨雪:天气特征(1是,0不是),其中晴未出现,可由其他两个天气情况推知,将晴作为参照类别
第二节.验证数据是否满足某些假设
1.线性:可先不用管。根据基础线性模型建立后的R方判断预测效果。后续如有需要可对基础线性模型进行改造(如添加交互项、使用回归样条等)。
2.正态性:本节对目标变量的正态性进行了检验,检验通过。
3.同方差性:必须建模后再判断,此时无法判断。
4.独立性:除了特殊情况(比如对同一人进行重复测量),一般可认为实例之间相互独立。
5.固定特征:测量无误差,一般都可认为是固定特征。
6.不存在多重共线性:本节进行了检验,检验通过。虽然同时计算了相关系数和VIF,但实践时可以直接以VIF的结论为准。
下面提供检验多重共线性和正态性的代码:
df=bike_ohe
label='cnt'
feas=df.columns.tolist()
feas.remove(label)
print('特征数量:',len(feas))
X_train=df[feas]
y_train=df[label]
print('X_train:',X_train.shape)
print('y_train:',y_train.shape)
1.判断共线性
(强相关特征会扰乱对权重的估计和解释(但这通常不会影响模型))
1.1.计算相关系数(只能判断两两的线性关系)
#1.1.计算相关系数(只能判断两两的线性关系)
import matplotlib.pyplot as plt
import seaborn as sns
corr_res=X_train.corr()
plt.subplots(figsize=(9, 9))
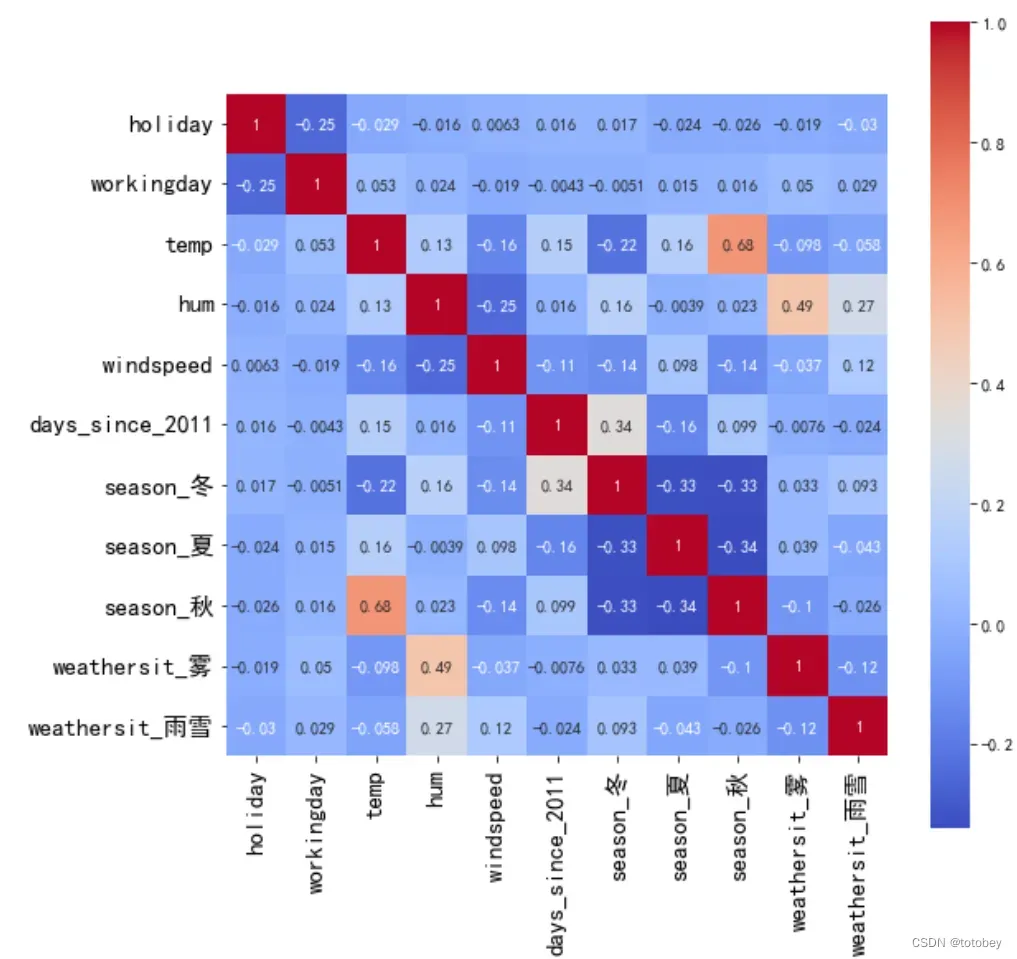
sns.heatmap(corr_res, annot=True, vmax=1, square=True, cmap="coolwarm")
plt.xticks(fontsize=15) #放大横纵坐标刻度线上的特征名字体
plt.yticks(fontsize=15)
plt.show()如下图,绝对值最大的相关系数是秋和温度(0.68),可接受。
1.2.计算方差膨胀因子(可以判断三个或更多变量之间的线性关系)
# 1.2.计算方差膨胀因子(可以判断三个或更多变量之间的线性关系)
from statsmodels.stats.outliers_influence import variance_inflation_factor #计算方差膨胀因子
from statsmodels.tools.tools import add_constant #添加常量
def checkVIF(df):
'''
【功能】计算方差膨胀因子
【参数】df:dataframe,特征集(不含target)
【返回】dataframe,展示各个特征的VIF
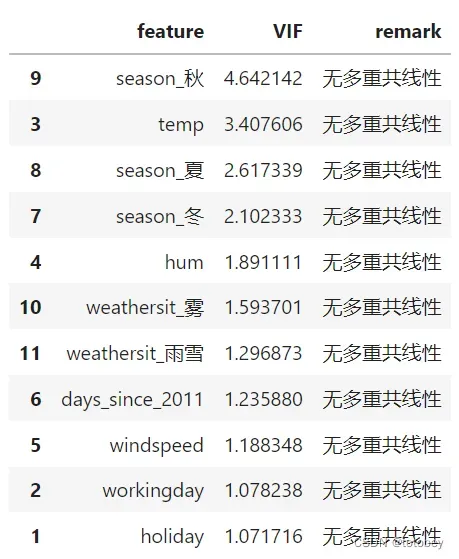
【参考】当0<VIF<10,不存在多重共线性;当10≤VIF<100,存在较强的多重共线性;当VIF≥100,存在严重多重共线性。
