基于百度飞桨paddleocr技术
苏格拉底两千多年前就警醒过我们:人啊,认识你自己,这句不仅被作为神谕镌刻在雅典阿波罗神庙外的柱子上,也成了一众哲学家从未停止探讨的问题。可笑的是,这句一直用来提醒自己的话在某种特殊情况下已被遗忘干净,在未充分对工作进行调研的前提下,我竟然无知地以为本任务需求明确、逻辑简单、容易实现,殊不知针对PDF的PCR识别集视觉领域的分类、检测、分割于一身。在经历一系列碰壁、思索、查阅、复现的过程后,我才勉强实现了这款识别效果不是特别鲁棒的PDF表格提取脚本。我是头猪。
1 技术综述
亡羊补牢,尚未晚矣。在意识到任务的难度后,我对任务进行了大体的调研,了解到针对PDF的OCR表格识别主要依靠两种技术:版面分析和表格识别。其中,版面分析利用检测相关技术,解决了表格内容的位置关系;表格识别利用分类和识别的技术,主要是基于版面分析结果对不同区域的表格内容进行识别。总的来说,不管是版面分析还是表格识别,现有方案可大致分为基于图像处理的传统方法和基于深度学习的方法。
1.1 基于图像处理的传统方法
版面分析比较著名的是 O’Gorman 在 1993 年 TPAMI 中发表的算法 Docstrum。算法的主要思想是通过自下而上的方法依次将图像中的黑白连通域划分为文字、文本行与文本块,从而得到版面布局。表格识别的传统方法通过腐蚀、膨胀等操作获得表格线、划分行列区域,然后将单元格与文本内容相结合重构为表格对象。但是这类算法在版面布局的分析和表格结构的提取上依赖各种阈值和参数的选择,对于不同场景下的文档图片难以保证鲁棒性和泛化性。
1.2深度学习方法
