目录
UNT(UntrimmedNets)
全名《UntrimmedNets for Weakly Supervised Action Recognition and Detection》。该论文是一篇CVPR2017年的论文。
现有的行为识别方法严重依赖于剪切过的视频数据来训练模型,然而,获取一个大规模的剪切过的视频数据集需要花费大量人力和时间。因此,我们提出了弱监督的网络结构UntrimmedNets,它能直接使用未剪切的视频进行学习,而不需要时序标注。
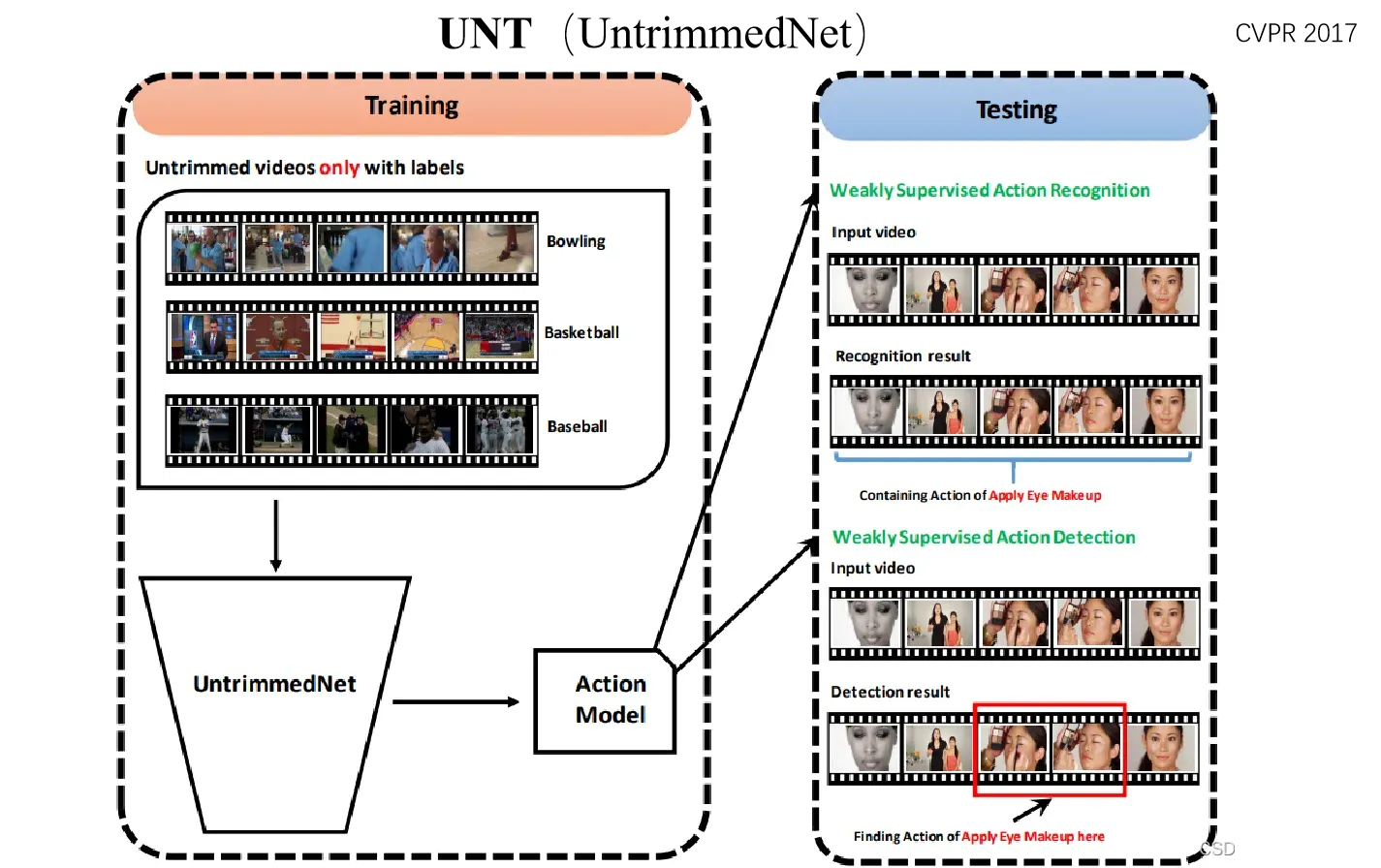
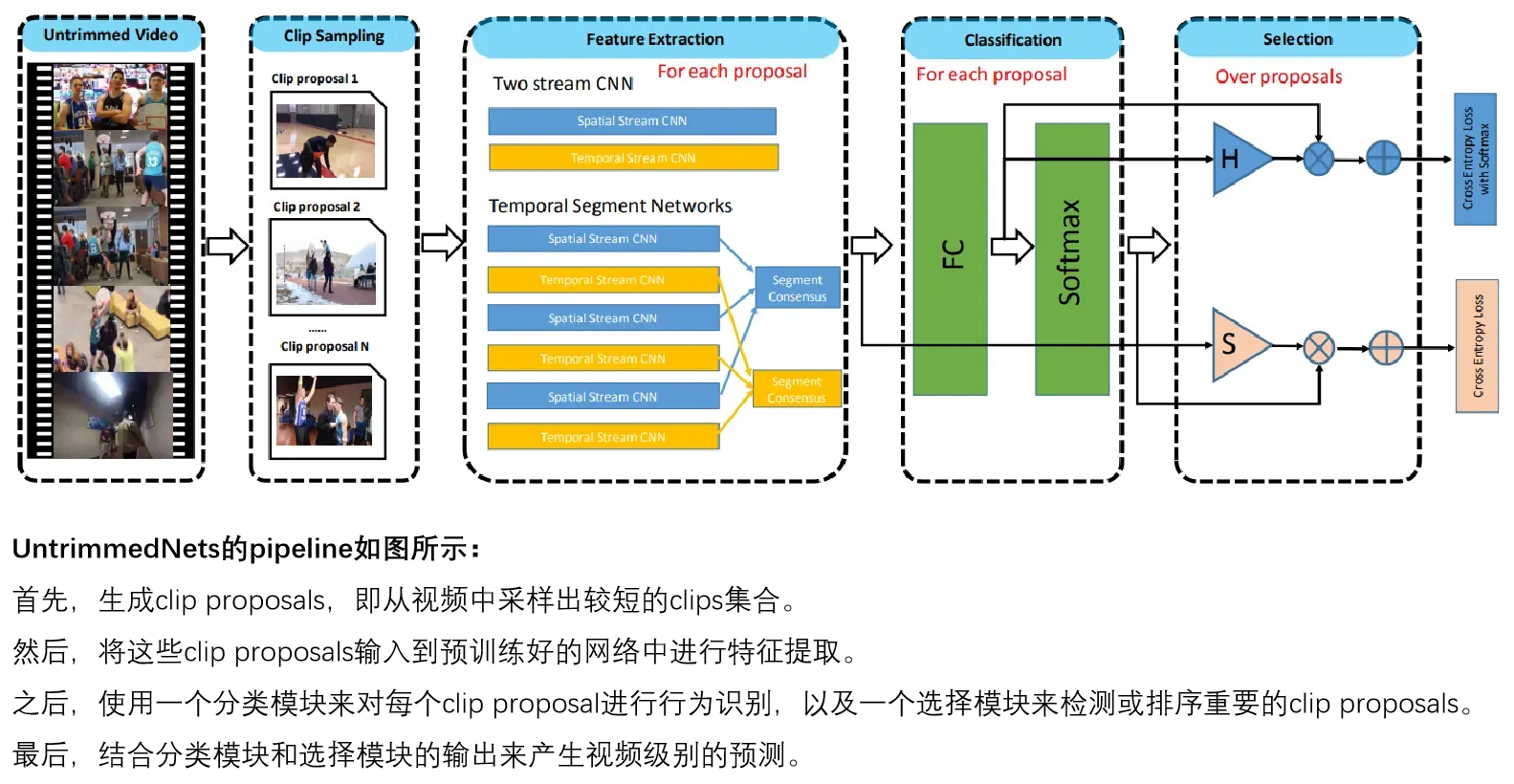
参考链接:[论文笔记]UntrimmedNet:弱监督行为识别与检测网络(CVPR 2017) – 知乎
I3D(Inflated 3D ConvNet)
全名《Quo Vadis,Action Recognition? A New Model and the Kinetics Dataset》。该论文是一篇CVPR2018年的论文。