【来源与介绍】https://blog.csdn.net/nixiang_888/article/details/122342338
【举例】VIF1=checkVIF(X_train)
'''
df = add_constant(df) #添加一列常量const作为截距,全部赋值为1(不会改变原数据集)
name = df.columns
x = np.matrix(df)
VIF_list = [variance_inflation_factor(x,i) for i in range(x.shape[1])]
VIF = pd.DataFrame({'feature':name,"VIF":VIF_list})
VIF = VIF.drop(index=0) #删除截距const行
VIF.sort_values(['VIF'],ascending=False,inplace=True)
VIF['remark']=np.where(VIF['VIF']>=100,'严重多重共线性',np.where(VIF['VIF']>=10,'较强多重共线性','无多重共线性'))
return VIF
VIF1=checkVIF(X_train)
VIF1结果如下图,不存在多重共线性。
2.判断正态性
(假设目标结果服从正态分布,如违反,则特征权重的估计置信区间无效 )
def checkNORM(se,p=0.05,alt='two-sided',if_plot=True):
'''
【功能】检验一组数据是否符合正态分布
【参数】se:Series
p:float,p值,默认0.05
alt:str,默认双侧检验'two-sided',可选'less', 'greater'
if_plot,是否画图,默认True
【返回】dataframe,展示各个特征的VIF
【参考】结果返回两个值:statistic → D值,pvalue → P值
【备注】import matplotlib.pyplot as plt
%matplotlib inline
【举例】 res=checkNORM(y_train)
'''
from scipy import stats
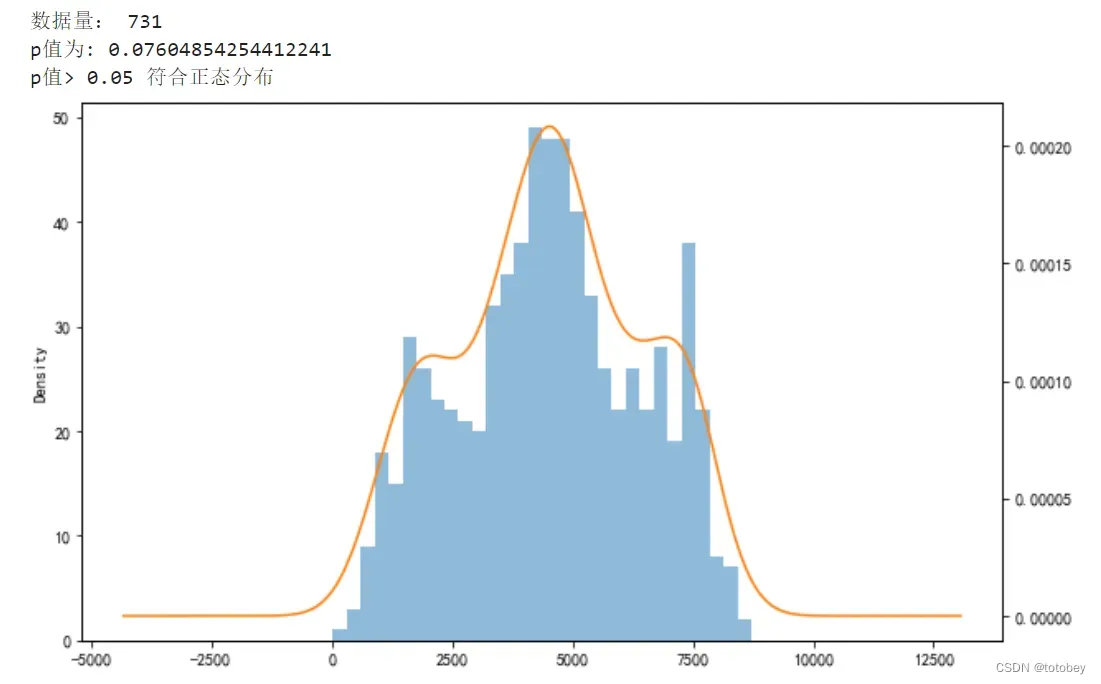
print('数据量:',len(se))
u = se.mean() # 计算均值
std = se.std() # 计算标准差
res=stats.kstest(rvs=se, cdf='norm',args= (u, std), alternative=alt)
print('p值为:',res[1])
if res[1]>p:
print('p值>',p,'符合正态分布')
else:
print('p值<=',p,'不符合正态分布')
if if_plot==True:
fig = plt.figure(figsize = (10,6))
se.hist(bins=30,alpha = 0.5) #直方图 alpha表示透明度
