摘要
摘 要 在东亚,书写汉字一直是一项重要的技能。然而,由于汉字数量大,手写汉字的自动生成面临着很大的挑战。目前已有各种机器学习技术用于汉字识别,但对手写体汉字的生成问题,特别是在训练数据不配对的情况下,研究较少。在这项工作中,我们将中文手写字符的生成定义为学习从现有印刷字体到个性化手写风格的映射问题。我们进一步提出用 DenseNet CycleGAN生成汉字。我们的方法不仅适用于常用汉字,也适用于具有美学价值的书法作品。此外,我们提出内容准确性和风格差异作为评价
指标,以评估手写字符的质量。然后,我们使用我们提出的指标来评估从 CASIA 数据集和我们新引入的兰亭书法数据集生成的字符。
Abstract—Handwriting of Chinese has long been an important skill in East Asia. However , automatic generation of handwritten Chinese characters poses a great challenge due to the large number of characters. Various machine learning techniques have been used to recognize Chinese characters, but few works have studied the handwritten Chinese character generation problem, especially with unpaired training data. In this work, we formulate the Chinese handwritten character generation as a problem that learns a mapping from an existing printed font to a personalized handwritten style. We further propose DenseNet CycleGAN to generate Chinese handwritten characters. Our method is applied not only to commonly used Chinese characters but also to calligraphy work with aesthetic values. Furthermore, we propose content accuracy and style discrepancy as the evaluation metrics to assess the quality of the handwritten characters generated. We then use our proposed metrics to evaluate the generated characters from CASIA dataset as well as our newly introduced Lanting calligraphy dataset.
关键词 手写汉字,生成对抗网络,densenet
I. INTRODUCTION
