



ROS1从kinetic之后,生态非常成熟,但是由于ROS1内核设计比较早,不能高效稳定地适应分布并行和实时等应用,存在缺陷,从melodic和noetic之后,一直是ROS1和ROS2并存地状态。
2022年5月,ROS 2 Humble Hawksbill 已经具备了丰富和成熟生态,也结束了并存状态,现在官方主力只更新和完善ROS2了。ROS1只处于维护状态。
原文参考:
discourse.ros.org/t/ros-2-humble-hawksbill-released/25729机器翻译如下:
仿真:
三大主流软件均支持,Gazebo/V-Rep/Webots。
库和工具
Gazebo 不仅仅是一个模拟器:它是 16 个 C++ 库 3 的集合,可以在机器人应用程序上独立于模拟器使用。 可以在 ROS 包或纯 C++ 项目中使用它们。 如果需要渲染或物理引擎抽象; 用于创建现代机器人界面的 GUI 框架 3; 数学 1、图形或 AV 实用程序,这些库之一可能会派上用场!
可以在 package.xml 中使用
- ignition-fortress
- ignition-cmake2
- ignition-common4
- ignition-fuel-tools7
- ignition-gazebo6
- ignition-gui6
- ignition-launch5
- ignition-math6
- ignition-math6-eigen3
- ignition-msgs8
- ignition-physics5
- ignition-plugin
- ignition-rendering6
- ignition-sensors6
- ignition-tools
- ignition-transport11
- ignition-utils1
- sdformat12

Foxglove

FogROS2
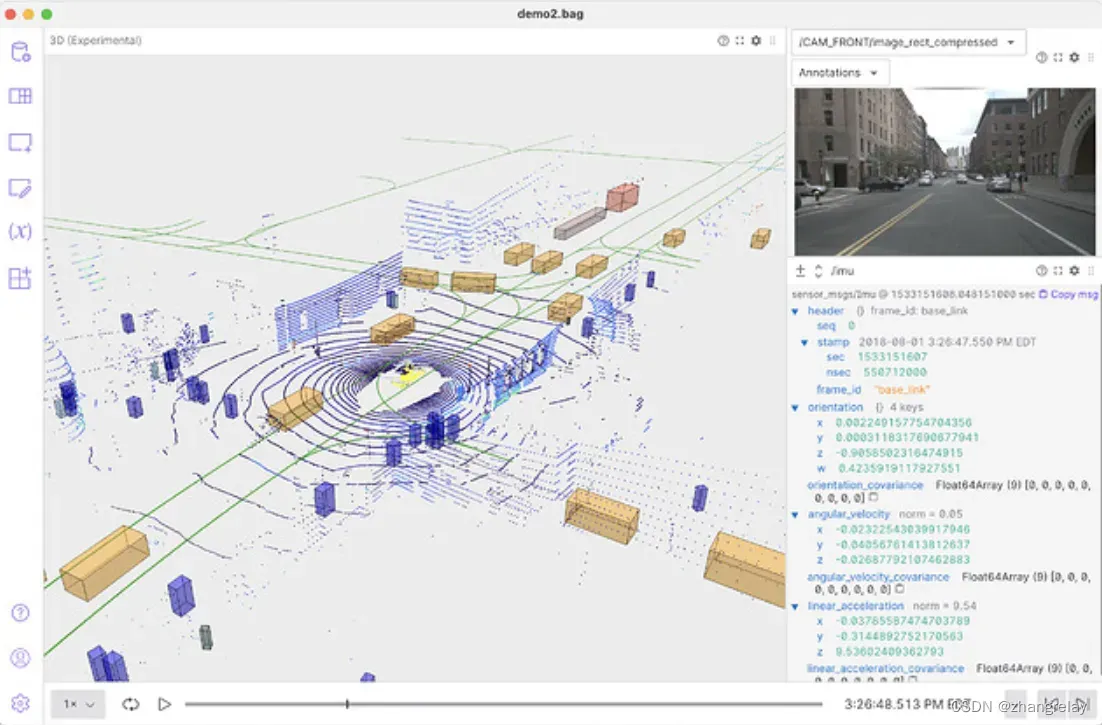
FogROS 2,加州大学伯克利分校的开源云机器人试点平台。使用诸如 Amazon Web Services (AWS) 等商业集群的云计算现在已经足够快,可以实现安全的计算密集型机器人功能,例如通过视频构建 SLAM 地图、抓取规划和高维运动规划,这些功能可以在云中使用高- 近乎实时的高性能硬件和 GPU。 FogROS 2 提供 ROS 2 功能来简化机器人代码的部署。开发人员不需要更改他们的代码——只需要指定希望代码运行的计算机的 AWS 配置。 FogROS 2 协调启动硬件实例、安装软件和依赖项、保护机器人与云通信以及启动云进程的细节。
在示例应用程序中,使用 FogROS 2 将计算密集型 ROS 2 节点部署到云中,用于 SLAM、Grasp Planning 和 Motion Planning。对于 Visual SLAM,在多核云计算机上运行 ORB-SLAM 2 节点,得到了 2 倍的加速。对于 Grasp Planning,在云中的 GPU 实例上运行 Dex-Net 节点并获得了 12 倍的加速。对于运动规划,在 96 核云计算机上运行运动规划模板,并获得了 28 倍的加速。