se.plot(kind = 'kde', secondary_y=True) #核密度估计KDE
plt.show()
return res
res=checkNORM(y_train)结果如下图,符合正态分布。
第三节.建模和解释
本案例的基础线性模型可以选择使用1)statsmodels库,2)sklearn库。其中statsmodels库的信息更多、更全。
本文先用statsmodels库进行详细解释,文末提供sklearn库的代码。
from statsmodels.regression.linear_model import OLS,GLS #Ordinary least squares普通最小二乘法
import statsmodels.formula.api as smf
import statsmodels.api as sm
#cnt为目标变量,分类特征使用C(season_夏)
model=smf.ols(formula='cnt ~ C(season_夏) + C(season_秋) + C(season_冬) + C(holiday) + C(workingday) + C(weathersit_雾) + C(weathersit_雨雪) + temp + hum + windspeed +days_since_2011 ',data=df)
results=model.fit()
results.summary()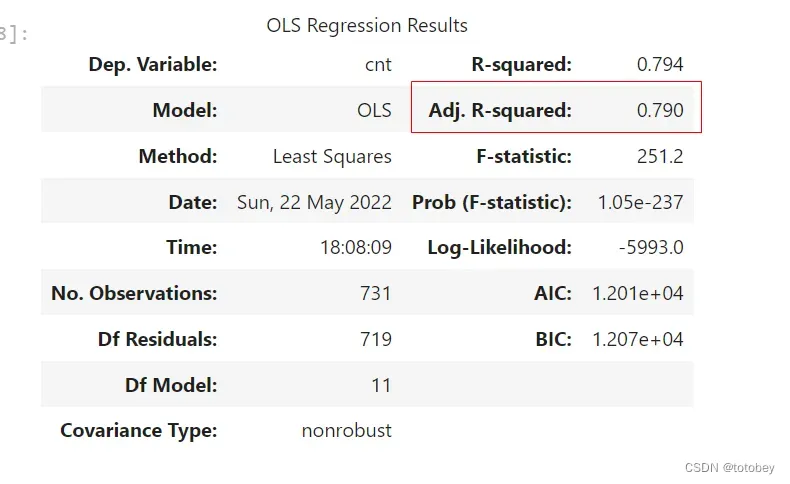
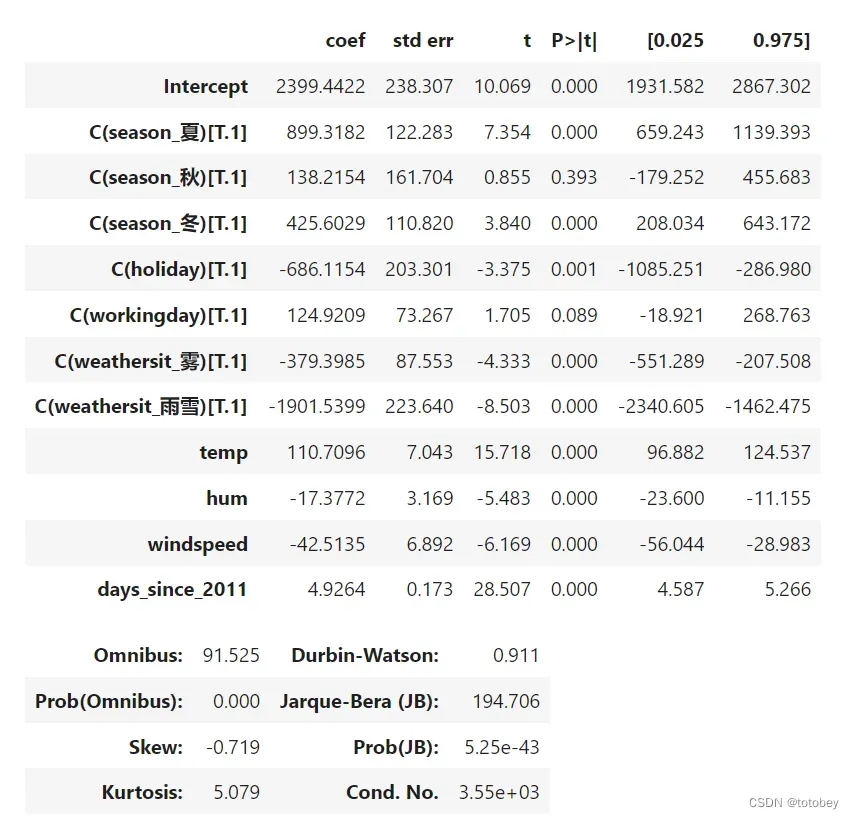
在进行解释前,进行一些说明。
第一,将权重表的值组合为一个DataFrame
df_coef=pd.DataFrame(results.params ) #权重
df_coef.reset_index(inplace=True)
df_coef.columns=['feature','coef']
df_coef['lw']=results.conf_int(alpha=0.05)[0].values #获取权重的置信区间下限
df_coef['up']=results.conf_int(alpha=0.05)[1].values #获取权重的置信区间上限
df_coef['SE']=results.bse.values #权重的标准差std err
df_coef['t']=results.tvalues.values #权重的t统计量,等于权重/标准差
df_coef['p']=results.pvalues.values #参数的t统计的双尾 p 值
df_coef['t_abs']=abs(df_coef['t']) #求绝对值
#根据已有的权重和置信区间计算上下误差,计算完毕后发现上下误差相同
df_coef['lw_err']=df_coef['coef']-df_coef['lw']
df_coef['up_err']=df_coef['up']-df_coef['coef']
df_coef
