


论文地址:https://arxiv.org/pdf/2102.10772.pdf
相关博客:
【自然语言处理】【多模态】CLIP:从自然语言监督中学习可迁移视觉模型
【自然语言处理】【多模态】ViT-BERT:在非图像文本对数据上预训练统一基础模型
【自然语言处理】【多模态】BLIP:面向统一视觉语言理解和生成的自举语言图像预训练
【自然语言处理】【多模态】FLAVA:一个基础语言和视觉对齐模型
【自然语言处理】【多模态】SIMVLM:基于弱监督的简单视觉语言模型预训练
【自然语言处理】【多模态】UniT:基于统一Transformer的多模态多任务学习
一、简介


然而,尽管
- 仅应用在单个领域或者特定模态的任务上;
- 对于每个任务涉及任务相关的微调,没有在任务间利用共享参数,通常
- 仅在单个领域中的相关或者相似任务上执行多任务,有时会使用硬编码的训练策略;例如,








在本文中,作者构建了一个称为hidden states,在编码后的输入模态上应用一个

- 提出了
- 学习视觉领域、文本领域和交叉领域的最突出的任务,包括目标检测、
- 通过对各种任务的分析,展示了像





二、

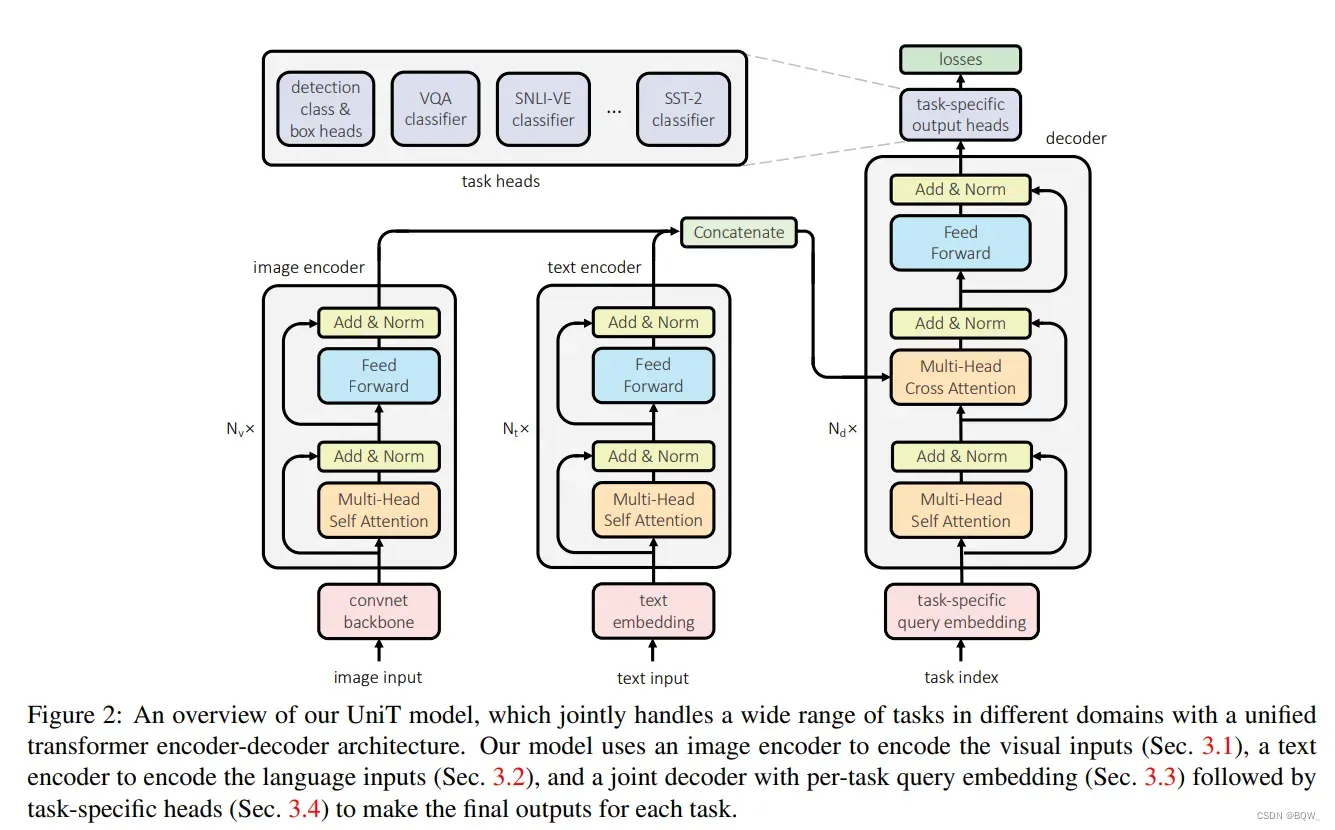

本工作中,使用统一的单个模型联合学习跨不同模态的多任务。模型
本文考虑图像和文本两种输入模态。对于图像上的基于


作者实验表明,
2.1 图像编码器
单独的视觉任务和”视觉-语言”任务需要感知和理解图像
在实现中,卷积网络使用





为了进一步编码出尺寸为













2.2 文本编码器
像QNLI,MNLI,QQP,SST-2等GLUE基准,以及VQA和visual entailment等视觉语言推理任务都会提供文本输入。这里使用BERT来编码文本输入。
给定输入文本,以与BERT相同的方法将其转换为长度为S的token序列BERT中来抽取尺寸为BERT的hidden size。类似于图像编码器,文本编码器也会token序列前添加一个可学习任务嵌入向量
然而,在实践中发现仅保留[CLS]对应的向量来作为解码器的输入就能达到同样的效果。







