



首先YoloX的项目代码来自Bubbliiiing,Swin Transformer的项目代码来自太阳花的小绿豆。感谢两位大佬在GitHub上面提供的资源。
Swin Transformer取如下三个有效特征层:
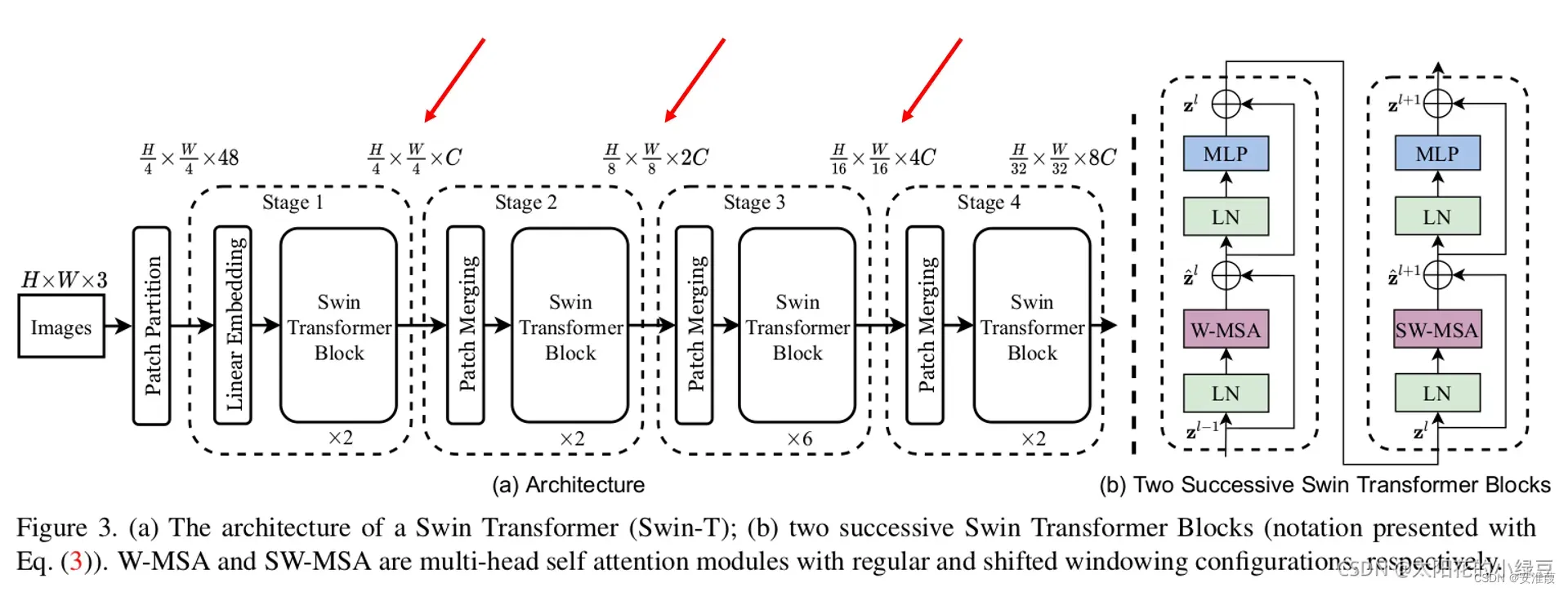
作为骨干网络的输出引入yolox的三个有效特征层:
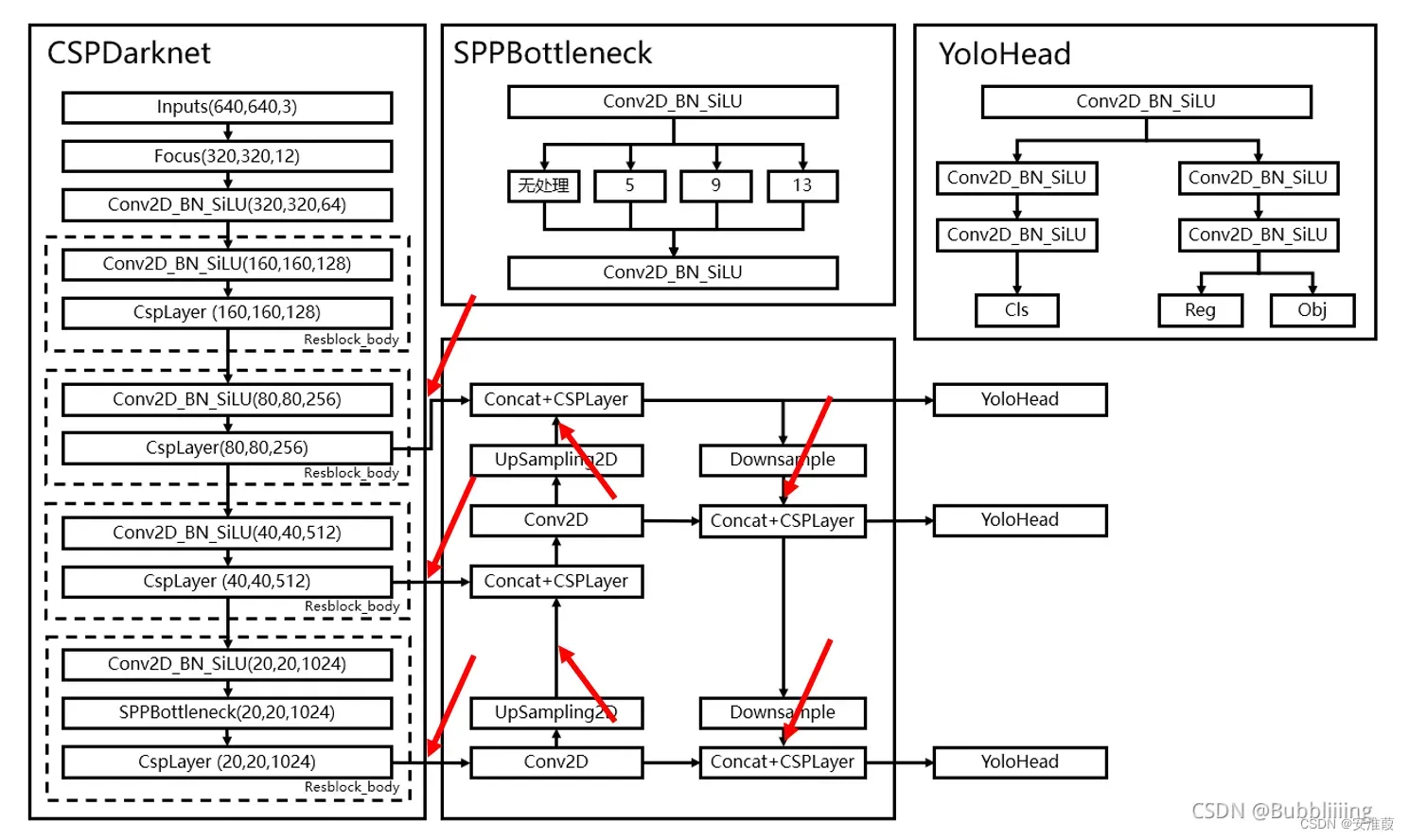
在左边三个箭头引入Swin Transformer输出的特征。即可完成骨干网络的替换。

引入骨干网络
我是直接复制model.py文件到我的nets/目录下,方便yolo.py文件import。
model.py文件来自太阳花的小绿豆GitHub下deep-learning-for-image-processing-master/pytorch_classification/swin_transformer/model.py
修改模型搭建过程:
# build layers
self.layer1 = BasicLayer(dim=int(embed_dim * 2 ** 0),
depth=depths[0],
num_heads=num_heads[0],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:0]):sum(depths[:0 + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (0 < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layer2 = BasicLayer(dim=int(embed_dim * 2 ** 1),
depth=depths[1],
num_heads=num_heads[1],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:1]):sum(depths[:1 + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (1 < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layer3 = BasicLayer(dim=int(embed_dim * 2 ** 2),
depth=depths[2],
num_heads=num_heads[2],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:2]):sum(depths[:2 + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (2 < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
self.layer4 = BasicLayer(dim=int(embed_dim * 2 ** 3),
depth=depths[3],
num_heads=num_heads[3],
window_size=window_size,
mlp_ratio=self.mlp_ratio,
qkv_bias=qkv_bias,
drop=drop_rate,
attn_drop=attn_drop_rate,
drop_path=dpr[sum(depths[:3]):sum(depths[:3 + 1])],
norm_layer=norm_layer,