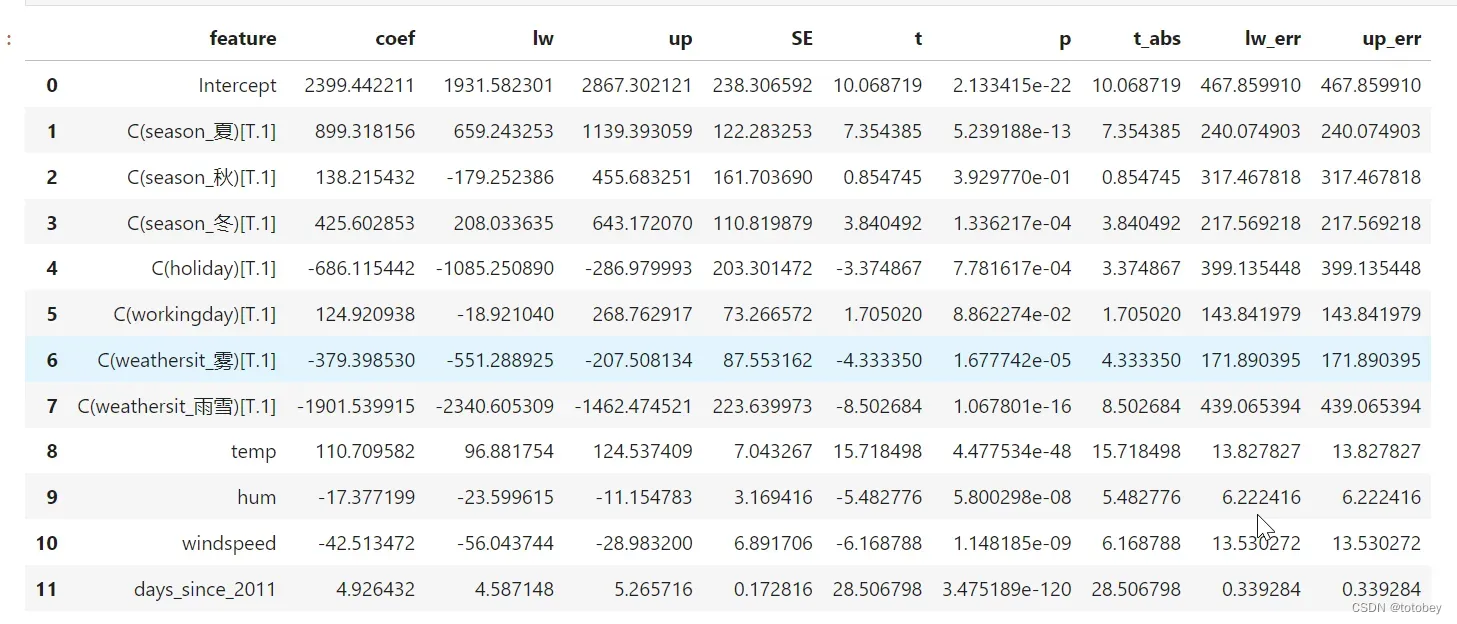
第二, 如何获取实例的真实值、预测值、置信区间,并画图
#获取置信区间的上下限
pred_ols = results.get_prediction()
iv_l = pred_ols.summary_frame()["obs_ci_lower"]
iv_u = pred_ols.summary_frame()["obs_ci_upper"]
#results.fittedvalues为模型预测值
target_df=pd.concat((y_train,results.fittedvalues,iv_l,iv_u),axis=1)
target_df.columns=['true','predict','ci_lower','ci_upper']
target_df
#按实际租赁量排序,reset_index是必须的
plot_df=target_df.sort_values(['true']).reset_index(drop=True)
fig, ax = plt.subplots(figsize=(20, 9))
ax.plot(plot_df['true'], "b-", label="True")
ax.plot(plot_df['predict'], "r", label="Pred")
# ax.plot(plot_df['ci_lower'], "r--",alpha=0.5) #置信区间虚线
# ax.plot(plot_df['ci_upper'], "r--",alpha=0.5) #置信区间虚线
plt.fill_between(plot_df.index,plot_df['ci_lower'],plot_df['ci_upper'],color='blue',alpha=0.15)
ax.legend(loc="best")
plt.ylabel('自行车租赁量',fontsize=18)
plt.title('真实值与预测值对比',fontsize=20)
plt.show()
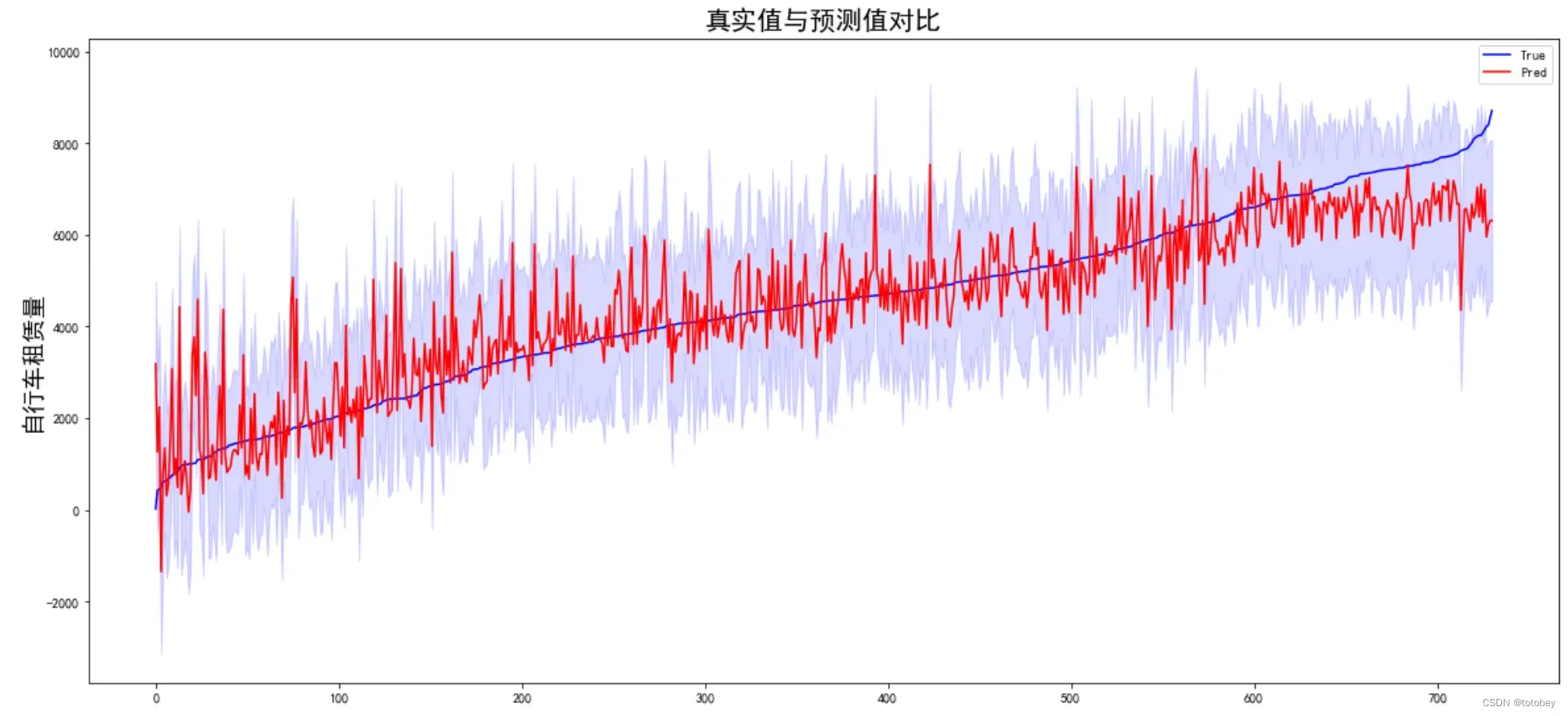
上图中,蓝线为真实值,红色实线为预测值,蓝紫色为置信区间。
由上图可知,左侧租赁量较小时,部分预测值远高于真实值且波动较大;右侧租赁量较大时,预测值整体偏低。
由此图也可以看出,前文中提到的线性回归模型的【同方差性】在现实中是很难满足的。
本案例数据量较小,如果数据量较大,可以随机抽样后再画图。
下面进行模型解释。
第一步:观察模型拟合效果。
观察调整后R方(解释一个该值很低的模型是没有意义的,对权重的任何解释都没有意义)。
该模型的调整后R方是0.790,表示该模型解释了目标结果79%的总方差,拟合度较优,可解释程度较高。
第二步:用文本解释特征权重(数值型和分类型有不同的文本模板)。
数值特征文本模板:当所有其他特征保持不变时,特征x增加一个单位,则预测结果y增加β。
分类特征文本模板:当所有其他特征保持不变时,将特征x从参照类别改变为其他类别时,预测结果y会增加β。