在本文的实现中,使用BERT-base-uncased,其


2.3 领域不可知
在将输入模态编码后,应用一个hidden size为hidden state序列



对于纯视觉任务,解码器应用在编码后的图像



query嵌入序列
解码器的架构同DETR中实现的解码器。在解码器的第




在实现时,要么对所有任务使用单个共享的解码器


2.4 任务相关的输出头
每个任务hidden state box头来为bounding box。分类头和box头的实现如同DETR。对于每个box上具有属性标签的数据集,实现类似BUTD中的属性分类头 。


类别头和box头的输出会被后处理为object bounding box。对解码器所有层hidden state
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ \textbf{c}^l&=…
其中,box和属性的输出序列,所有的长度均为query嵌入

在测试时,仅使用从解码器顶层得到的预测值box头和属性头。在DETR,在BUTD。




本文中所有的任务,包括:视觉问答、visual entailment和自然语言理解hidden state




为了预测输出类别,使用具有GeLU激活函数的两层hidden size。使用预测值
KaTeX parse error: No such environment: align at position 8: \begin{̲a̲l̲i̲g̲n̲}̲ \textbf{p}&=W_…


2.5 训练
在多个任务上联合训练batch。根据数据集的大小和经验来人工指定每个任务的抽样概率。在本文的实现中,模型在64块Nvidia Volta V100-SXM2-32GB的GPU上进行训练,batch size为64。使用具有学习率为5e-5的加权Adam优化器。
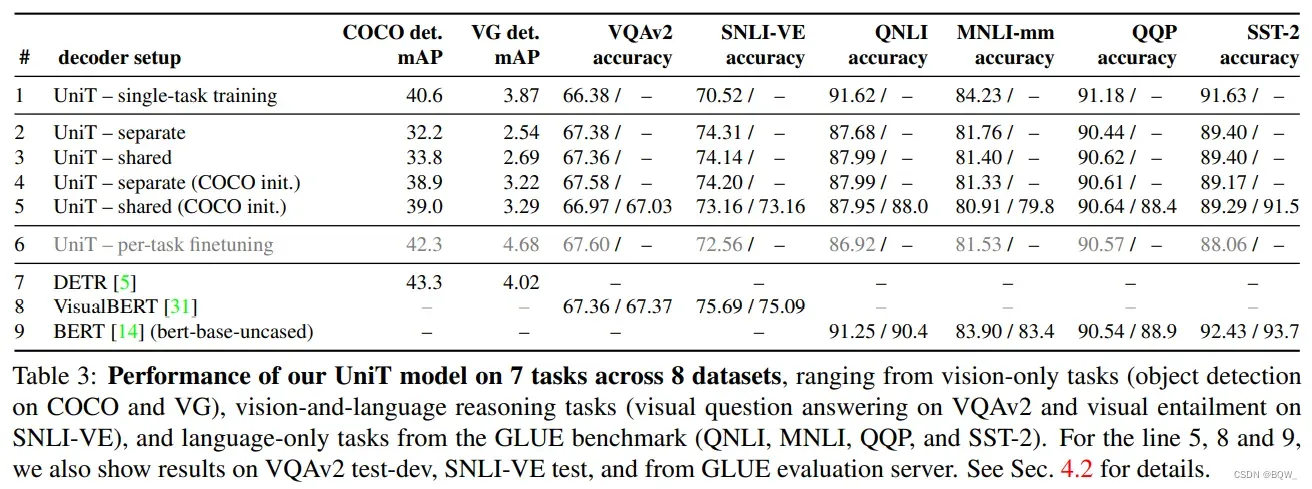
三、实验

四、总结
- 单纯将两个模态的模型进行联合训练,理论上没有太多可以借鉴的;
- 实验结果以及训练过程具有借鉴意义。
文章出处登录后可见!