三千多年来,世界上四分之一的人口一直在使用汉字。长久以来,书写汉字一直是东亚地区教育、就业、交流和日常生活中最基本的技能之一。长期以来,好的书法或书法不仅被认为是一种艺术表达的语言,而且被认为是最高的视觉艺术,作为一种自我表达和修养的手段。例如,图 1 显示了我们生成的一些书法字符。这些赏心悦目的书法作品通常需要多年的奉献和实践。与英语等字母数量非常有限的语音语言相比,汉语有超过 8 万个字母。因此,它是更多比语音语言更具挑战性的个性化汉字字体设 计。例如,个性化的英文字体只需要设计 26 个字母,而中文字体至少需要设计 3000 个最常用的字符。为了满足个性化汉字字体设计的需求,需要基于相对较小的训练字符集,自动生成具有个性化手写风格的汉字。

虽然手写体汉字的生成没有像字符识别那样得到广泛的研究,但是有 arXiv:1801.08624v1 [cs。CV] 25 Jan 2018 仍然是手写汉字生成的方法。以往的研究大多依赖于简单笔画的层次化表示[27,26,17]。他们将汉字分解成笔画,然后结合笔画来模仿个性化的书写风格。因此,这种方法只关注字符的局部表示,而不是整体样式,因此需要为每个新字符调整笔画的形状、大小和位置。相反,zi2zi[25]学习使用pix2pix[9]和成对的字符图像作为训练数据进行字体转换。然而,在手写汉字生成任务中,由于要求用户
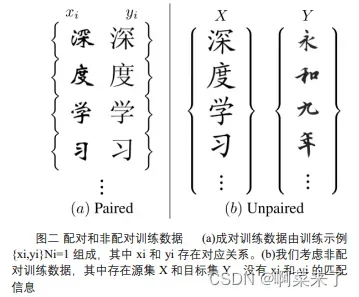
书写大量汉字是不可行的,因此很难获得大量的成对训练样本集。笔迹样本也经常与用户的书写分离,不知道字符的真实标签。此外,即使是用户编写的相同字符,每次都是不同的,这使得学习整体风格比模仿每个字符更重要。因此,对于手写汉字的生成问题,使用未配对的汉字而不是成对的数据更为合适。图 2 提供了配对和非配对训练数据的示例。成对的训练数据包含两种字体中相同字符的图像,而未配对的数据不一定包含相同的字符集。
在这项工作中,我们将中文手写字符的生成定义为学习从现有印刷字体到个性化手写风格的映射问题。为了解决这一问题,我们进一步提出了一种基于非配对图像-图像转换的方法。我们
的主要贡献是:
1、我们建议使用 DenseNet CycleGAN 生成个性化手写风格的汉字。
2、我们建议将内容准确性和风格差异作为评价指标,以评估生成的角色的质量。
3、我们在 CASIA 数据集[16]和我们新引入的兰亭书法数据集上证明了我们提出的方法的有效性。
II. RELATED WORK
2.1 汉字手写生成
汉字生成的研究始于数字时代[20]。在文献中,汉字生成主要表现为艺术书法、字体生成问题[27,25,28,14]或个人笔迹生成问题[26,15,22]。以前的大多数研究都依赖于简单笔画的层次表
示[27,26] 作为代表汉字的基础。例如,StrokeBank[32]将汉字分解为组件树。FlexiFont[19]扫描并处理相机捕获的手写字符图像,然后将这些字符格式化为个性化的 TrueType 字体文件。自动形
状变形[14]首先为每个字符生成形状模板,然后将给定的两个汉字分解为笔画,建立笔画之间的精确对应关系,实现非刚性点集配准。最近,令人惊叹的字体设计[28]探索了为字体设计生成特效的问题,并利用文本效果空间分布的高规律性的统计信息来指导合成过程。Zi2zi[25]将每个汉字视为一个整体,并用成对的训练数据学习在字体之间进行转换。然而,在个性化汉字手写字体生成任务中,很难获得大量的成对训练样本。
2.2 图片风格转移
目前的图像风格传递方法可以分为两大类,即基于图像迭代的描述神经方法和基于模型迭代[10]的生成神经方法。描述神经方法通过直接计算源图像的梯度和迭代更新图像中的像素来传递样式,而生成神经方法首先优化生成模型,通过一次前向传递生成样式的图像。[2]是一种应用最广泛的描述性神经方法,用于用另一种风格再现一幅图像的内容。它将风格的传递定义为一个结合了纹理合成和内容重建的优化问题。在[13,1]中,基于补丁的损失是在内容和风格损失的基础上增加的。描述神经方法的缺点是迭代更新算法只适用于单个图像,如果要传输多幅图像的风格,需要耗费大量的时间。相比之下,生成神经方法速度较快,但通常生成较差的样式迁移结果。然而,我们的手写汉字的生成问题并不完全属于神经样式转移领域。特别是,由于笔画的位置和角度有很大的不同,所以很难定义不同字体之间的内容损失。例如,图 2(a)中的“xi”和“yi”虽然代表相同的汉字,但对应的图像却有很大的不同。