硬件加速
为什么 Yocto/PetaLinux 非常适合机器人硬件加速?
硬件加速涉及创建自定义计算架构以提高计算性能。 简而言之,通过设计专门的加速内核,可以为机器人构建定制大脑,以加快它们的响应时间。 当使用自适应计算和 FPGA 时,这变得特别可行,根据之前的基准,使用 ROS 在机器人技术中提供最佳结果。
创建此类定制计算架构涉及硬件和软件定制,因此:Yocto。 虽然很复杂,但 Yocto 与硬件加速相结合有助于提供高性能的生产级机器人系统。




Docker
ROS 最新标签现在指向 Humble ros_base 映像。
只需运行以下命令即可在 Humble 容器中下载并启动会话:
docker run -it ros:humble
ROS Humble 镜像可用于以下平台/架构:
Ubuntu:
amd64
arm64v8 (aarch64)
桌面映像(仅限 amd64)在“osrf/ros”docker hub 配置文件 1 上可用
:warning: Humble 不存在 ros1-bridge 映像,因为这是第一个不支持 ROS 1 的 ROS 2 发行版。
CPU+GPU
随着机器人应用程序包含 AI、CV 和其他计算密集型工作负载,在 ROS 中启用硬件加速已变得势在必行。通过硬件加速,这些应用程序可以以更高的吞吐量和更好的性能/功耗执行更多功能。实现这些好处通常特定于硬件实现,因此需要从 ROS 中抽象出来。
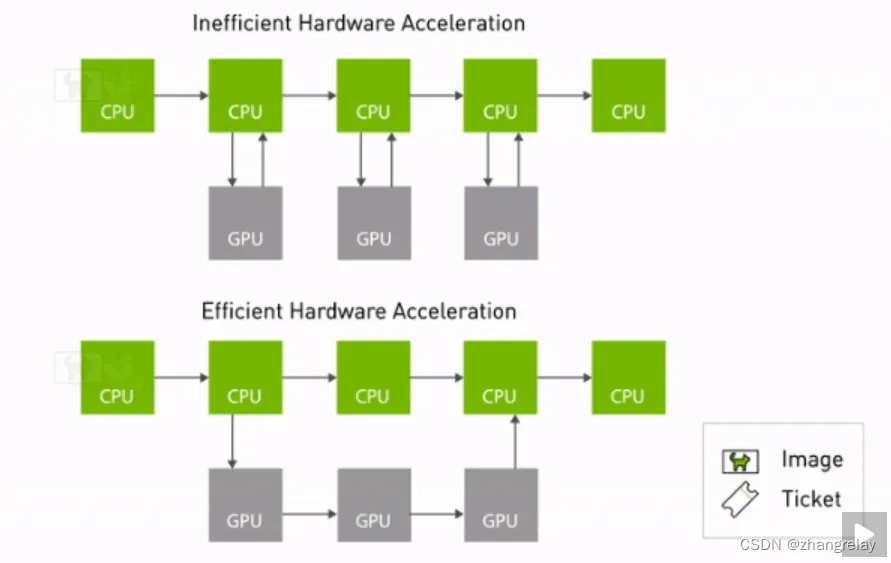