观察权重(图中coef列)(由于本数据集使用了原始值,即未进行标准化和归一化,因此可以直接进行表述):
温度(数值特征):当所有其他特征保持不变时,将温度升高1℃,自行车的预测数量增加110辆。
风速(数值特征):当所有其他特征保持不变时,风速增加1km/h,自行车的预测数量减少42辆。
天气情况(分类特征):所有其他特征保持不变,雨雪天气的自行车的预测数量比晴天减少了1901辆;天气为雾时,自行车的预测数量比晴天减少了379辆。
季节(分类特征):所有其他特征保持不变,夏天自行车的预测数量比春天增加了899辆,秋天自行车的预测数量比春天增加了138辆,冬天自行车的预测数量比春天增加了425辆。
是否假期(分类特征):所有其他特征保持不变,假期的自行车预测数量比非假期减少了425辆。
第三步:解释截距。
截距权重:对所有数值特征为0和分类特征为参照类别的实例,模型预测值即为截距的权重。上述解释通常没有意义(特征全部为0 的实例通常无实际含义)。但是,当特征标准化(均值为0,标准差为1)时,这种解释将会有实际含义,此时截距反应所有特征都处于均值时实例的预测结果。
本例中,截距的权重为2399,表示当处于春天、晴天、假期、工作日,温度、湿度、风速都为0,且为2011年1月1号时,预测的自行车数量为2399辆。以上解释无实际意义。
第四步:解释特征重要性。
使用t-统计量的绝对值解释特征重要性,(t=权重/SE,其中SE是标准差)。特征的重要性随着权重的增加而增加,随着方差的增加而减小(方差越大表明对正确值的把握越小)。
本例中,t统计量已经被计算出来了,上图中的 t=coef/std err。
进行数据处理(求绝对值、排序)后画图。
plot_df=df_coef.drop(index='Intercept') #删除截距行
plot_df=plot_df.sort_values(['t_abs']) #排序
fig = plt.figure(figsize = (9,5))
plt.barh(plot_df.index,plot_df['t_abs']) #画水平条形图
#设置x轴y轴
plt.xlabel('t-value绝对值',fontsize=18)
plt.ylabel('特征',fontsize=18)
plt.xticks(fontsize=12) #放大横纵坐标刻度线上的特征名字体
plt.yticks(fontsize=12)
plt.title('特征重要性',fontsize=20)
plt.show()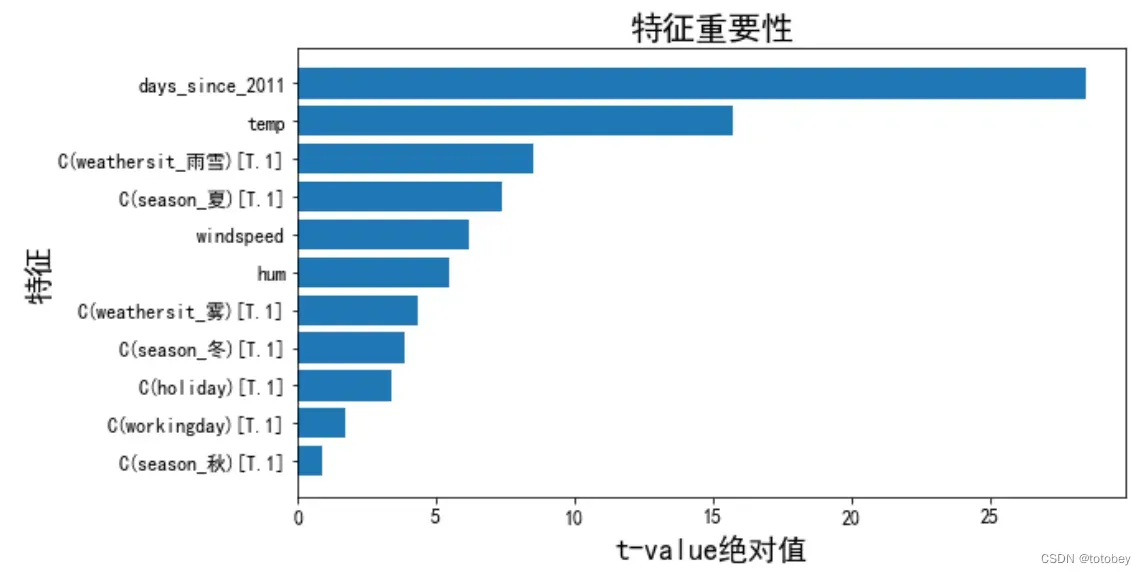
由上图可知,最重要的特征为距离2011年第一天的天数,排名第二的为温度,排名第三的为是否是雨雪天气。
问题来了,为什么不能直接使用权重(coef)代表特征重要性呢?
其中一个原因:如果改变特征的量纲,权重就会发生变化。
为进行验证,将风速的单位从km/h转换为km/分钟,即将风速的原始值除以60,得出以下结果:
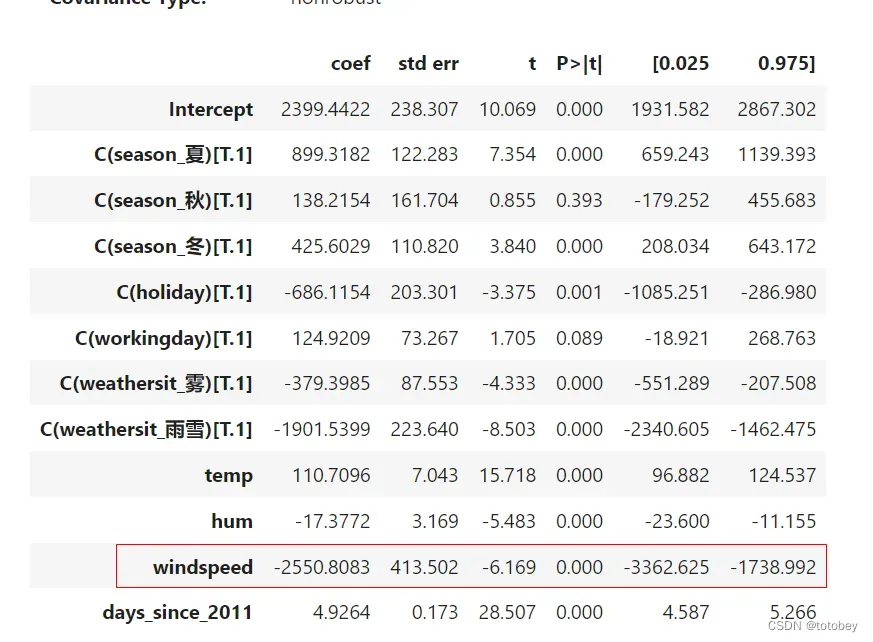