使用了新的数据集Kinetics重新评估了当前最新的模型架构,Kinetics数集有400个人体行为类别,每个类别有400多个clips,这些数据来自真实有挑战的YouTube视频。作者提出的双流膨胀3D卷积网络(I3D),该网络是对一个非常深的图像分类网络中的卷积和池化kernel从2D扩展到了3D,来无缝的学习时空特征。并且模型I3D在Kinetics预训之后,I3D在基准数据集HMDB-51和UCF-101达到了80.9%和98.0%的准确率。
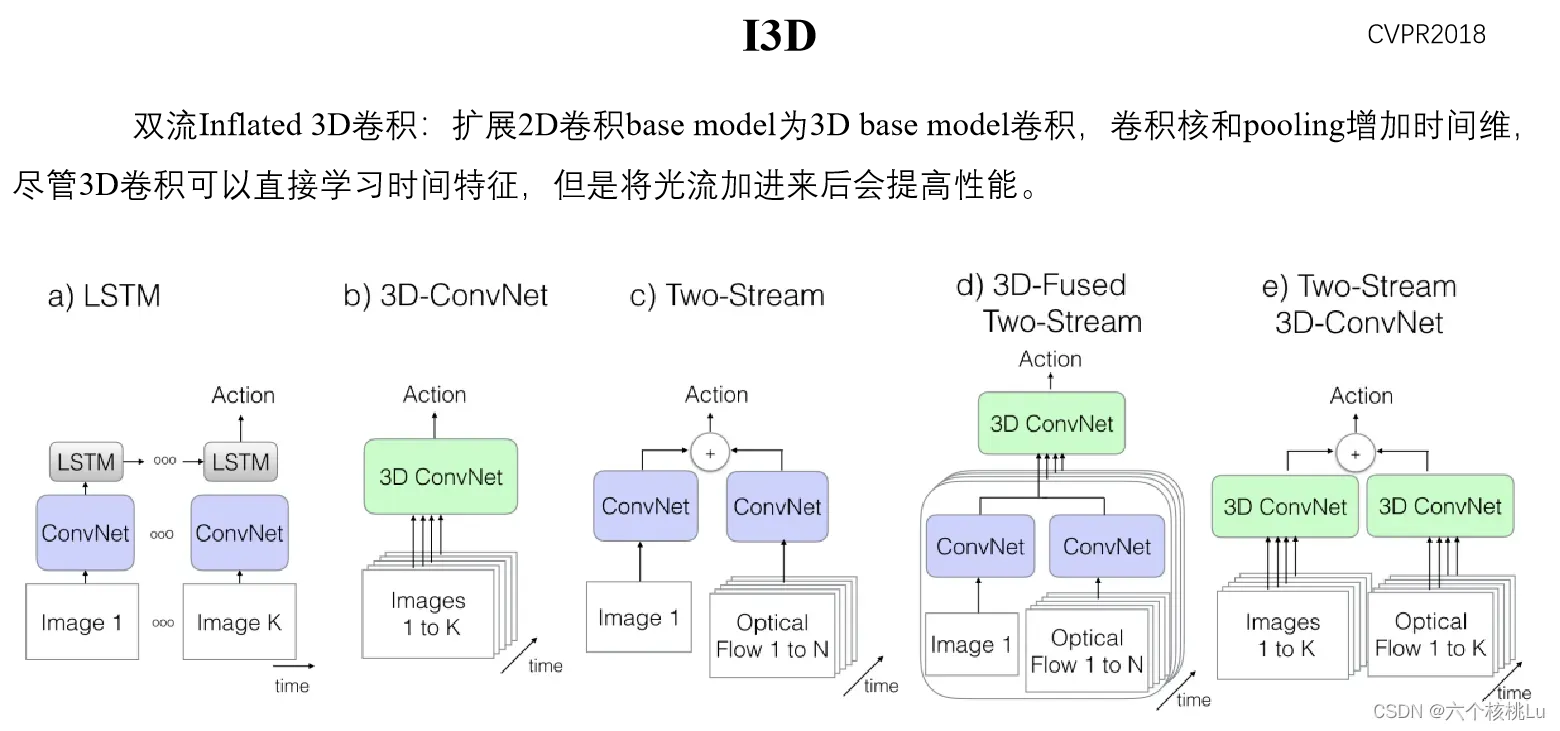