在 Foxy 中使用硬件加速的节点示例图(上图)与在 Humble 中使用类型自适应(下图)相比。类型自适应减少了节点管道中从 CPU 到 GPU 的副本,同时增加了 CPU 和 GPU 之间的并发性
类型适应
ROS 主题可以使用类型适应(REP-2007 9)适应更适合硬件加速的格式。使用适配类型的节点可以发布和/或接收适配类型。使用适配类型的节点需要提供从标准类型转换为适配类型的函数,反之亦然。这使节点图能够使用一种适应类型,该类型可以提高 CPU 和硬件加速的并发性,从计算任务中卸载 CPU,并消除 CPU 和硬件加速器之间的内存复制。
类型协商
通过使用自适应类型的 ROS 节点图,可以进一步受益于优化图中节点之间使用的类型。支持类型协商(REP-2009 5)的节点可以共享它们作为发布者和订阅者支持的类型列表,权重表明他们的偏好。 ROS 将审查参与类型协商的发布者和订阅者,并针对偏好进行优化,同时保持与不支持类型协商的节点的兼容性。首选项是反映性能或类型成本的一种方式,应该由节点的开发人员调整,但可以由应用程序开发人员覆盖。
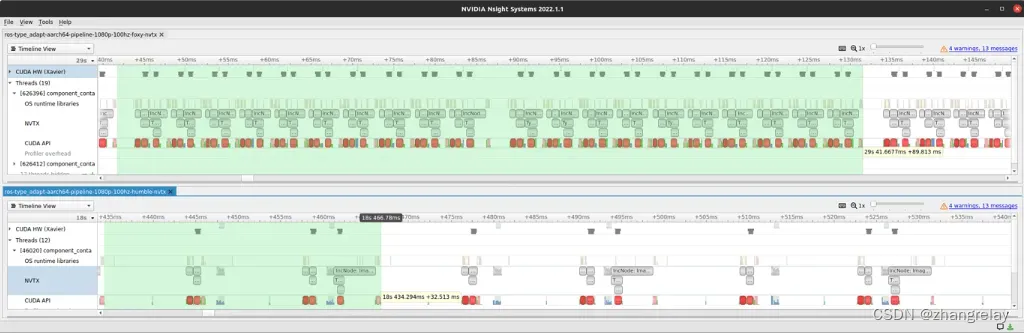

Jetson AGX Xavier 的简介,Foxy 为 89 毫秒,Humble 为 32 毫秒,对同一节点图进行类型调整
随着类型适应和类型协商性能的提高,ROS 中的进程内主题传递成为瓶颈。 Nsight Systems 5 用于分析消息传递以识别需要改进的领域。在 rcl.cpp 中进行了更改,以减少共享内存指针副本和检查以打印调试消息。
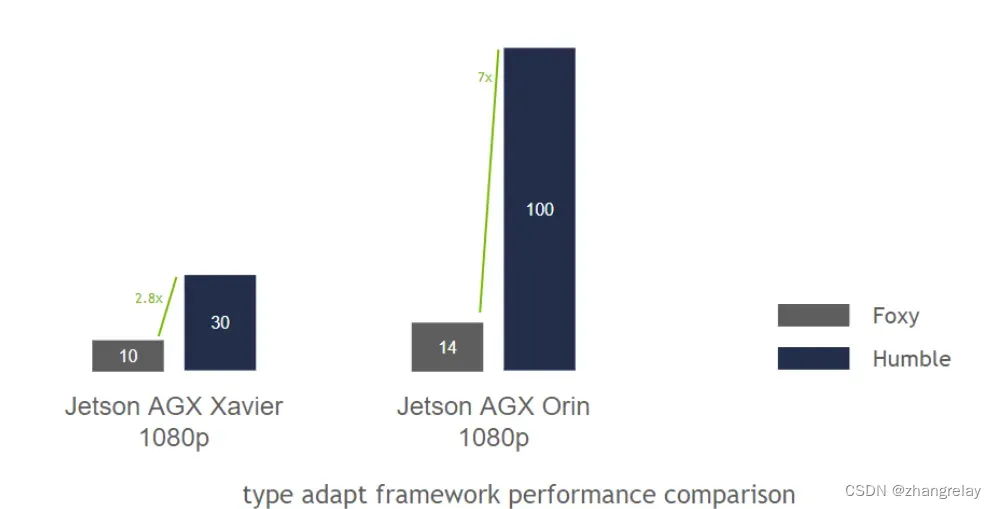
在像素处理方面,Jetson AGX Orin 在此测试中从 Foxy 中的 0.55 千兆像素/秒到 Humble 中的 4 千兆像素/秒。