2.3 生成对抗的网络
GANs. 生成对抗网络(GANs)[4]是一种强大的生成模型,在许多计算机视觉任务如图像修复[7]和图像到图像翻译[31],以及自然语言处理任务如语音合成[18]和跨语言学习[11]中取得了令人印象深刻的结果。GANs 将生成模型表述为两个竞争网络之间的博弈:一个生成器网络在给定一些输入噪声的情况下生成合成数据,而一个鉴别器网络区分生成器的输出和真实数据。形式上,产生器 G 和鉴别器 D 之间的博弈具有极大极小目标:
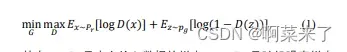
其中 x ~ Pr 是来自输入数据的样本,z ~ Pg 是随机噪声样本,G(z)是使用神经网络生成器 G 生成的图像,D(·)给出了输入是真实的概率。
cGANs and pix2pix. 与 GANs 学习从随机噪声向量到输出图像的映射不同,有条件的 GANs (cgan)学习从随机噪声向量到附加信息条件的输出图像的映射。cga 能够进行图像到图像的转换,因为它们可以根据输入图像设定条件并生成相应的输出图像。Pix2pix[9]是一个使用 cga的通用图像到图像转换算法。它可以对各种各样的问题产生合理的结果。给定一个包含相关图像对的训练集,pix2pix 学习如何将一种类型的图像转换为另一种类型的图像,或者反之亦然。
Zi2zi. Zi2zi[25]在没有笔画标记或其他难以获取的辅助信息的情况下,利用 GAN 实现了汉字在不同字体之间的端到端转换。zi2zi 的网络结构基于 pix2pix,增加了多种字体的类别嵌入。这使得 zi2zi 能够通过一个训练过的模型将字符转换为几种不同的字体。Zi2zi 使用源字型和目标字型的汉字配对作为训练数据。然而,由于获取大量的成对训练样本用于个性化手写汉字的生成是不现实的,因此 zi2zi 不适用于我们的问题。
CycleGAN. 循环一致的 gan (CycleGANs)在没有配对示例[31]的情况下学习图像转换。相反,它在输入图像和输出图像之间循环训练两个生成模型。除了对抗性损失外,还利用周期一致性损失来避免两种生成模型之间的矛盾。CycleGAN 的缺省生成器架构是 ResNet[5],缺省鉴别器架构是 PatchGAN 的分类器[9]。
III. MATH

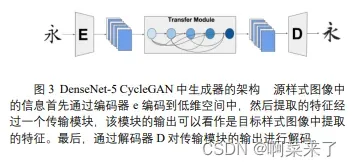
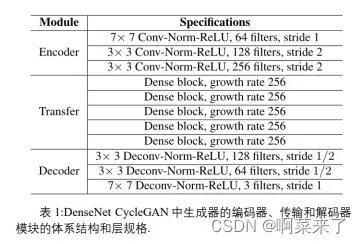
映射 G: X→Y 可以看作 gan 中的生成器,只不过生成器的输入是来自源域的图像而不是随机噪声。生成器G的架构示例如图3所示。学习样式的映射工作如下:来自域 X的图像中的信息首先通过表 1 中给出的编码器编码到较低维。然后,从源域提取的特征经过一个传输模块。传输模块的输出可以看作是从目标域提取的特征。最后,通过解码器对传输模块的输出进行解码,如表 1所示。
一个对抗性鉴别器 DG,它是一个 70×70 PatchGAN[9],被用来评估目标域中生成的图像的资格。第二个映射 F: Y→X 和对应的鉴别器 DF 可以类似地定义。鉴别器的目的是区分来自目标域的真图像和来自源域的图像由生成器产生的伪图像。CycleGAN 的损失函数包括两部分:对抗损失和循环一致性损失。一方面,对抗损失的目的是将生成的图像的分布与目标域中的数据分布进行匹配。