downsample=PatchMerging if (3 < self.num_layers - 1) else None,
use_checkpoint=use_checkpoint)
修改forward函数:
def forward(self, x):
# x: [B, L, C]
x, H, W = self.patch_embed(x)
x = self.pos_drop(x)
feature4x = x
# for layer in self.layers:
# x, H, W = layer(x, H, W)
feature8x, H, W = self.layer1(feature4x, H, W)
feature16x, H, W = self.layer2(feature8x, H, W)
feature32x, H, W = self.layer3(feature16x, H, W)
feature64x, H, W = self.layer4(feature32x, H, W)
# x = self.norm(x) # [B, L, C]
# x = self.avgpool(x.transpose(1, 2)) # [B, C, 1]
# x = torch.flatten(x, 1)
# x = self.head(x)
return feature4x, feature8x, feature16x, feature32x, feature64x
至此我们引入了feature下采样4,8,16,32,64倍的特征层,我们将使用8,16,32下采样倍率的部分。
YOLOPAFPN层修改
首先import进模型:
from .model import swin_base_patch4_window7_224
其次修改backbone:
self.backbone = swin_base_patch4_window7_224()
我这里使用的是base模块。
在__ init __函数中修改
self.feature32x2feat3 = nn.Conv2d(1024, int(in_channels[2] * width), kernel_size=1)
self.feature16x2feat2 = nn.Conv2d(512, int(in_channels[1] * width), kernel_size=1)
self.feature8x2feat1 = nn.Conv2d(256, int(in_channels[0] * width), kernel_size=1)
在forward函数中修改(加入到最前面):
def forward(self, input):
feature4x, feature8x, feature16x, feature32x, feature64x = self.backbone.forward(input)
# print("orignalfeature32size:", feature32x.size())
# print("orignalfeature16size:", feature16x.size())
# print("orignalfeature8size:", feature8x.size())
feature32x_sqrt = int(math.sqrt(feature32x.size()[1]))
feature16x_sqrt = int(math.sqrt(feature16x.size()[1]))