变化:其他不变,仅将风速除以60
结论:
其他特征的估计均不变。风速的部分估计发生了变化
权重(coef):扩大了60倍
权重标准差(std err):扩大了60倍
t统计量:不变(t=权重/标准差)
p值:不变
置信区间:扩大了60倍
所以在风速的本质并未发生改变的情况下,如果采用权重(coef)作为特征重要性的度量依据,就会发现其值会随着量纲的变化而变化,但t统计量却可以保持一致。
第五步:进一步可视化解释权重。
第二步已通过文本解释了权重(coef)的实际含义,这一步根据权重和置信区间画权重图。
plot_df=df_coef.drop(index='Intercept') #删除截距行
fig = plt.figure(figsize = (8,8))
#由于上下误差相同,因此直接用 xerr=plot_df['lw_err'],否则可以使用xerr=plot_df[['lw_err','up_err']].T.values来分别规定上下限
plt.errorbar(x=plot_df['coef'], y=plot_df.index,xerr=plot_df['lw_err'], color="black", capsize=3,
linestyle="None",
marker="s", markersize=7, mfc="black", mec="black")
plt.grid(True) #显示网格线
plt.xlabel('权重估计',fontsize=18)
plt.ylabel('特征',fontsize=18)
plt.xticks(fontsize=12) #放大横纵坐标刻度线上的特征名字体
plt.yticks(fontsize=12)
plt.title('权重估计图',fontsize=20)
plt.axvline(c="c",ls="--",lw=2) #原点竖线
plt.show()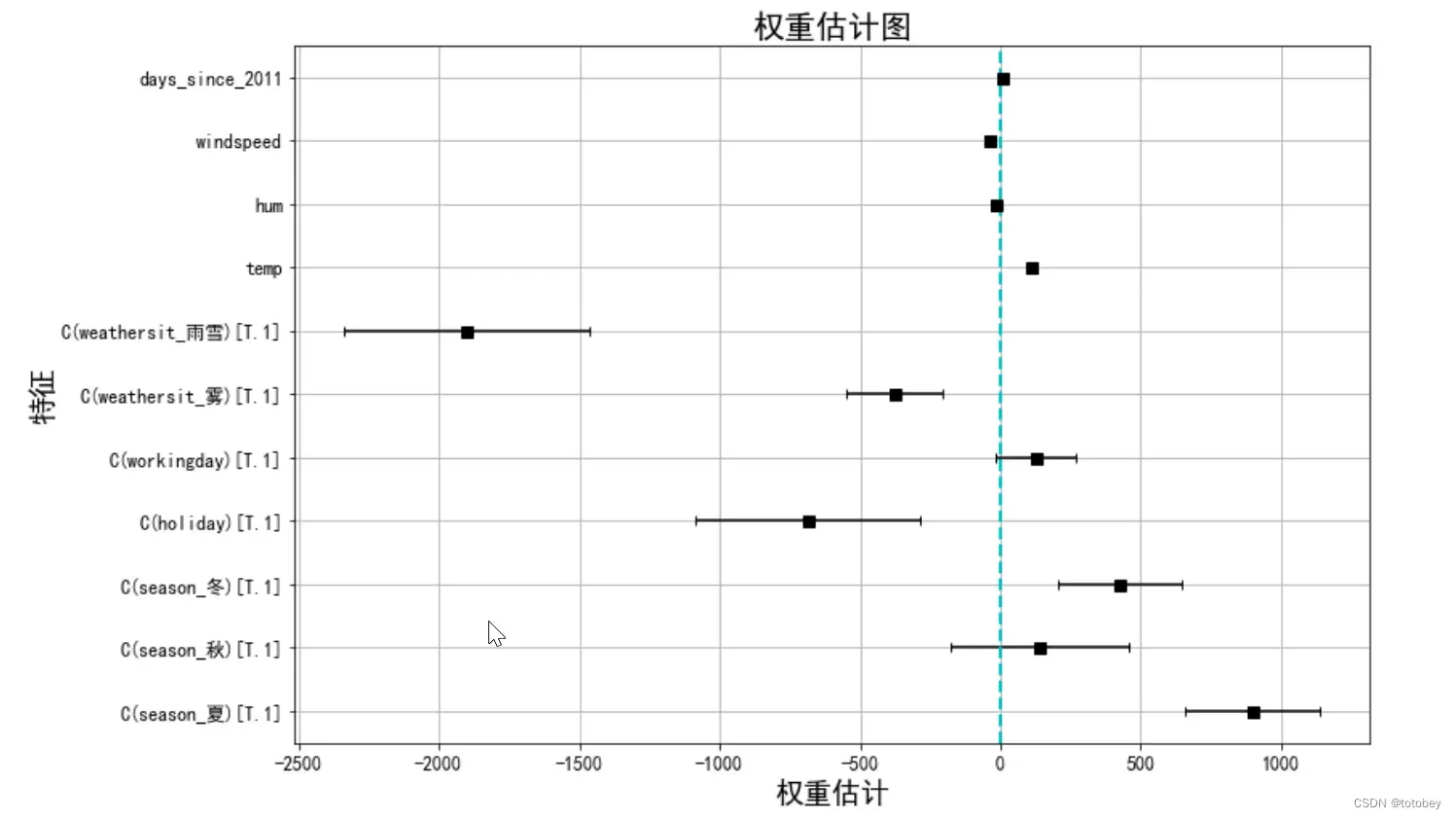
由上图可知:
1.雨雪天气对自行车租赁量有很大的负效应。
2.是否工作日的权重接近于0,并且95%的置信区间包含0,这表明该效应在统计上不显著。
3.温度的置信区间很短,估计值接近于0,但特征效应在统计上是显著的。
权重图的问题:
各个特征的量纲不一样,比如天气情况反映了晴天和雨雪天的差异,但是温度只反映了1℃的变化情况。
因此可以通过在建模前对特征进行标准化(均值为0,标准差为1),使估计的权重更具有可比性。
第六步:可视化效应图。
效应图(effect plot)帮助了解权重和特征的组合对数据预测的贡献程度。特征效应为每个特征的权重乘以实例的特征值。如改变特征的量纲,则权重会发生变化,但特征效应不会改变。
通过画箱线图(注意,分类特征总结为一个箱线图),可以观察下面几个方面:1)特征效应的正负性;2)特征效应的绝对值大小;3)特征效应的方差(如果方差小,则意味着这个特征几乎在所有实例中都有类似的贡献)。
#求特征效应——每个特征的权重乘以实例的特征值
w=df_coef['coef'].values