除了 ResNet,密集卷积网络(DenseNet)[6]是卷积神经网络的最新发展之一。它通过将所有块直接连接在一起,进一步改善了跨块的信息流。’ -th 块接收所有前面块的特征映射𝑥0,…,𝑥𝑙−1为输入,

式中[𝑥0,…,𝑥𝑙−1]表示在块 0…𝑙 − 1中产生的特征映射的拼接。DenseNets 在几个竞争激烈的数据集上实现了最先进的分类精度,比 ResNets 使用更少的参数和更少的计算。受 DenseNets 设计的启发,我们在转换模块中加入了DenseNet块,提出了一种带有 DenseNet生成器架构的 CycleGAN (DenseNet CycleGAN)来生成手写汉字。如表 1 所示,我们的DenseNet CycleGAN 中的传输模块由 DenseNet 块而不是 ResNet块组成。
IV. EXPERIMENTS
在本节中,我们在两个公开的数据集上评估我们提出的方法。此外,我们建议内容准确性和风格差异作为视觉外观之外的补充评价指标。主要结果将在本节中显示。
4.1. 数据集
CASIA-HWDB 数 据 集 。 中 文 手 写 体 数 据 库 CASIAHWDB[16]是一个应用广泛的中文手写体字符识别数据库[30,29]。该数据库包含了 1020 名作者使用 Anoto 笔在纸上书写的孤立字符和手写文本的样本。
在本研究中,我们使用 CASIA-HWDB 中的 HWDB1.1 数据集。它包含 300 个文件(在 HWDB1.1 训练集中 240 个,在HWDB1.1 测试集中 60 个)。每个文件包含大约 3000 个由一个作者书写的独立的灰度汉字图像,以及它们对应的标签。孤立的字符图像被调整为 128 × 128 像素。除了调整大小之外,没有执行其他数据预处理方法。
对于生成手写字符的任务,我们使用 HWDB1.1 数据集中的文件 HW252 (1252-c.gnt)作为目标样式,SIMHEI 字体作为源样式。SIMHEI 是一种常用的中文字体。图 4 显示了汉字“永”的 5种不同风格。前两种是打印字体,后三种是手写字体。

兰亭书法数据集。中国书法是一种具有审美情趣的书写形式,在中国广泛应用,在中国文化界普遍受到高度重视。在这个作品中,我们以王羲之的书法作品为例,他被公认为中国历史上最伟大的书法家。王羲之最著名的作品是《兰亭记序》,由 324 个半草书组成。
《兰亭集序》中的每个字都是从手稿中扫描出来的。它们被进一步二值化并使用中值滤波去噪。最后,字符被填充成正方形并调整为 128 × 128 像素。由此产生的数据集称为蓝厅书法数据集。图 7 中第一列中的字符是来自兰亭书法数据集的示例。此任务使用的源字体是常规样式的 SIMKAI 字体。数据集可以在这找到 :https://github.com/changebo/HCCGCycleGAN/blob/master/lanting.zip。
4.2 性能指标
生成模型通常缺乏客观的评价标准,这使得生成的图像质量难以定量评价。为了衡量我们的手写字符生成方法在 CASIAHWDB 数据集上的性能,我们提出了两个互补的评价指标:内容准确性和风格差异。两种评估都基于一个预先训练好的网络:HCCR-GoogLeNet[30],这是一个基于 GoogLeNet[23]的手写
汉字分类模型。
内容的准确性。HCCR-GoogLeNet 模型使用 CASIA-HWDB手写字符数据库进行训练,该数据库共有 1020 个写入者,其中包括 HW252。达到了目前最先进的汉字分类精度。受《盗梦空间》评分[21]的启发,预先训练的 HCCR-GoogLeNet 模型可以用来评估生成的手写字符的质量。直觉是,如果生成的字符是真实的,预先训练的 HCCR-GoogLeNet 也将能够正确地对生成的字符进行分类。在我们的例子中,目标样式中的字符是从源样式中的可用图像生成的。因此,所生成字符的真实标签是已知的。如