feature8x_sqrt = int(math.sqrt(feature8x.size()[1]))
feature32x = feature32x.permute(0, 2, 1).contiguous().view(-1, 1024, feature32x_sqrt, feature32x_sqrt)
# print("after reshape feature32:", feature32x.size())
feature16x = feature16x.permute(0, 2, 1).contiguous().view(-1, 512, feature16x_sqrt, feature16x_sqrt)
# print("after reshape feature16:", feature16x.size())
feature8x = feature8x.permute(0, 2, 1).contiguous().view(-1, 256, feature8x_sqrt, feature8x_sqrt)
# print("after reshpae feature8:", feature8x.size())
feat3 = self.feature32x2feat3(feature32x)
feat2 = self.feature16x2feat2(feature16x)
feat1 = self.feature8x2feat1(feature8x)
将原本的feat3,feat2,feat1替换为使用Swin Transformer的特征。
修改配置phi == ‘l’为其他值只会更改FPN层中的通道宽度。对swin transformer的backbone没有影响。
无法使用预训练权重
因为对模型的backbone进行了更改,因此无法载入预训练权重,会报错key不匹配的问题。
model_path = ""
# model_path 置为空,不读取预训练权重
#------------------------------------------------------------------#
Init_Epoch = 0
Freeze_Epoch = 0
Freeze_batch_size = 16
#------------------------------------------------------------------#
# 解冻阶段训练参数
# 此时模型的主干不被冻结了,特征提取网络会发生改变
# 占用的显存较大,网络所有的参数都会发生改变
# UnFreeze_Epoch 模型总共训练的epoch
# Unfreeze_batch_size 模型在解冻后的batch_size
#------------------------------------------------------------------#
UnFreeze_Epoch = 300
Unfreeze_batch_size = 16
#------------------------------------------------------------------#
# Freeze_Train 是否进行冻结训练
# 默认先冻结主干训练后解冻训练。
#------------------------------------------------------------------#
Freeze_Train = False
需要将Freeze_Train 设置为 False,这样模型不加载预训练权重,所有层全部开始训练,非常占显存。
大功告成!
文章出处登录后可见!
已经登录?立即刷新