解剖麻雀,是分析了解复杂问题的好办法。本文通过搭建只有两个神经元的网络,从根本上剖析 Pytorch 工作原理。
先附上全部源代码,然后听我慢慢唠!
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 2)
self.fc2 = nn.Linear(2, 1)
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = self.fc2(x)
return x
net = Net()
x = torch.linspace(0, 1, 10).reshape(10, 1)
y = x*x - 0.5*x + 1.5625
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr = 0.001)
for n in range(0, 100000):
optimizer.zero_grad()
loss = sum(abs(net(x) - y))
loss.backward()
optimizer.step()
if n % 1000 == 0:
print(n, loss)
print('Finished Training!')
import matplotlib.pyplot as plt
plt.plot(x, y, "k*")
z=[]
x = torch.linspace(0,1,100).reshape(100,1)
for xx in x:
zz = net(xx)
z.append(zz)
plt.plot(x, z, "b-")
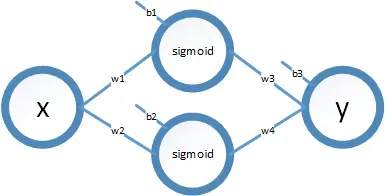
1. 两个神经元的神经网络
我计划搭建一个极简的神经网络模型。这个模型用来拟合 区间的一条抛物线,如果用
sigmoid 作为激活函数,两个神经元就够了。
.至于为什么只需要两个神经元,我会另写文章来加以说明。我遇到不少程序员,对于现有网络框架的调参、训练很熟练,但是一旦要他们自己创建新网络,往往不知道从何入手。原因在于对神经网络工作原理不理解。我建议,学习深度学习理论,应该自己经常搭建小型网络模型,逐步养成遇到问题能因地制宜有针对性地搭建网络模型。不要动不动就动用什么 yolo、ssd、deepsort 等现成的框架来应付差事。
.
.深度学习领域,程序员比拼的是建模能力,而不是调参能力。
网络模型用数学公式来表示如下:
共计 7 个参数。模型示意图如下:
2. Pytorch 模型
前面的神经网络,如何用 Pytorch 来表示呢?Pytorch 用 OOP 的编程模式来实现这个模型,具体地讲,就是以 torch.nn.Model 为基类,派生一个网络模型实例类。本文代码如下:
import torch
import torch.nn as nn
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 2)
self.fc2 = nn.Linear(2, 1)
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = self.fc2(x)
return x
这个模型实现了公式(1)中的函数,开始的时候,其参数 是随机的。
接下来我们看看这个模型如何工作。在 Python 环境下执行完上述命令后,继续输入下面的命令(我用的是 IPython 环境):
net = Net()
x = torch.tensor([0.5])
y = net(x)
print(y)
----------------------------------------------
tensor([-0.4313], grad_fn=<AddBackward0>)
2.1 Python 强大的 OOP 机制简化 Pytorch 应用接口
从大的方面看,我对下述代码的运行机制很感兴趣:
class Net ...
net = Net()
y = net(x)
Net 是一个类,net 是类 Net 的实例,但 net 在后面却被当成函数使用,貌似只有 C++ 才有的机制呀!这一番神操作是如何做到的呢?下面我写一段代码展示一下:
class Mul:
rate = 100
def __call__(self, x):
return x * self.rate
mul = Mul()
mul(123)
----------------------------------------------
12300
net(x) 看上去像普通函数调用,实际上调用的是类 Net 的实例 net 的 __call__ 方法。这种表达方式,说明 Python 语言表现能力非常强大,难怪 Python 被用来开发各种系统级的软件包。
为什么要费劲用一个 class 来伪装成 function 呢?原因有两点:
net在执行__call__的时候,需要利用内部属性变量记录计算过程中的某些状态。net在执行__call__的时候,需要利用内部属性变量定义的某些计算规则。前面的例子中,net(x)执行过程中要参考神经网络模型中的计算过程定义。
这个技巧掩盖了 net 函数计算过程背后的复杂性,使得 Pytorch 在应用过程中更加简练。
2.2 定义参数
我们知道在 (1) 式中,算法模型定义中用到了 7 个参数。这七个参数是在类 Net 的 init 方法中定义的,代码如下:
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(1, 2)
self.fc2 = nn.Linear(2, 1)
这段代码在类 Net 构建的时候执行。它说明 Net 模型包含了两个线性变换计算,第一个 self.fc1 是 1 个输入和 2 个输出的线性变换, 第二个 self.fc2 是 2 个输入和 1 个输出的线性变换。具体一点,定义了如下变换:
self.fc1:
self.fc2
注意,这个定义中不包括 sigmoid 函数的运算,原因是该计算不包含任何参数,因此无需在 __init__ 方法中展现。实际上:
或简化为:
总而言之,需要含待确定参数的运算过程,在 __init__ 中定义。那些没有参数,或者不需要通过训练参数的运算,无需在此定义。
2.3 定义计算过程
在 forward 方法中,要定义完整的计算过程,以便根据输入 x 计算模型的输出 y。代码如下:
def forward(self, x):
x = torch.sigmoid(self.fc1(x))
x = self.fc2(x)
return x
我们又看到神奇的一幕,self.fc1 和 self.fc2 在 __init__ 代码中明明是一个变量,怎么摇身一变成函数了?这个戏法和代码 net = Net(),然而 y = net(x) 是同一个原理。函数 nn.Linear(1, 2) 返回了一个类的实例,该实例重载了 __call__ 方法。
最重要的是,x = torch.sigmoid(self.fc1(x)) 这种代码,看上去和我们编写的普通函数无异,其实它并没有实际执行计算,只是把定义的计算公式以某种数据结构保存在 Net 内部了。真正的计算是在函数 __call__ 中进行的,也就是在执行 y = net(x) 的时候进行的。__call__ 函数依据定义的公式和输入数据计算输出结果。
2.4 Pytorch 中计算过程的定义
计算过程不局限于 forward 方法内。实际上,我们需要知道从输入变量 x 到最终 loss 函数计算的完整过程。因此,类似 forward 方法中的计算过程定义,我们会不断遇到。计算过程定义方法,forward 给出了很好的示范。
下面我写一个例子,这个例子中,定义了加法运算。这个加法运算并没有计算两个数字的和,而是把加法计算公式保存成一个字符串。代码如下:
class MyData:
data=""
def __init__(self, x):
self.data = x
def __add__(self, other):
return self.data + ' + ' + other.data
a = MyData('a')
b = MyData('b')
c = a + b
print(c)
----------------------------------------------
a + b
Pytorch 就是利用这样的机制,把我们习以为常的计算公式转换成了内部定义格式,供其他函数解释执行。
那么,前面的代码中,变量 x、y 等都是些什么类型呢?在 Pytorch 中,神经网络的输入和输出都是张量。也就是 torch.Tensor 类型。这种类型重载的数学运算符,因此我们可以用常规的计算公式把公式定义保存到网络模型里。
也正因为 Python 语言的这个特点,使得它能够担当“元语言”的角色,在抽象层面定义复杂计算过程,以便开发出高级的数学计算工具。Pytorch、Tensorflow、Keras 都充分利用了运算符重载机制,描述算法模型的计算过程。
3. Pytorch 的梯度(微分)计算机制
神经网络的训练离不开微分计算。Pytorch 既然能够提供计算过程的定义机制,也就是说 Pytorch 是知道计算过程的公式结构的。既然这样,求解复杂公式的微分也是可能的。我们先看个例子:
3.1 微分计算机制
x = torch.tensor([1.0], requires_grad = True)
print("x = ", x)
y = x*x
print("y = ", y)
y.backward()
print("x.grad = ", x.grad)
----------------------------------------------
x = tensor([1.], requires_grad=True)
y = tensor([1.], grad_fn=<MulBackward0>)
x.grad = tensor([2.])
下面解释一下代码:
- x 是一个张量,我们定义的时候要求保存梯度信息:
x = tensor([1.], requires_grad=True) - y 等于 x 的平方。当然,
y = x * x应该是借助运算符重载机制,把这个计算公式转化成内部的数据结构保存起来了。因此我们可以断定,变量 y 不仅保存了 1*1 的值,而且也保存的计算公式本身。从后面的打印结果可以证实这一结论:tensor([1.], grad_fn=<MulBackward0>) y.backward()会对其携带的公式计算微分。这个过程很神奇,无论计算过程有多少步骤,backward 都能够回溯到 y 所依赖的变量 x。我们看一下 x 的微分:x.grad = tensor([2.])。对照一下下面的数学公式,结果是正确的.
