随机采样是最为简单也是应用最为广泛的一类采样技术,主要分为以下两个类别:随机降采样(Random Under-Sampling,RUS)及随机过采样(Random Over-Sampling, ROS)。其中,前者通过随机移除一定数量的多数类样本来缓解类分布不均衡的影响,而后者则通过简单复制少数类样本的方式来达成不同类在训练样本规模上的平衡。下面将分别对上述两类算法的流程及特点进行简要介绍。
随机降采样法
随机降采样(Random Under-Sampling, RUS)算法的基本思想是随机地移除一定数量或比例的多数类样本,以达到训练样本集的平衡。RUS算法的基本流程如下。
随机降采样(Random Under-Sampling, RUS)算法
输入:训练集;多数类样本数
,少数类样本数
,其中
;不平衡比率
;采样率
输出:降采样后的训练集
(1) 从训练集中取出全部多数类与少数类样本,组成多数类训练样本集
及少数类训练样本集
(2) for
(3)在
之间随机选择一个数字,于
(4)
(5) return 降采样后的训练集
从上述算法流程不难看出,经过RUS算法处理过的训练集在样本规模上大幅减小了,且由于样本移除的随机性,这一算法的时间复杂度是相对较低的。然而,也正是由于对多数类样本不加以区别地进行移除,可能会造成较多的分类信息损失,从而导致后期建模的分类器质量不高。一般而言,当IR值较低,即类别不平衡问题不是非常严重时,RUS算法的效果通常较好,而当IR值较高时,即对于极度不平衡的分类问题,RUS算法的性能则往往不可控,且有较大概率获得较差的分类结果。图3-1给出了一个简单的示例,训练集中的多数类与少数类样本分别为100∶50与100∶5,即IR值分别为2及20,且保持SR=IR-1时,分别两次调用RUS算法,所得到的训练样本分布情况。
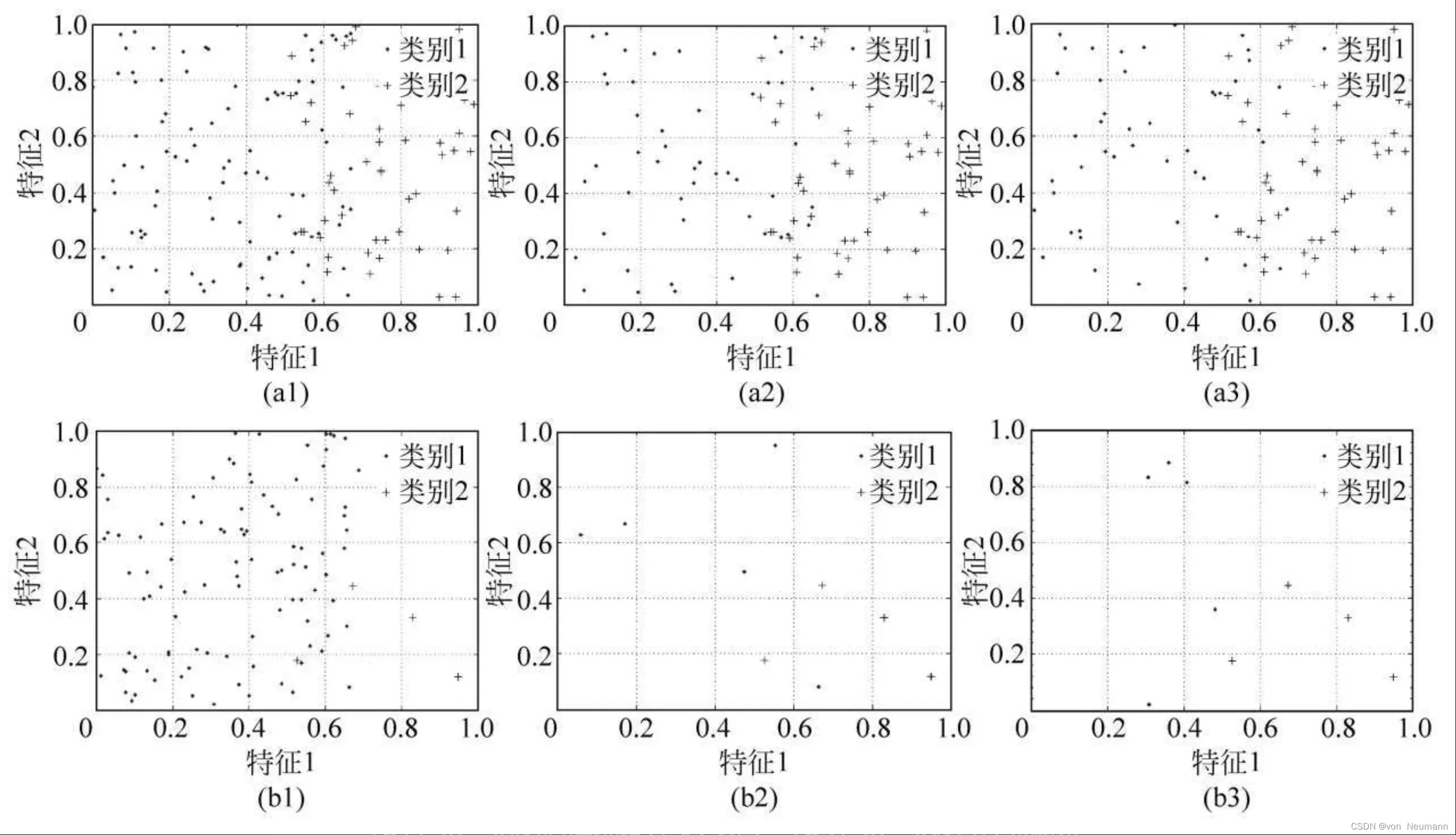
实际上,在早期的一些应用中,人们已经开始注意到了类别不平衡分布对分类性能的负面影响,并开发了一种样本集的人工划分方法。该方法将整个样本集划分为一个平衡的训练集与一个不平衡的测试集,由于分类器是在训练集上学习得到,故能保证其分类结果的公正性。严格来讲,人工划分法也可被视为RUS法的一种扩展,即训练集是对原始样本集做随机降采样而得到,只不过,在该方法中,随机降采样并不仅仅针对多数类,同时也针对少数类。人工划分法尽管有效,但并不合理,因为它假设测试集在训练前便是存在的,而这与实际应用情况并不相符。

随机过采样法
随机过采样法,即ROS算法的基本思想是随机地抽取少数类样本并进行多次复制,从而达到增加少数类样本,平衡训练集类别分布的目的,其基本流程如下:
随机过采样(Random Over-Sampling, ROS)算法
输入:训练集
输出:降采样后的训练集
(1) 从训练集
(2) for
(3)之间随机选择一个数字,于
中找到对应的样本
(4)
(5) return 降采样后的训练集
显然,由于没有移除任一样本,故与RUS算法相比,ROS算法能有效克服其重要分类信息缺失的问题。但是,ROS算法也有其固有的缺点:
- 由于增加了大量的样本,扩充了训练样本集,故将不可避免地在后期增加分类器的训练时间开销
- 由于仅是对少数类样本进行复制,必然会造成各少数类样本在样本空间的“叠加”效应,这就导致分类器难以学习到一个分布,而是趋向于逼近一些离散的样本点,从而出现过适应的现象。
文章出处登录后可见!