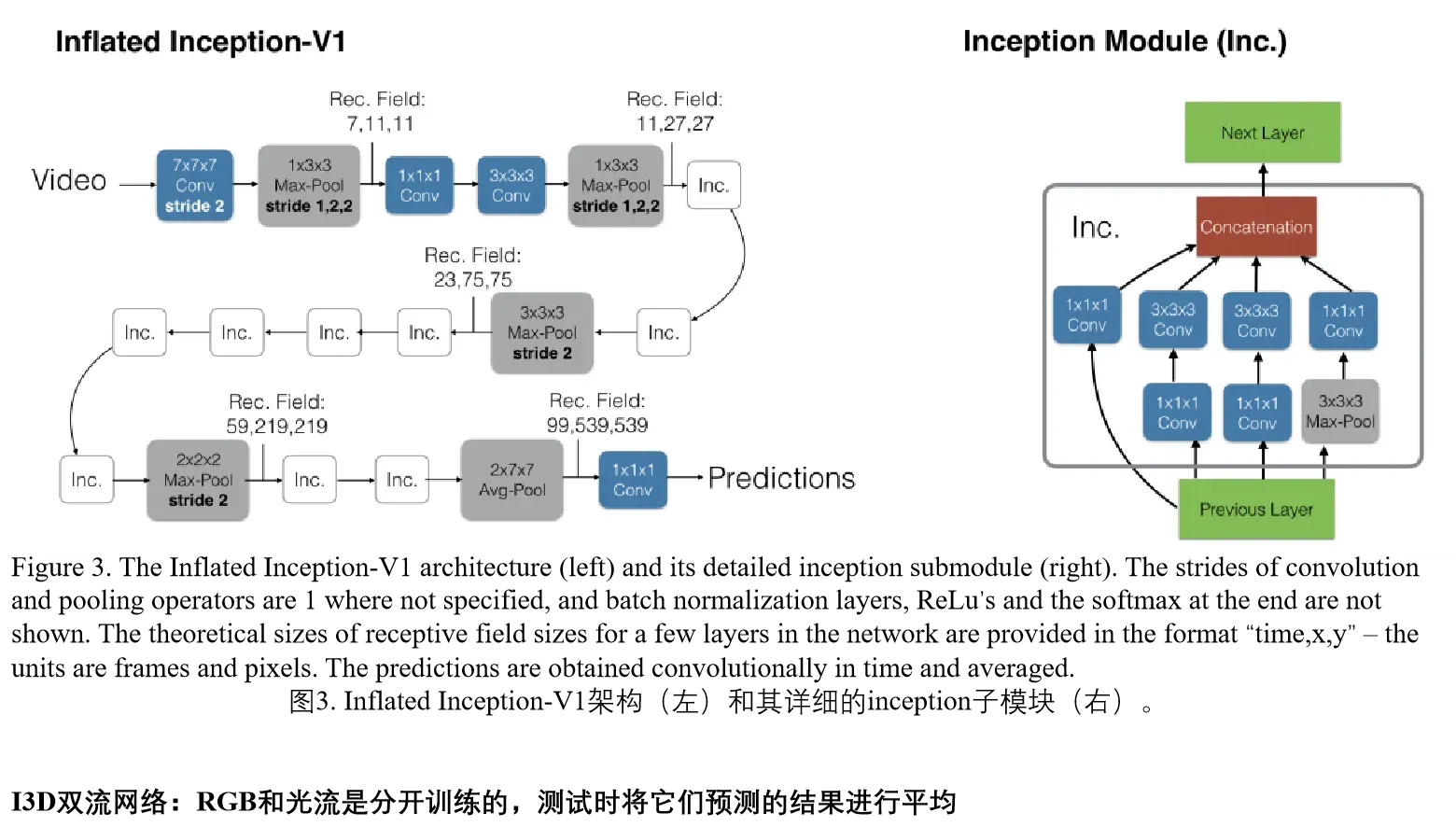
参考链接:https://blog.csdn.net/weixin_44402973/article/details/94396298
总结
通常使用I3D提取双流特征,得到的结果会好一些,一方面主要因为网络结构更深,另一方面使用3d卷积核,将时序信息包含进来,能提取更完备的视频特征。 UntrimmedNets是用采样的方法,使用2d网络提取特征。
文章出处登录后可见!