深度学习方法除了直接使用检测模型来对版面内容进行分类以外,还融合了检测、分割、GAN、Attention等众多前沿技术,不再依赖超参数的选择,而是通过神经网络主动地学习解决问题,具有更好的泛化性能。具体内容太多,这里不再赘述。
2 傻瓜式配置教程
1 安装anaconda
安装很简单,读者自行查阅,不再赘述。
anaconda官网下载地址:
https://www.anaconda.com/
国内镜像下载地址:
https://mirrors.tuna.tsinghua.edu.cn/anaconda/archive/?C=M&O=D
我用的版本百度云下载地址:
链接:https://pan.baidu.com/s/1fRJPjDgZc_JO0nGfcKF87A
提取码:50i0
2 安装Pycharm
pycharm官网分为专业版和社区版,专业版第一个月免费,社区版永久免费,安装教程读者自行查阅。
下载地址:https://www.jetbrains.com/pycharm/download/#section=windows
3 安装各种集成包
3.1 安装paddlepaddle
这里给大家安装的是cpu版本的飞桨2.3.0,省去了配置CUDA的一系列复杂操作,如果要配置GPU版本的飞桨,可以查阅我之前的文章。
python -m pip install paddlepaddle==2.3.0 -i https://mirror.baidu.com/pypi/simple
3.2 安装paddleocr
3.2.1 安装python_Levenshtein-0.12.2
需要自行下载本地安装,请将下载后的文件保存至D:\tmp,百度云地址:
链接:https://pan.baidu.com/s/1meV65eIuVLkfbDv8tnyG2w
提取码:sf10
pip install D:\tmp\python_Levenshtein-0.12.2-cp37-cp37m-win_amd64.whl
3.2.2 安装Shapely-1.8.1
需要自行下载本地安装,请将下载后的文件保存至D:\tmp,百度云地址:
链接:https://pan.baidu.com/s/1fisn8CYlIrtSIxmBINkFug
提取码:u2mg
pip install D:\tmp\Shapely-1.8.1.post1-cp37-cp37m-win_amd64.whl
3.2.3 安装paddleocr
pip install "paddleocr>=2.0.1"
3.3 更新protobuf
卸载旧版protobuf
pip uninstall protobuf
更新
pip install protobuf==3.20.1
3.4 安装 Layout-Parser
pip3 install -U https://paddleocr.bj.bcebos.com/whl/layoutparser-0.0.0-py3-none-any.whl
4 PDF表格提取识别脚本
思路:将指定页面的包含表格的PDF转换为图片,利用OCR技术识别图片中的表格内容
4.1 PDF2Image脚本
将PDF指定页码进行提取,转化为图片
import os
import fitz
def extractImage(pdf_path=r'input/YM2021.pdf',save_path=r'output/YM2021'):
base_path = pdf_path# 要检测的PDF路径
save_path= save_path# 检测结果保存文件路径
if not os.path.exists(save_path):# 创建保存文件路径
os.makedirs(save_path)
print("请输入要识别的页码:")
rec_page= list(map(int,input().split()))
zoom_rate=3# 设置图片相对于PDF文件在XY轴上的缩放比例,1~为放大,~1为缩小
zoom_x,zoom_y = zoom_rate,zoom_rate
trans = fitz.Matrix(zoom_x, zoom_y).prerotate(0)
print("=="*15,"\033[31m {} \033[0m开始转换".format(os.path.basename(base_path)),"=="*15)
doc = fitz.open(base_path) # 打开一个PDF文件,doc为Document类型,是一个包含每一页PDF文件的列表
for pg in rec_page:
pm = doc[pg-1].get_pixmap(matrix=trans, alpha=False) # 将其转化为光栅文件(位数)
new_full_name = os.path.basename(base_path).split(".")[0] # 保证输出的文件名不变
