1.总述
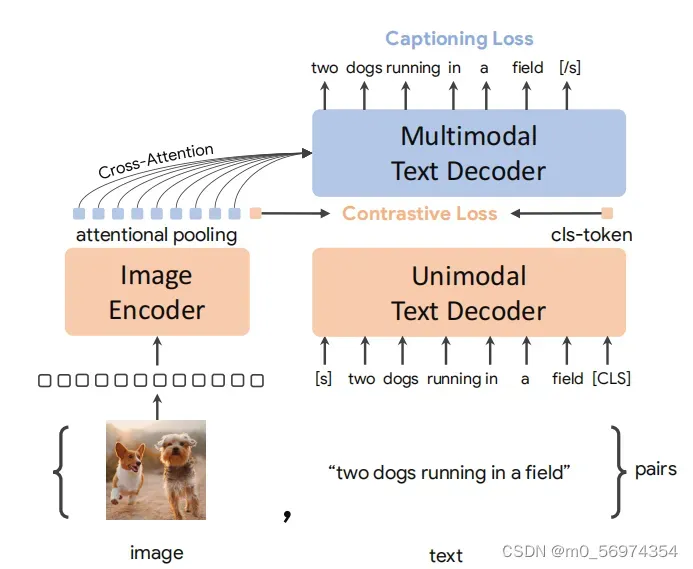
简单讲一下最近google公司提出的CoCa算法,CoCa算法实现数据集的分类任务,CoCa算法不是简单的一个仅仅针对于图片进行处理的分类网络,而是结合了文本信息,目前在ImageNet分类任务中达到了SOTA的效果,正确率目前是91%
代码的GitHub链接 CoCa-pytorch/setup.py at main · lucidrains/CoCa-pytorch · GitHub
2.思路
该算法在前向传播的过程中主要分为三部分
第一部分是对文本信息的前向传播,对于文本的前向传播采用的是attention操作,并且在代码中通过ParalleTransformerBlock类实现封装
第二部分是对图像信息的前向传播,图像的前向传播分为两个步骤,一个是图像的特征提取,一个是对于图像的交互,从而更好得到和后面的文本信息产生关联,第一步采用的是传统的VIT算法进行前向传播,在代码实现的时候直接使用torch中实现好的vit_pytorch实现,经过这一步处理之后此时图像变为了经过VIT特征提取之后的tokens。在第二步操作的时候,代码实现的时候随机初始化可训练参数img_queries,并且在和图像所得的到的token进行cross-attention操作,corss_attention在论文实现的代码中使用CrossAttention实现,其中在进行cross_attention的时候,image token作为查询的q,而随机初始化的img_queries作为k,v矩阵
第三部分是对图像和文本信息的attention操作,其中在第三部分分为两部操作,第一步是对文本的token进行深度的提取,使用的是上面提到的ParalleTransformerBlock,和第一部分的对文本的操作类似,第二部分是实现看图说话的效果,这部分操作的对象是第一部分所获得的文本的tokens,以及第二部分通过和图片交互得到的img_queries,这部分将文本的token作为查询的q,将img_queries作为k,v矩阵,从而实现cross_attention,最终获得与图片进行间接交互之后的文本的tokens
3.代码部分
接下来结合代码详细的说一下
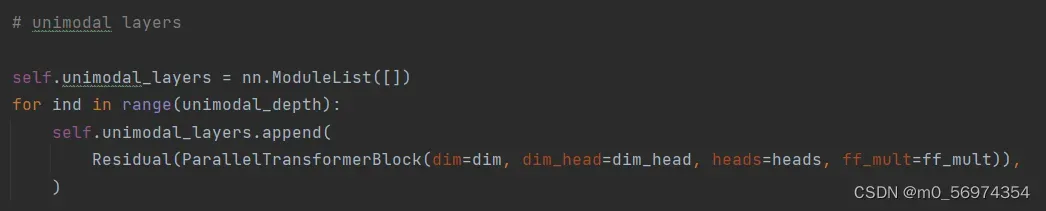
第一部分如下图是对图片处理的主要模块:首先将文本的信息进行embedding,加上位置标识和mask操作之后送入unimodal_layers的模块进行前向传播。
![]()
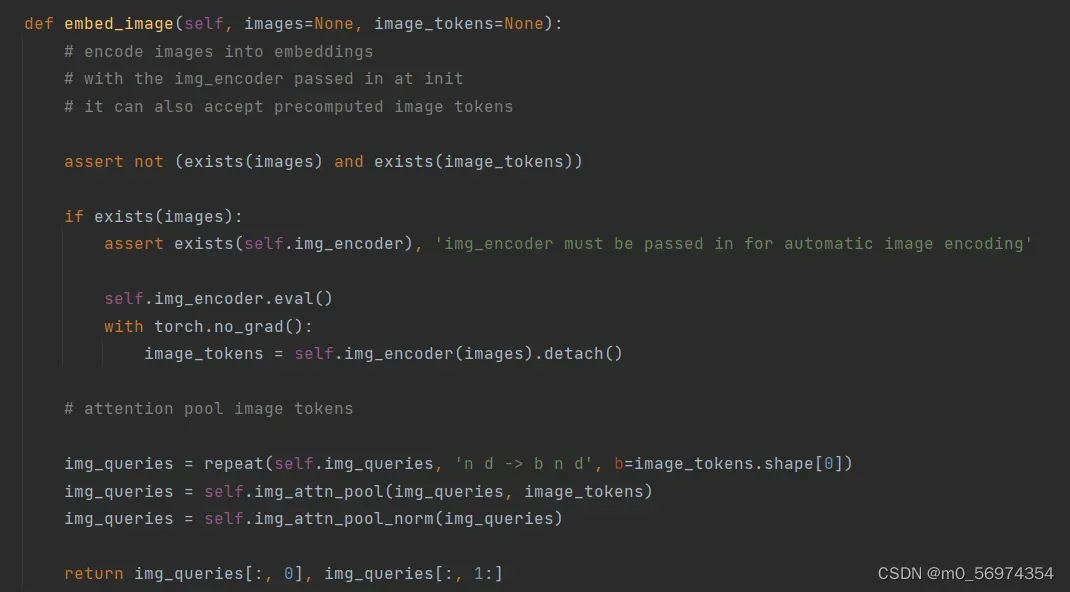
第二部分对于图像信息的处理使用的是如下的操作:首先使用的是初始化时输入的VIT对图片进行处理,随后将预先定义的img_queries与图片的token进行交互,最后返回的是img_queries的内容。
![]()
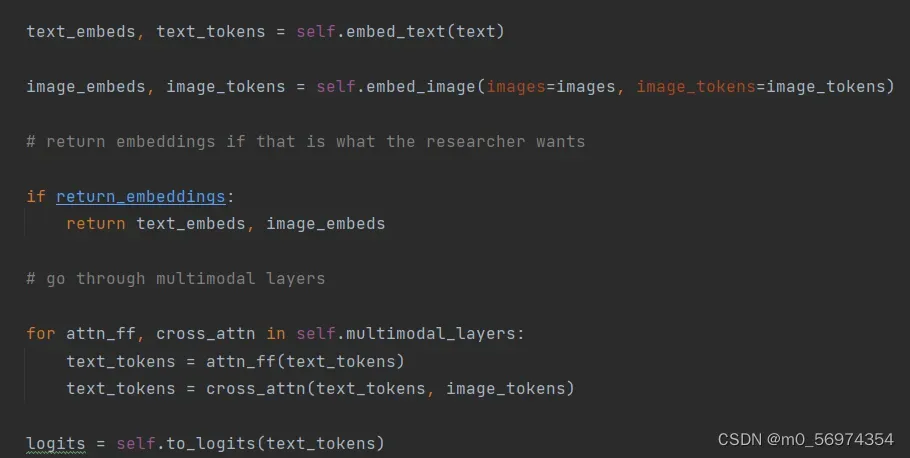
第三部分的代码如下图:其中的操作预先定义在multimodal_layers中,对图片的token进行前向传播,随后进行“图片的token”和“与图片进行交互的img_queries”进行cross_attention