使用类型适应和类型协商的节点硬件加速图提高了性能、并发性和性能/功率。还有其他实现硬件加速的替代方法,它们分叉 ROS、绕过 ROS 主题或引入与现有节点的不兼容性。类型适配和类型协商是 ROS with Humble 原生的,与现有节点兼容,并对包括 GPU、DSP、NN 加速器和其他硬件模块在内的所有类型的硬件加速器开放。
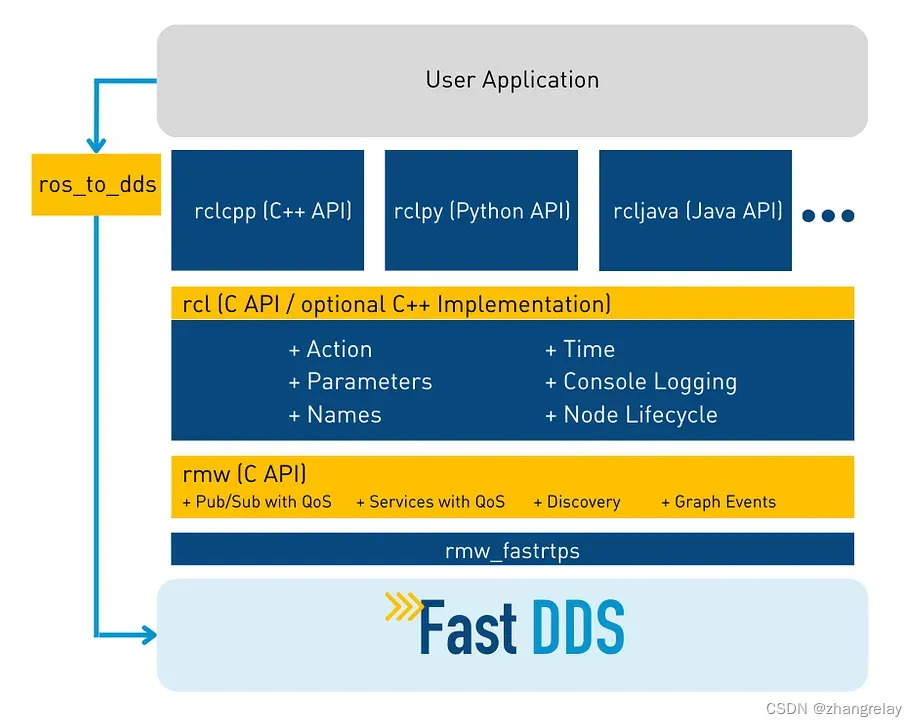
事实上,Fast DDS 被选为 ROS 2 Humble 的默认 DDS 中间件,允许 ROS 2 用户使用可靠且性能优化的实现来开发机器人应用程序。
以许多功能而闻名,例如
- 实时行为
- DDS 安全
- 发现服务器
- 共享内存传输
- 同步和异步发布模式
还有很多
eProsima 能够在 Humble 版本的 Fast DDS 中包含更多特性……
内容过滤主题功能 1 (CFT) 为主题提供过滤功能,使用户在订阅主题时能够在特定条件下对他们感兴趣的数据子集进行分段。
在运行时添加远程服务器和修改服务器定位器:现在可以以编程方式添加和修改参与者的远程服务器列表,当服务器或客户端正在运行时,正在运行的服务器或客户端应连接到这些远程服务器。
静态发现新格式:新的交换格式减少了传输静态所需的网络带宽。
快速 DDS CLI 的 XML 支持。
完整的事件支持:发布者和订阅者的不兼容 QoS 通知。

rclc – 用于微控制器的 ROS 2 C-API
rclc 包对 ROS 客户端支持库 (rcl) 进行了补充,为 C 编程语言提供了完整的 ROS 2 客户端库
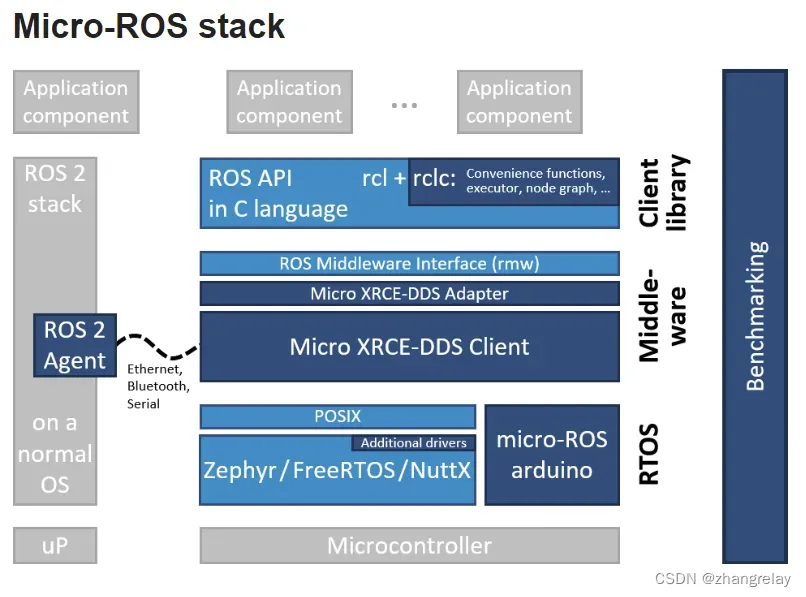

micro-ROS


- 新的 RCLC 特性
- 对各种板的新支持:RENESAS RA 系列、TI Tiva™ C 系列、
- 对众多平台的新支持:Platforms IO、St STMCube、Microsoft Azure RTOS、Espressif ESP-IDF
- 新嵌入式RTPS实验RMW 1
- 微型 XRCE-DDS v2.1.1
Moveit2