果预先训练的字符识别模型能够对生成的字符进行准确的分类,在一定程度上说明生成模型是高质量的。
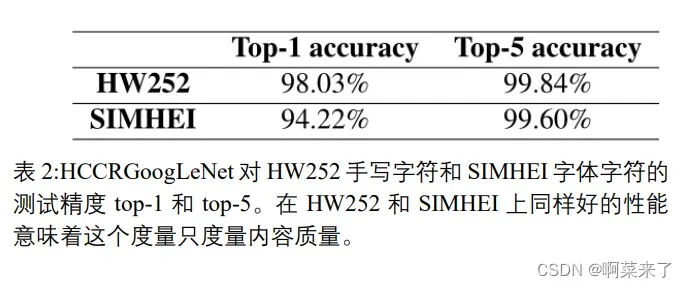
表 2 显示了 HCCR-GoogLeNet 以 HW252 手写体字符和SIMHEI 字体字符为基准的测试精度。较高的识别精度表明,HCCR-GoogLeNet 精度是一种可靠的质量测量指标。然而,在HW252 和 SIMHEI 上同样好的性能意味着这个度量是从单一的角度来度量生成质量的:它只评估内容质量,而不是风格质量。因此,HCCRGoogLeNet 对生成的手写体字符的识别精度称为内容精度。
风格差异。为了度量目标域中真实字符与生成字符之间的风格差异,我们借用了神经风格传递算法[2]中的风格损失。其思想是在一个层上使用不同过滤器激活之间的相关性作为样式表示。
特征相关性由 Gram 矩阵𝐺 𝑙∈𝑅 𝑁𝑙✖𝑁𝑙×𝑁𝑙给出,其中𝑁𝑙为第 l-th层的滤波器个数,𝐺𝑖𝑗 𝑙 为层的向量化特征映射 i 与 j 的内积:

因此,样式差异被定义为目标字符的样式表示与生成的字符之间的均方根差。差异越小,风格质量越好。在我们的实验中,我们使用 HCCRGoogLeNet 中的 Inception module 3 的输入作为layer’来计算风格差异。
我们进行了两个基线实验,以获得风格差异的大致范围。(a) HW252 手写数据集中两个随机等分子集的风格差异。由于这两个子集是同一个人写的,具有相同的风格,所以结果代表风格差异的下限。风格差异下限为 503.77。(b) HW252 与 SIMHEI 的风格差异。这就是源样式和目标样式之间的样式差异。因此,它代表了风格上最可能的分歧,并衡量了一个琐碎的身份风格转移模型的风格质量。因此可以认为是风格差异的上界。风格差异上限为 3006.03。
4.3 实现细节
在实验中,我们考虑了两种类型的传输模块:ResNet 的 6 块(ResNet-6)和 DenseNet 的 5块(DenseNet-5)。DenseNet-5传输模块与 ResNet-6 传输模块的参数数量大致相同。
我们使用的唯一预处理过程是将训练图像的大小调整为 128 × 128 像素;没有使用其他预处理方法(如剪切和翻转)。所有实验均设置正则化强度 λ = 10,使用批量大小为 1 的 Adam 优化器[12]。前 100 个 epoch 的学习率设置为 0.0002。 然后在接下来的 100 个纪元线性衰减到 0。实验中每个历元的迭代次数是这两种类型中训练示例数量较多的一个。
4.4 手写字符的结果
我们使用 SIMHEI 字体作为源样式,使用 HW252 中的手写字符作为目标样式。SIMHEI 和 HW252 都被拆分为未配对训练集和验证集。在实际应用中,我们希望用户只书写少量的汉字,在此基础上,使用我们提出的方法根据用户的个人风格生成其余的手写汉字。因此,本实验的目标是使用小的训练集对
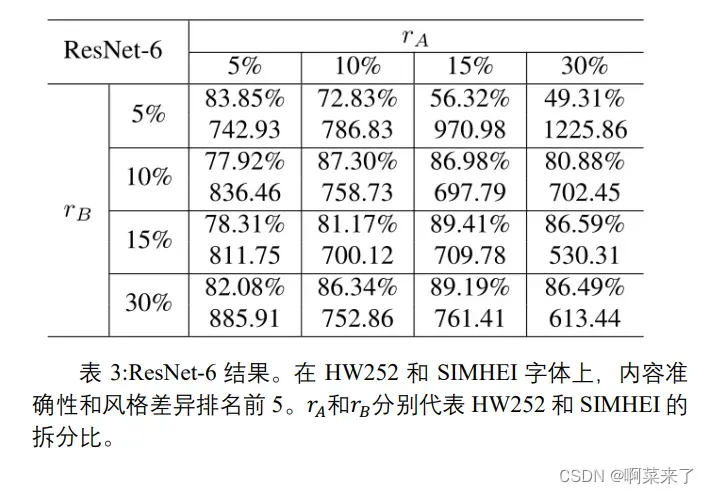
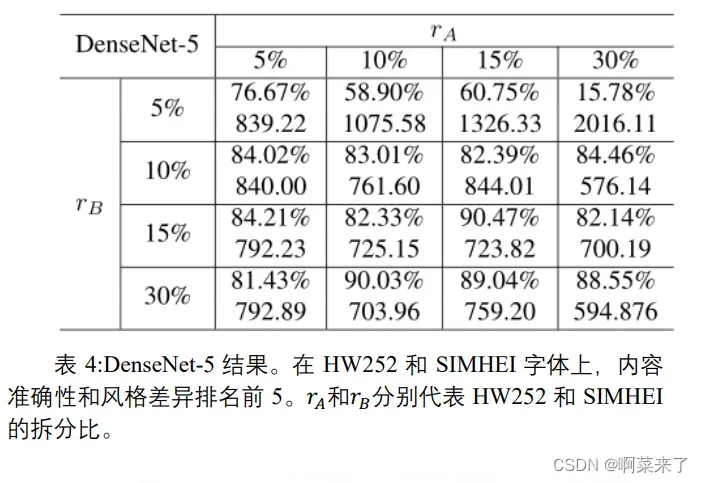