w_order=[] #将特征权重与实例中的顺序一一对应
my_dict={0:4,1:5,2:8,3:9,4:10,5:11,6:3,7:1,8:2,9:6,10:7} #权重表与数据集中特征的对应顺序
for i in range(11):
w_order.insert(i,w[my_dict[i]])
#计算特征效应
effect=X_train*w_order
#分类特征合并
effect['season']=np.sum(effect[['season_冬','season_夏','season_秋']],axis=1)
effect['weathersit']=np.sum(effect[['weathersit_雾','weathersit_雨雪']],axis=1)
effect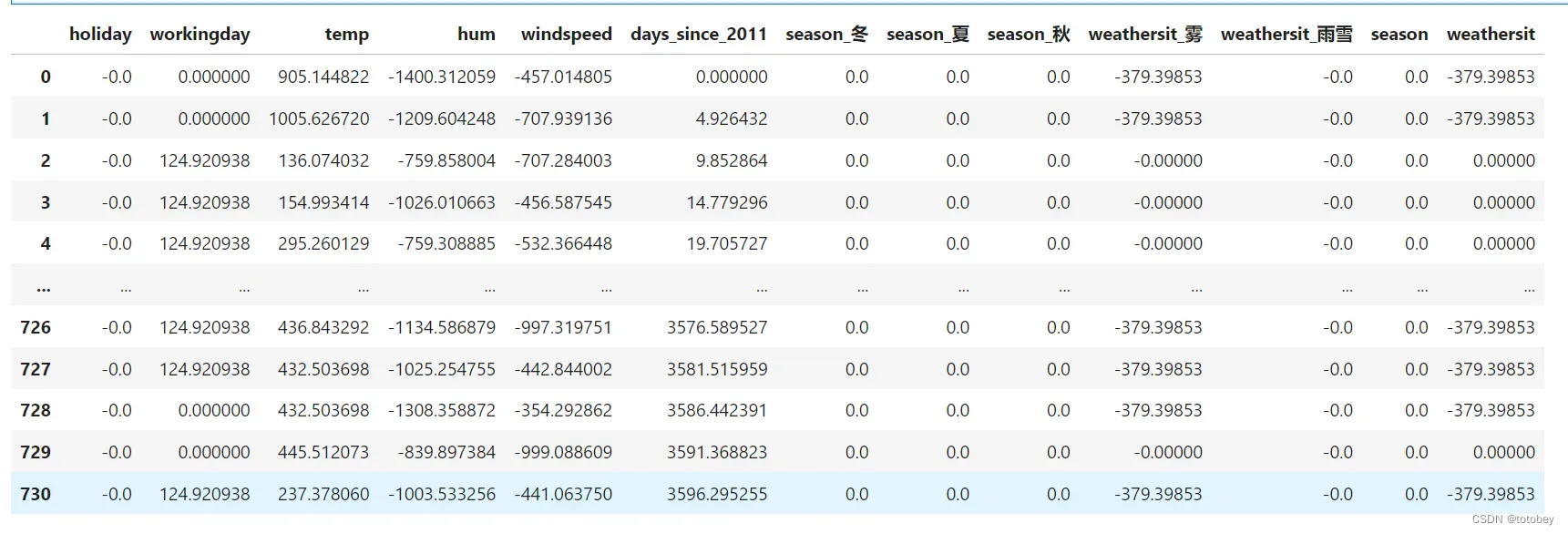
plt.subplots(figsize=(9, 9))
cols=['holiday', 'workingday', 'temp', 'hum', 'windspeed', 'days_since_2011',
'season', 'weathersit']
sns.boxplot(data=effect[cols],orient="h",width=0.5,whis=0.5, palette="Set2")
plt.grid(True) #显示网格线
plt.xlabel('特征效应',fontsize=18)
plt.ylabel('特征',fontsize=18)
plt.xticks(fontsize=12) #放大横纵坐标刻度线上的特征名字体
plt.yticks(fontsize=12)
plt.title('特征效应图',fontsize=20)
plt.axvline(c="c",ls="--",lw=2) #原点竖线
plt.show() 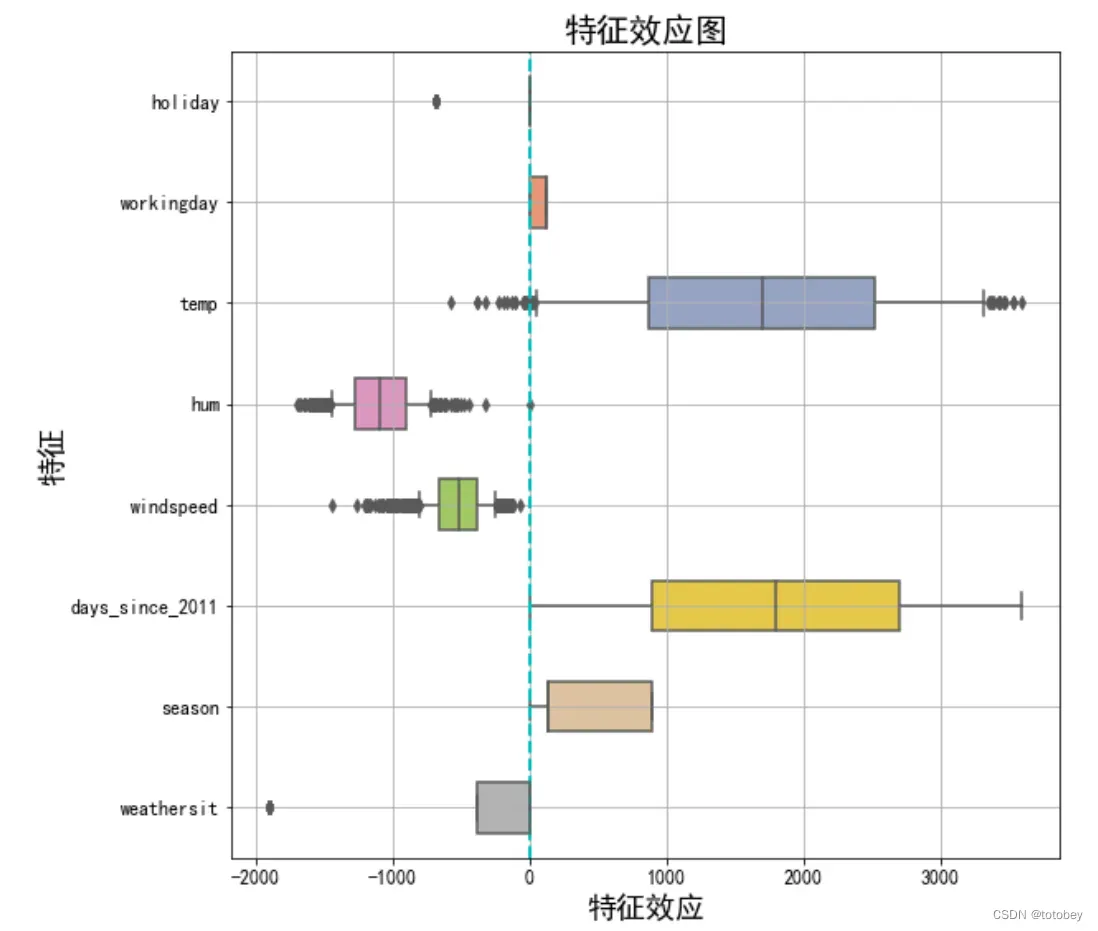
由上图可知:
1.对预测自行车租赁数量正向贡献最大的来自温度和天数。
2.天气的情况参照类别为晴天,图中说明除了晴天外的天气(雾、雨雪)都会对自行车租赁量产生负向影响。
第七步:通过效应图解释单个实例。
通过计算单个实例的特征效应,可以得到这个实例的各个特征对预测有多大的贡献。
步骤1:得到这个实例的预测值、所有实例的平均预测值、这个实例的实际值。将这个实例的预测值与所有实例的平均预测值进行对比,如果差距很大,则进一步解释原因。
步骤2:计算这个实例的特征效应,然后加入第六步的特征效应图中。即将这个实例的特征效应与所有实例的特征效应分布进行比较,得出结论。
single_idx=5 #第6个实例
print(bike_ohe.loc[single_idx])
target_predict=target_df.loc[single_idx,'predict']
target_predict_mean=np.mean(target_df['predict'])