save_dir = os.path.join(save_path, "{}_page{}.jpg".format(new_full_name,pg))
pm.save(save_dir)
print('='*27,'Page:{} conversion finished'.format(pg),'='*27)
print("=="*15,"\033[31m {} \033[0m转换完成".format(os.path.basename(base_path)),"=="*15)
4.2 Image2Excel脚本
import os
import cv2
from paddleocr import PPStructure,save_structure_res
from pdf2imageDemo import extractImage
# 1.Set Path
pdf_path=r'input/YM2021.pdf'# 要检测的PDF路径
base_path=r'pdf2image/'+os.path.basename(pdf_path).split('.')[0]# 从PDF中提取图片后的保存路径,文件名称与PDf相同
save_folder = 'res/'+os.path.basename(pdf_path).split('.')[0]# 最终检测识别结果的保存路径,文件名称与PDF相同
# 2.PDF transpose to Image
extractImage(pdf_path,base_path)
# 3.OCR recognize Image table
table_engine = PPStructure(show_log=True)
for img_name in os.listdir(base_path):
print('=='*15,"🚀🚀正在识别\033[31m {} \033[0m🚀🚀".format(img_name),'=='*15)
img_path = os.path.join(base_path,img_name)
img = cv2.imread(img_path)
result = table_engine(img)
save_structure_res(result, os.path.abspath(save_folder),os.path.basename(img_path).split('.')[0])
print('=='*15,"🚀🚀识别完毕\033[31m {} \033[0m🚀🚀".format(img_name),'=='*15)
5 识别结果展示
5.1 终端控制
5.2 科研文献PDF表格提取
用CBAM的表格试了一下,效果炸裂!
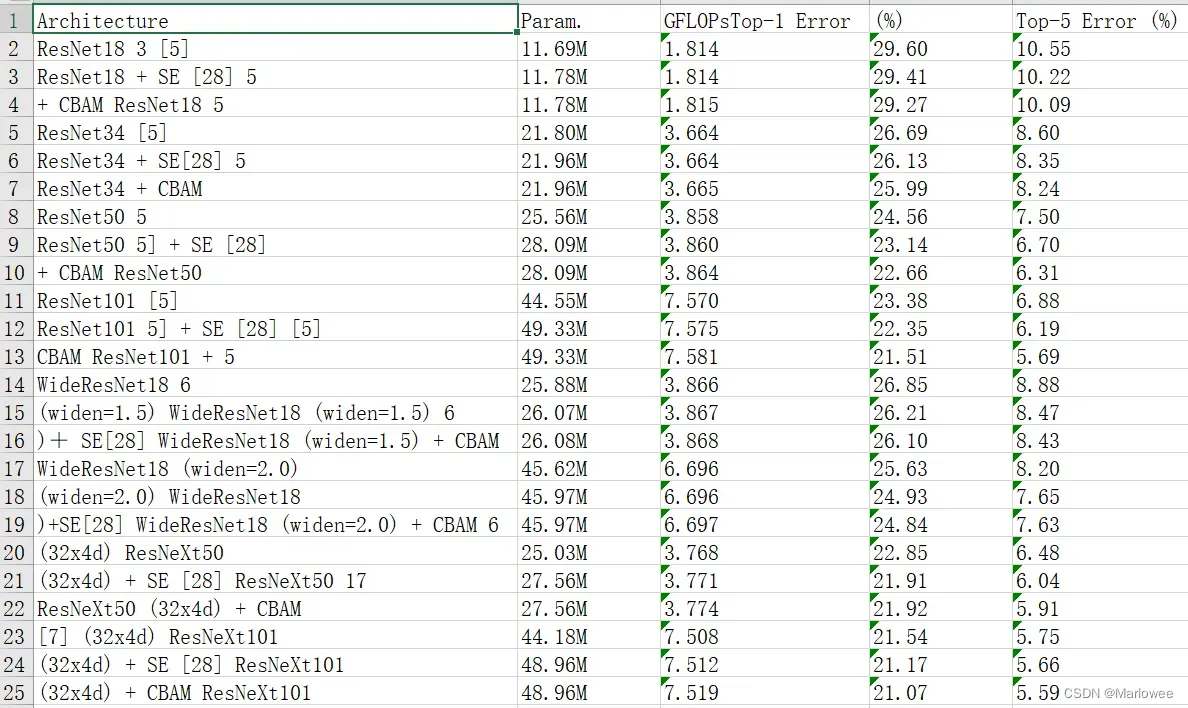
5.3 密集型PDF提取
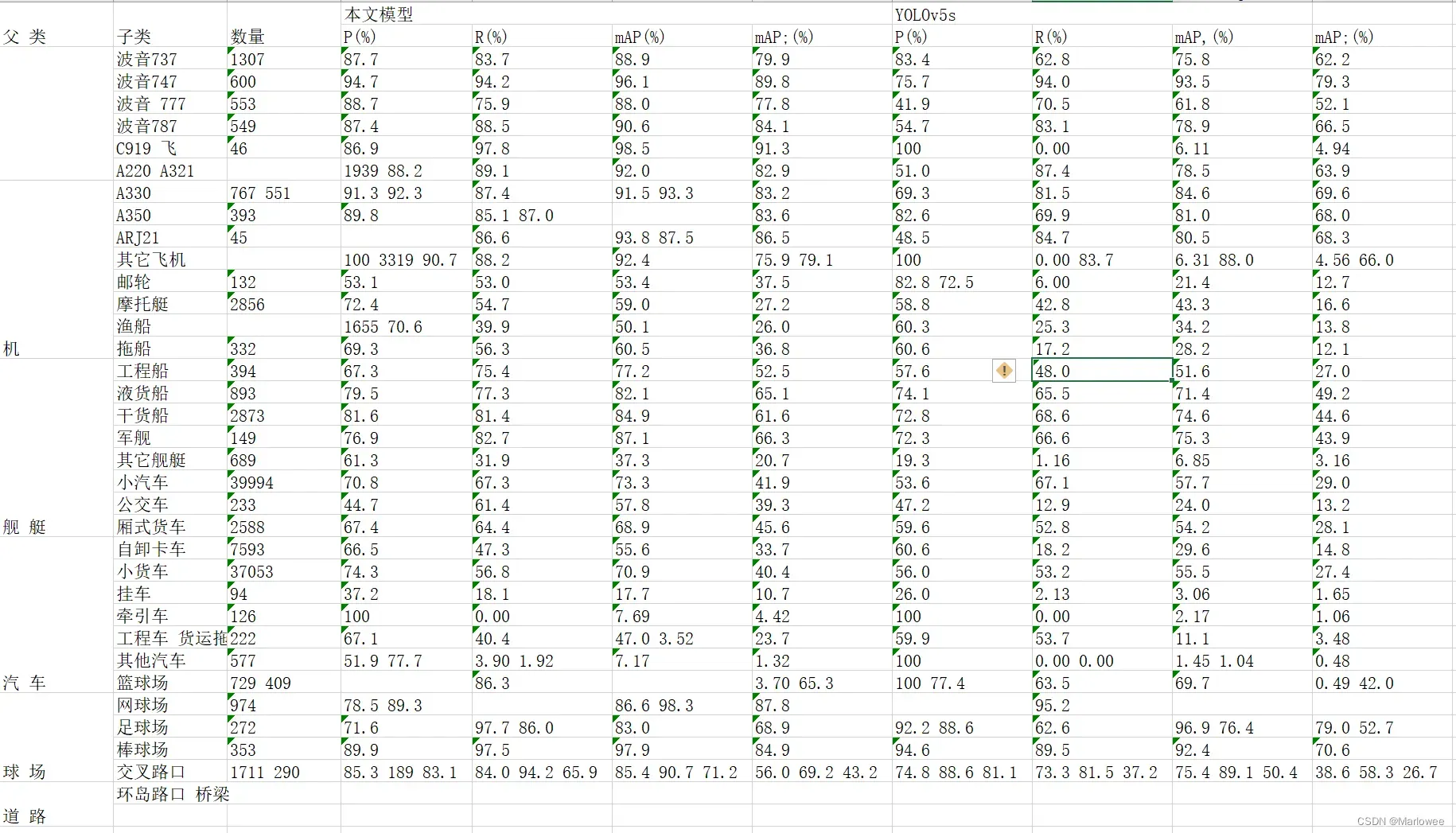
用自己的论文表格试了下,效果还不错
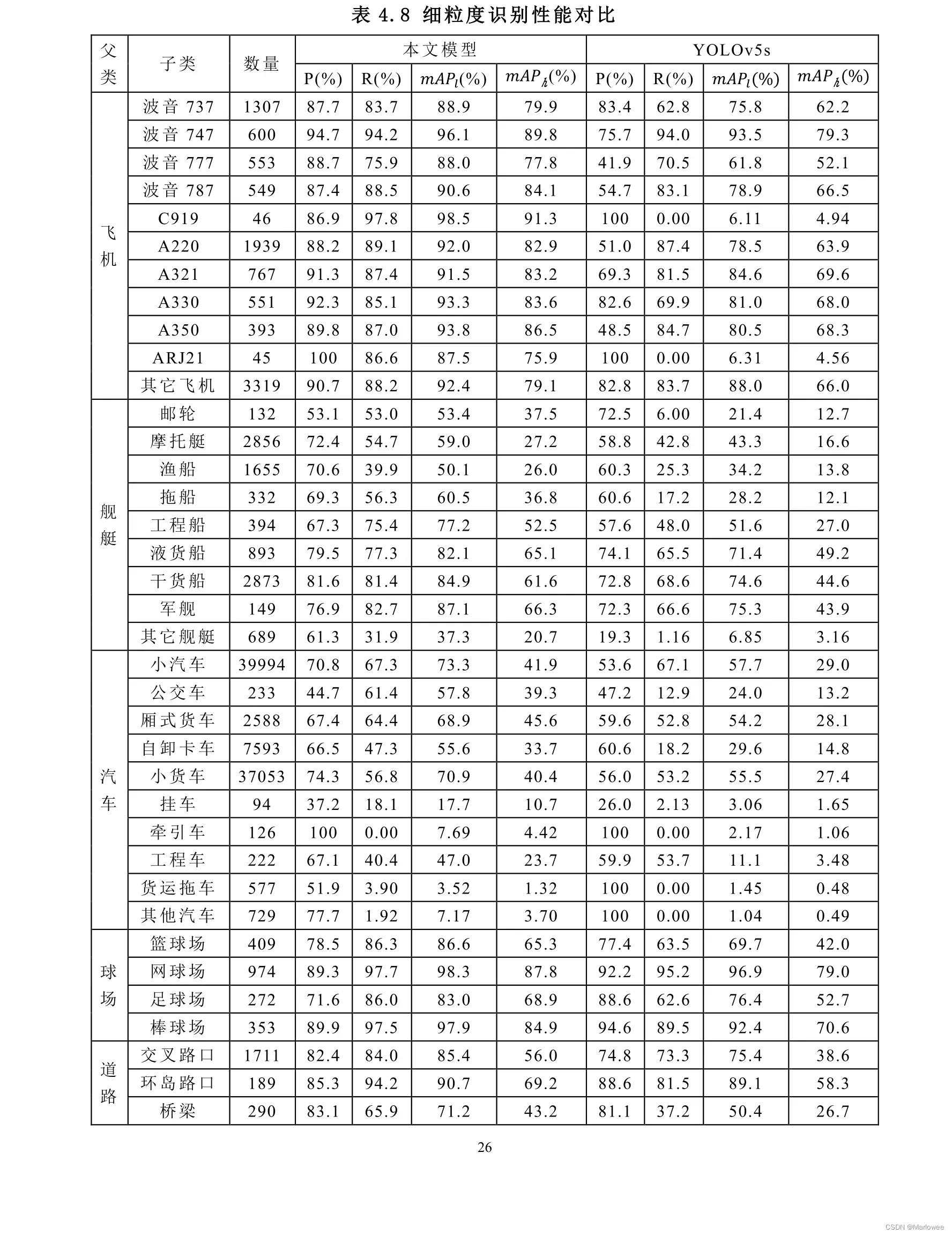
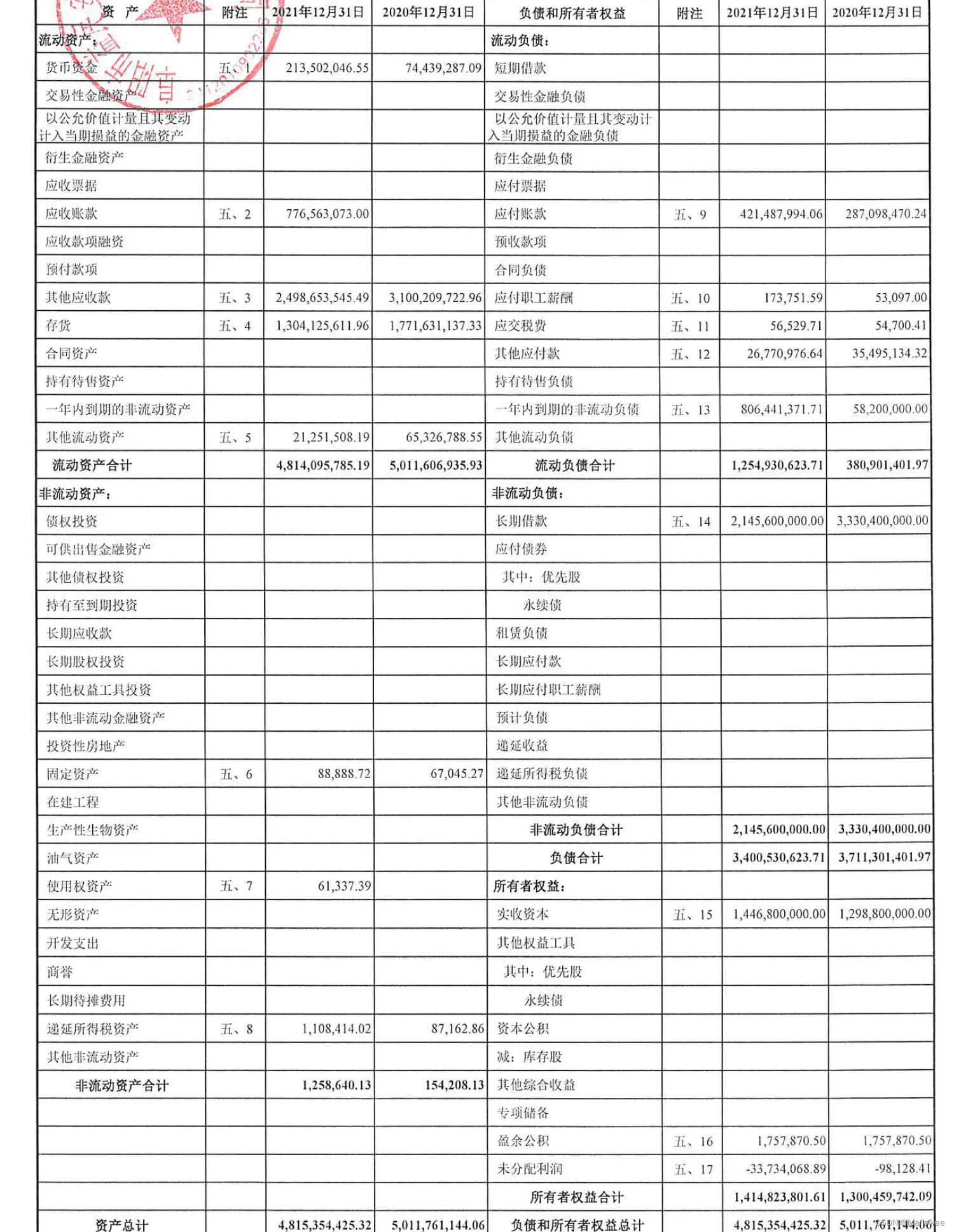
5.4 扫描版财务报表
效果一般,误检率挺高
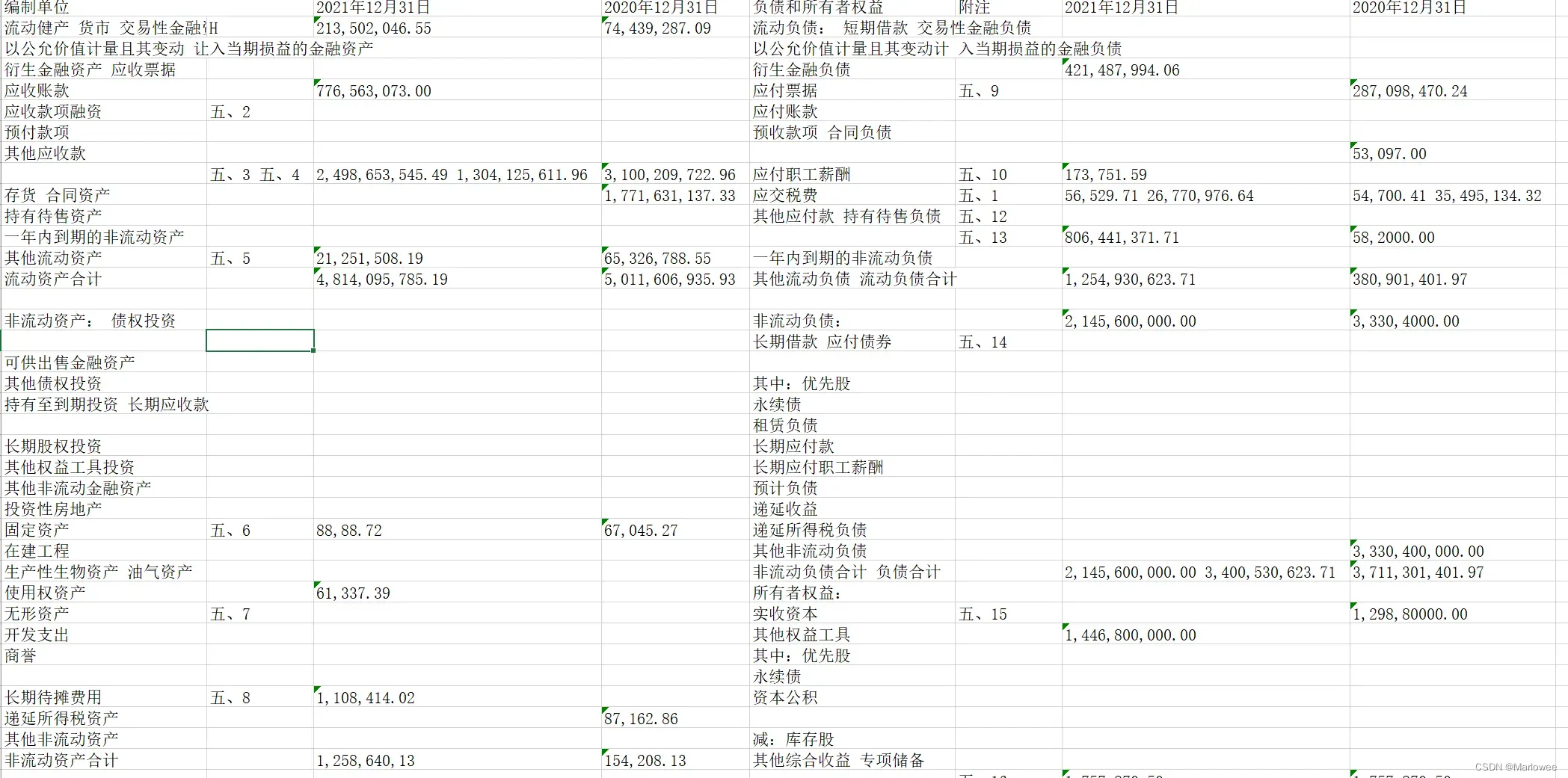
文章出处登录后可见!