文章最前: 我是Octopus,这个名字来源于我的中文名–章鱼;我热爱编程、热爱算法、热爱开源。所有源码在我的个人github ;这博客是记录我学习的点点滴滴,如果您对 Python、Java、AI、算法有兴趣,可以关注我的动态,一起学习,共同进步。
相关文章:
目录:
1)DBSCAN算法介绍
DBSCAN是一种非常著名的基于密度的聚类算法。其英文全称是 Density-Based Spatial Clustering of Applications with Noise,意即:一种基于密度,对噪声鲁棒的空间聚类算法。直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
DBSCAN算法具有以下特点:
- 基于密度,对远离密度核心的噪声点鲁棒
- 无需知道聚类簇的数量
- 可以发现任意形状的聚类簇
DBSCAN的算法步骤分成两步。
1,寻找核心点形成临时聚类簇。
2,合并临时聚类簇得到聚类簇。
2)生成数据Python代码
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import numpy as np
import pandas as pd
from sklearn import datasets
X,_ = datasets.make_moons(500,noise = 0.1,random_state=1)
pdf = pd.DataFrame(X,columns = ['feature1','feature2'])
pdf.plot.scatter('feature1','feature2', s = 100,alpha = 0.6, title = 'dataset by make_moon'); 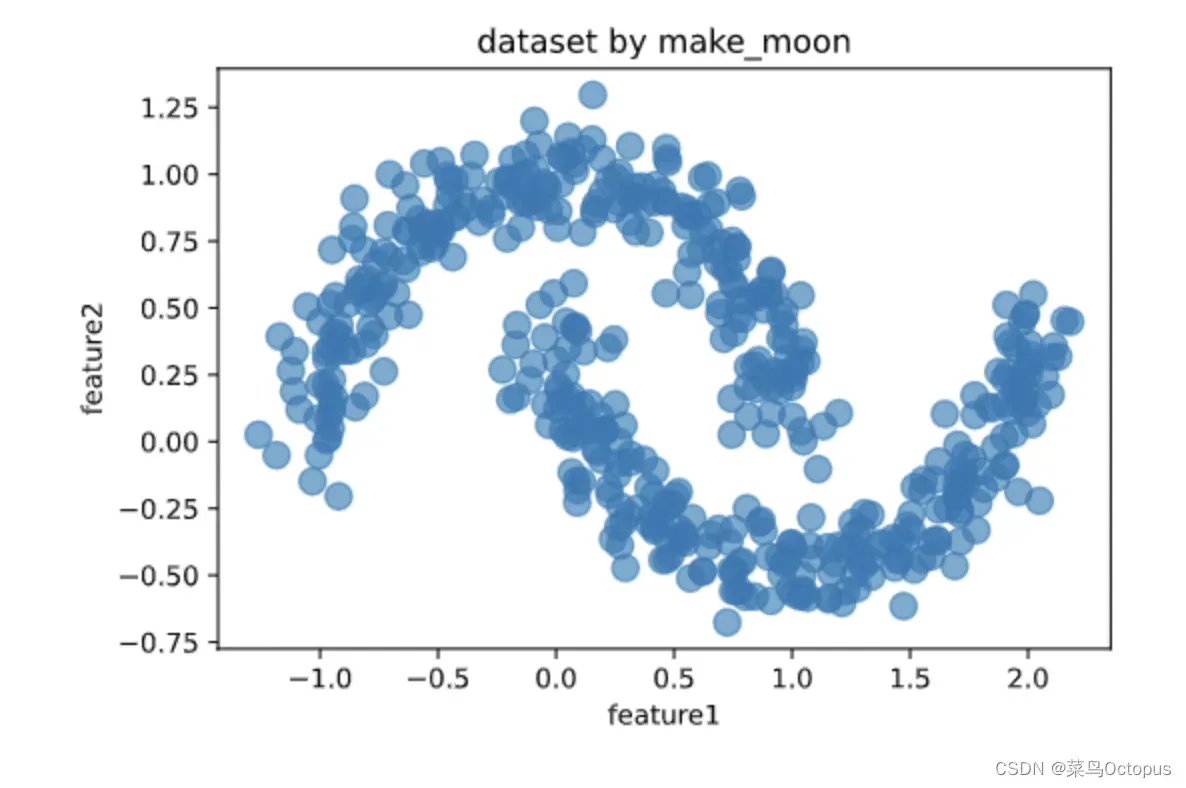
3)调用dbscan方法完成聚类
%matplotlib inline
%config InlineBackend.figure_format = 'svg'
from sklearn.cluster import dbscan
# eps为邻域半径,min_samples为最少点数目
core_samples,cluster_ids = dbscan(X, eps = 0.2, min_samples=20)
# cluster_ids中-1表示对应的点为噪声点
pdf = pd.DataFrame(np.c_[X,cluster_ids],columns = ['feature1','feature2','cluster_id'])
pdf['cluster_id'] = pdf['cluster_id'].astype('i2')
pdf.plot.scatter('feature1','feature2', s = 100,
c = list(pdf['cluster_id']),cmap = 'rainbow',colorbar = False,
alpha = 0.6,title = 'sklearn DBSCAN cluster result'); 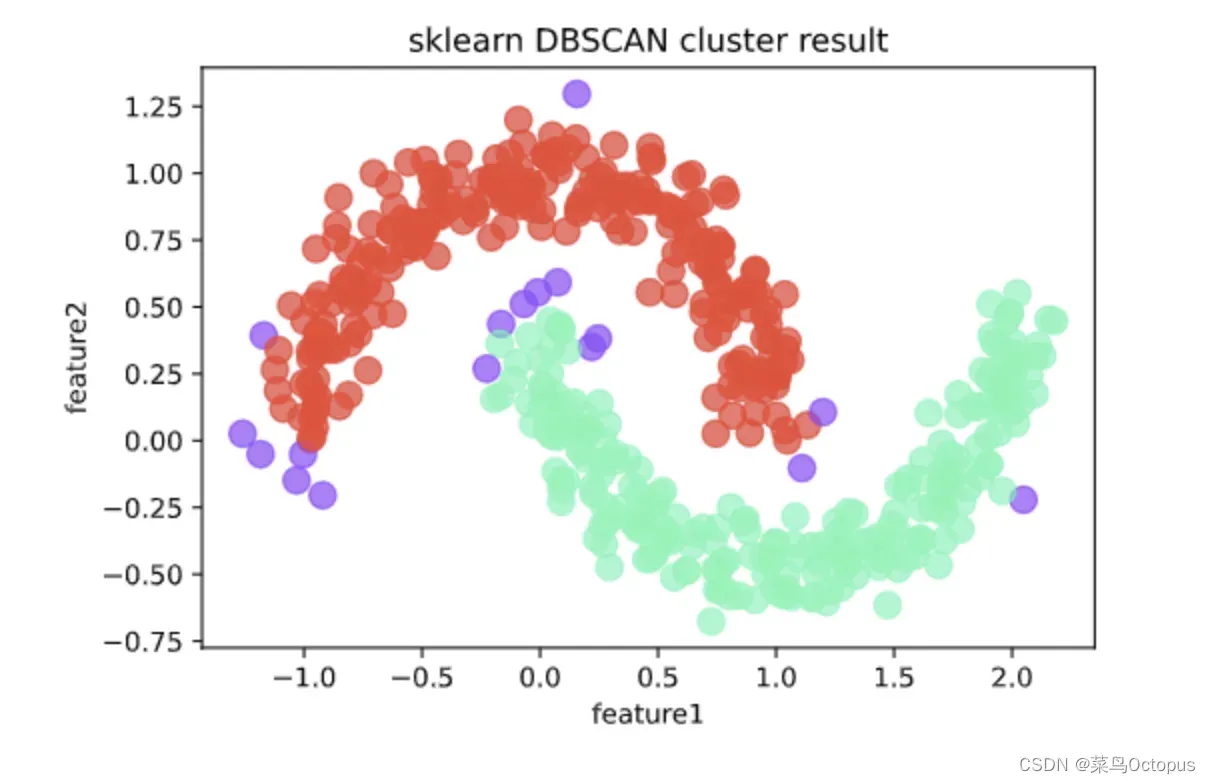
文章出处登录后可见!
已经登录?立即刷新