当 x = 1 时,梯度值 。
3.2 Pytorch 中梯度(微分)累加机制
上面的例子修改一下:
x = torch.tensor([1.0], requires_grad = True)
print("x = ", x)
y = x*x
print("y = ", y)
y.backward()
print("x.grad = ", x.grad)
y = x*x
print("y = ", y)
y.backward()
print("x.grad = ", x.grad)
x.grad = torch.tensor([0.])
print("x.grad = ", x.grad)
----------------------------------------------
x = tensor([1.], requires_grad=True)
y = tensor([1.], grad_fn=<MulBackward0>)
x.grad = tensor([2.])
y = tensor([1.], grad_fn=<MulBackward0>)
x.grad = tensor([4.])
x.grad = tensor([0.])
注意,x.grad 的值是累加的。这一特点很重要,因为当用大量训练样本训练时,我们需要累计每一个样本的梯度。
4. Pytorch 官网提供的梯度(微分)计算的例子
由于微分计算非常重要,这里再展示一个更复杂的微分计算的例子,来自 https://www.pytorch123.com。
import torch
x = torch.ones(2, 2, requires_grad=True)
y = x + 2
z = y * y * 3
out = z.mean()
out.backward()
print(x.grad)
----------------------------------------------
tensor([[4.5000, 4.5000],
[4.5000, 4.5000]])
这个展示了多维输入和多维输出网络的微分计算,微分公式不再是一个简单的代数式,而是一个矩阵,该矩阵就是多元函数微积分里著名的雅可比矩阵。具体细节不多讲了,反正记住这个矩阵是训练模型的时候用于反向传播算法的。参见下面的解释。

5. 生成训练数据
我们让神经网络模型在 区间内逼近下面的函数:
基于该函数解析式,用下面的代码生成10组训练数据:
x = torch.linspace(0, 1, 10).reshape(10, 1)
y = x*x - 0.5*x + 1.5625
其中,x是输入数据,y是训练标签。
6. 构建损失函数
损失函数结果是网络 net 针对输入 xi 预测的结果 net(xi) 与标签 yi 误差的绝对值的和。数学公式如下,其中 是训练样本数量:
由于 Pytorch 中的函数和运算都是针对张量设计的,因此函数定义也很简单:
loss = sum(abs(net(x) - y))
7. 选择梯度下降的策略
为了更好更快地训练模型,有多种梯度下降策略可以选择。由于不同的策略导致不同的训练代码,为简化这部分工作,Pytorch 提供了优化框架。训练代码如下:
import torch.optim as optim
optimizer = optim.SGD(net.parameters(), lr = 0.001)
for n in range(0, 100000):
optimizer.zero_grad()
loss = sum(abs(net(x) - y))
loss.backward()
optimizer.step()
if n % 1000 == 0:
print(n, loss)
print('Finished Training!')
首先我们选择 optim.SGD (随机梯度下降)作为优化策略,学习率 lr = 0.001。学习率需要具体实验才能确定。如果训练过程中,loss 的值不能稳步下降,而是不断出现徘徊,说明 lr 的值太大了。如果 loss 下降速度很慢,说明 lr 的值太小了。
本例中,我计划迭代 100000 次。
在循环体内,首先执行梯度清零。我们知道,net 的梯度值是不断累加的。在每个迭代开始时,需要清零梯度,以便计算当前模型针对训练样本的总体梯度值。
8. 显示结果
用 matplotlib 的工具先试一下训练效果:
import matplotlib.pyplot as plt
plt.plot(x, y, "k*")
z=[]
x = torch.linspace(0,1,100).reshape(100,1)
for xx in x:
zz = net(xx)
z.append(zz)
plt.plot(x, z, "b-")
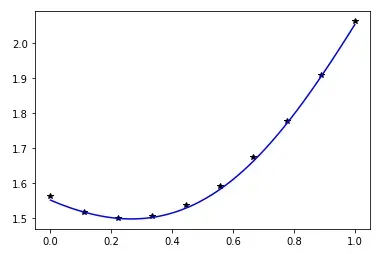
有了本文的基础,相信进一步学习 Pytorch 应该非常轻松了。
文章出处登录后可见!