在pandas中,value_counts常用于数据表的计数及排序,它可以用来查看数据表中,指定列里有多少个不同的数据值,并计算每个不同值在该列中的个数,同时还能根据需要进行排序。
函数体及主要参数:
value_counts(values,sort=True, ascending=False,
normalize=False,bins=None,dropna=True)
参数说明:
sort=True: 是否要进行排序;默认进行排序
ascending=False: 默认降序排列;
normalize=False: 是否要对计算结果进行标准化,并且显示标准化后的结果,默认是False。
bins=None: 可以自定义分组区间,默认是否;
dropna=True:是否删除缺失值nan,默认删除
首先,我们还是先创建一个数据表:
代码如下:
import pandas as pd
df = pd.DataFrame({'城市': ['北京', '广州', '青岛', '上海', '杭州', '成都', '青岛', '南京', '北京', '北京', '上海'],
'收入': [10000, 10000, 5000, 5000, 40000, 50000, 8000, 5000, 5000, 5000, 10000],
'年龄': [50, 43, 34, 40, 25, 25, 45, 32, 25, 25, 34]})
#inplace=True的作用:
#如果为 True,则原地修改 DataFrame(不创建新对象)
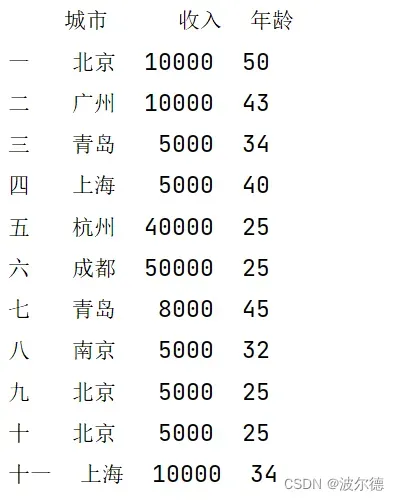
df.set_index([["一", "二", "三", "四", "五", "六", "七", "八", "九", "十", "十一"]], inplace=True)
print(df)
运行结果:
(1)查看“城市”这一列的计数结果:
1.1源码:
print(df['城市'].value_counts())
1.2运行结果:

(2)采用升序的方式,查看“收入”这一列:
2.1源码:
print(df['收入'].value_counts(ascending=True))
2.2 运行结果:

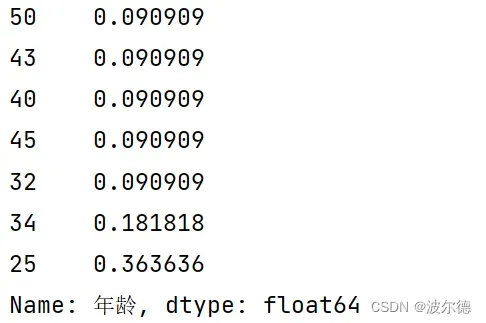
3)使用标准化normalize=True的方法,查看“年龄”这一列的计数占比:
3.1源码
print(df['年龄'].value_counts(ascending=True,normalize=True))
3.2运行结果
文章出处登录后可见!
已经登录?立即刷新