target_true=target_df.loc[single_idx,'true']
print('该实例预测值',target_predict)
print('所有实例平均预测值',target_predict_mean)
print('该实例实际值',target_true)
plt.subplots(figsize=(9, 9))
cols=['holiday', 'workingday', 'temp', 'hum', 'windspeed', 'days_since_2011',
'season', 'weathersit']
sns.boxplot(data=effect[cols],orient="h",width=0.5,whis=0.5, palette="Set2")
plt.grid(True) #显示网格线
plt.xlabel('特征效应',fontsize=18)
plt.ylabel('特征',fontsize=18)
plt.xticks(fontsize=12) #放大横纵坐标刻度线上的特征名字体
plt.yticks(fontsize=12)
plt.title('单个实例的特征效应图',fontsize=20)
plt.axvline(c="c",ls="--",lw=2) #原点竖线
#画单个实例中每个特征的效应
for col in cols:
col_index=cols.index(col) #获取某个特征在特征名列表的索引位置
plt.plot(effect.loc[single_idx,col], col_index,'rx', ms=10) #rx 红色叉号,ms控制大小
plt.show() 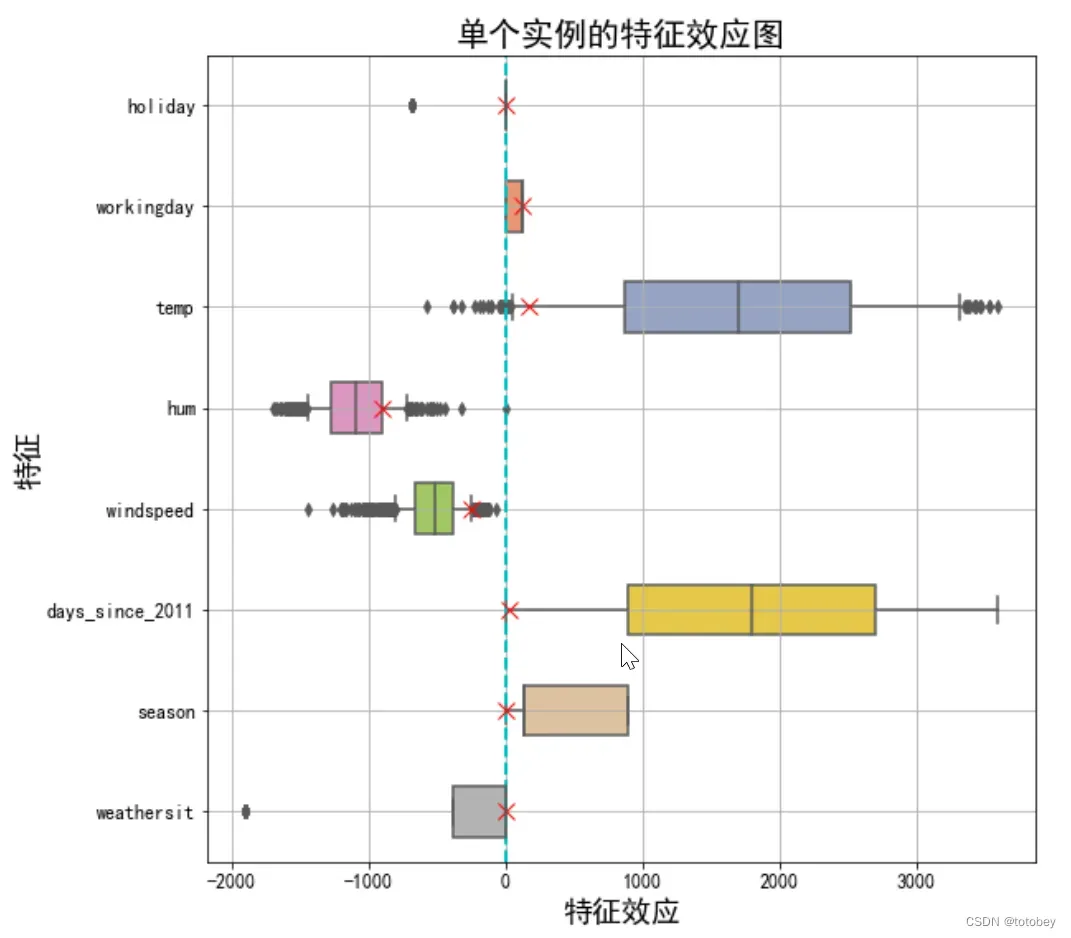
以数据集中第6个实例为例:
相较于所有实例的平均预测值4504辆,该实例的预测值很小,只有1571辆自行车被租赁。效应图揭示了原因:
1.该实例温度的特征效应较小,这一天温度仅为1.6℃,与其他大多数日期的温度相比较低(温度权重为正)。
2.该实例天数的特征效应也较小,该实例自第一天起仅过了5天(天数权重为正)。
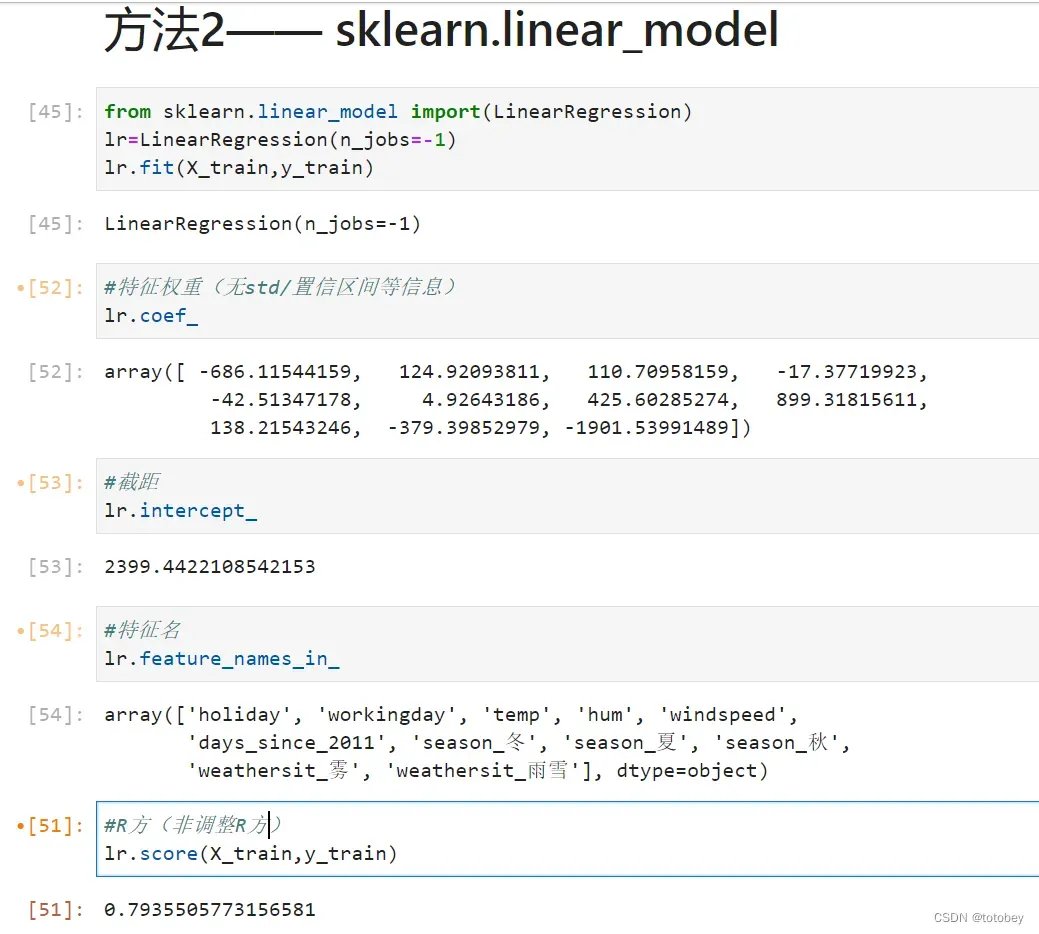
也可使用sklearn库进行建模,但是该库提供的信息十分有限,如下图:
完毕。
下一篇文章将在本文基础上做出以下变化:
本案例模型简述
模型:最基础的多元线性归回
特征选择:无
特征交互:无
本案例数据集简述
目标变量:自行车租赁量,连续型,因此为回归问题
分类特征处理方式: 进行效应编码,其中未出现的取值(例如春、晴)作为参照类别
连续特征处理方式:使用原始值- 均值
基础版线性模型的参照实例为构造的一个数据点,其中所数值型特征为0,分类型特征为参照类别,这通常是一个毫无意义的实例,不可能存在于现实中。
如果将所有数值特征以均值为中心(特征原始值减去该特征平均值),并且所有分类特征都采用效应编码,那么参照实例就是所有特征取平均特征值的数据点。这个数据点可能也并不存在,但可能会更有意义。
文章出处登录后可见!