亮点
- 混合规划 7:使用(较慢)全局运动规划器和(较快)局部运动规划器,使机器人能够在线和在动态环境中解决不同的任务
- TOTG 1:现在默认的参数化方法
- Ruckig 1:改进的时间参数化和 jerk 平滑,允许非零初始/最终条件
- MoveIt Setup Assistant 3:使用 MoveIt 的入口点,现在适用于 ROS 2
- MoveIt Config Utilities 2:简化加载参数
- 许多用于手臂的新 ROS 2 驱动程序(Universal Robotics 3 及更多即将发布)
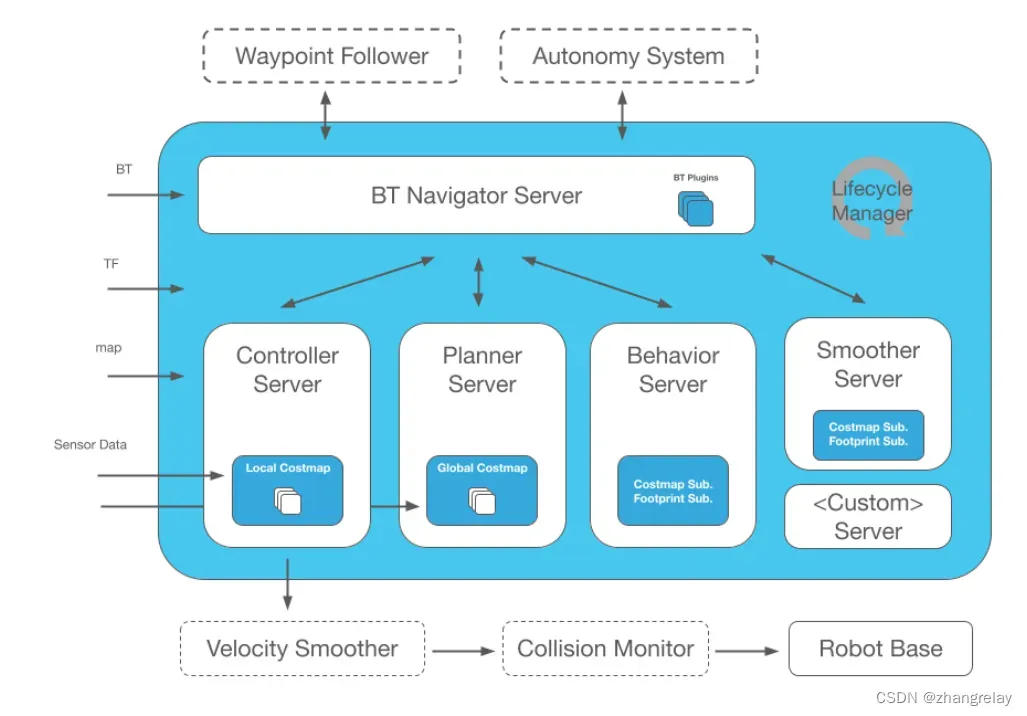
Nav2
亮点
- 在运行时、组织、启发式以及添加新的 State Lattice 规划器等方面对 Smac 规划器进行了大规模改进。
- 为 Nav2 应用程序开发人员添加 Python3 API,可以从 pythonic API 访问所有 Nav2 系统。
- 整个堆栈的运行时性能改进减少了节点数量,显式控制执行程序,并默认启用组合,因此所有 Nav2 都在一个进程中,将 CPU 开销减少 15% 并将内存减少 70%。 经过测试,可以在树莓派上轻松运行,并为自定义机器人代码留出足够的空间。
- 包含新算法:State Lattice、Rotation Shim、Simple Smoother、Constrained Smoother、(即将添加)Velocity Smoother
- 所有适当参数的动态重新配置
- 在 Nav2 核心架构中添加新的 Smoother Server,用于全局路径平滑
- 为 Lifecycle Manager 和 Nav2 启动添加了重生支持
- 几个新的文档页面、教程等。

文章出处登录后可见!