别的很多细节都和Vit中的操作相似,在这里就不细说了,但是需要注意的是,ParalleTransformerBlock,cross_attention中最后的全连接层里面的激活函数采用的是SwiGLU激活函数,具体的运算过程如下图:

4.损失函数
随后说一下其中的损失函数,这里的损失函数的设计是较为巧妙的,即考虑了对比损失,又考虑了看图说话的损失。
对比的损失计算如下:在没有labels的情况下,将原来的文本的一部分信息取出来作为labels,接下来在后面优化的过程中要保证其中的信息没有发生分别,举个例子,但该例子仅作为比喻,并非具体如此——就好比two dogs running in a field在后面的特征提取的过程中可能变为了tdriaf,通过交叉熵求出tdriaf与labels的差异,这个损失函数就是保证这样的差异尽可能的小,这样就保证了语义信息的不变性。

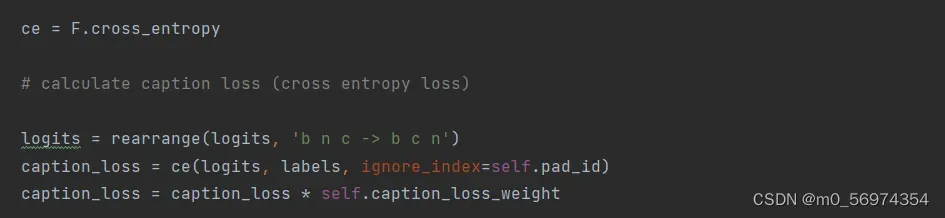
看图说话的损失函数计算如下:首先使用爱因斯坦求和运算求出text_embeds与images_embeds的点积,得到的结果用sim表示,简单的理解就是求出这两个的相似度,这里首先对sim乘以了e,所有后面的交叉熵就变为了一阶范式的运算形式,将sim与sim的转置分别与arange(batch)形成的label求一阶范式,再就和后开根,这样就叠加了图片对文本的相似性的损失和文本对图片的相似性的损失的和。

5.总结
最后,总结一下这篇论文中做的比较好的点:
1.将文本和图像的信息都考虑在分类问题中,
2.对于cross-attention在文本和图片的结合巧妙,
3.在和文本交互的图片信息并没有直接采用图片的信息,而是采用随机初始化之后和图片交互的信息拿去和文本交互,
4.损失函数的设计较为巧妙。
文章出处登录后可见!