CycleGAN 模型进行训练,并对验证集进行样式传递。设𝑟𝐴为HW252 的分割比,即将 HW252 中字符的𝑟𝐴随机分配到训练集中,其余字符在验证集中。𝑟𝐴为 SIMHEI 的拆分比。𝑟𝐴和𝑟𝐵取值为{5%,10%,15%,30%},共 16 种组合。表 3 和表 4 分别显示了ResNet-6 和 DenseNet-5 的内容准确性和风格差异前 5 名。结果表明,随着训练数据的增加,内容质量和风格质量都有所提高。特别是当𝑟𝐴和𝑟𝐵大于 10%时,含量准确度始终大于 80%。ResNet-6和 DenseNet-5 的性能不相上下。此外,由于风格差异的范围在503.77 和 3006.03 之间,风格差异处于谱系的低端。
图 5 显示了使用 DenseNet-5 和 ResNet-6 生成的手写字符,以及源和目标样式。生成的文字背景清晰,内容完全可识别。笔画的风格与源字体明显不同。词根的构成和笔画界限的模糊与作者的书法风格非常相似。图 6 是由 ResNet-6 CycleGAN 生成的汉字组成的中国名诗《在鹳塔上》。所有的角色都是清晰的,具有个性化的风格。
4.5 书法的结果
我们使用 SIMKAI 作为王羲之风格书法创作的源字体。总体而言,DenseNet 在风格上略微优于ResNet。图 7 显示了在给定未配对训练数据的情况下,兰亭书法数据集中前四个字的地面真度以及生成的书法字符。可以看出, CycleGAN 同时使用DenseNet 和 ResNet generator,捕捉到了王羲之的整体写作风格,并产生了合理的输出。与 ResNet 相比,DenseNet 倾向于产生更少的笔画缺失情况(例如,第一个字符中的点)或多笔画(例如,第二个字符中多余的丢弃)的情况。尽管如此,DenseNet 和 ResNet
的生成器都未能学习到王的半草书风格的某些特征。例如,对于第二行的“他”字,在半草书中,“扔掉”(向左下坠)和“按下”(向右下坠)的笔画通常被简化为一个“断”(方向上的改变)笔画。这个特性不是由 CycleGAN 模型学习的:DenseNet 和 ResNet 都生成单独的“丢弃”和“按下”笔画。
图 1 的最后两列也是王羲之风格生成的中国书法的例子。这些汉字不在原始蓝厅书法数据集中,生成的汉字性能良好。

4.6 与神经类型迁移的比较
我们使用 VGG-19 作为预训练网络,将我们的方法与神经传递[2]进行了比较。我们使用vg -19的relu4 2层来丢失内容,relu1 1, relu2 1, relu3 1, relu4 1, relu5 1 层来丢失样式。采用 SIMHEI 字体中的两个字符作为内容图像,其中 30%的字符从 HW252 数据集中随机选取作为样式图像。同样设置𝑟𝐴=30%.通过神经样式转移生成的结果如图 8 所示。可以看到,生成的图像的样式几乎与源字体相同,这意味着学习的转换是微不足道的。此外,生成的图像背景模糊。整体的视觉质量比我们的方法产生的质量差。


V. CONCLUSION
在这项工作中,我们将中文手写字符的生成问题定义为学习从现有印刷字体到个性化手写样式的映射。我们提出了DenseNet CycleGAN 来解决这个问题,我们的方法使用 DenseNet作为 CycleGAN 生成器的一部分来提高生成质量。将该方法与带有 ResNet 块和 Neural style transfer 的原始 CycleGAN 方法进行了比较。我们在 CASIA 数据集和新引入的兰亭书法数据集上评价了该方法。在此基础上,提出了两种新的汉字生成性能评价指标:内容准确性和风格差异,用于定量评价生成的汉字质量。大量的实验结果证明了我们的方法的有效性,显示出优越的或相当的性能。
想法
这里我已经把这个代码按照他的思想进行了复现,效果不是太好。可能是因为他是最先想到把这个东西应用到cycleGAN里面的。只需要进行小小的修改就可以了。
代码链接:https://github.com/wangjin173/HCCG-CycleGAN
文章出处登录后可见!