摘要
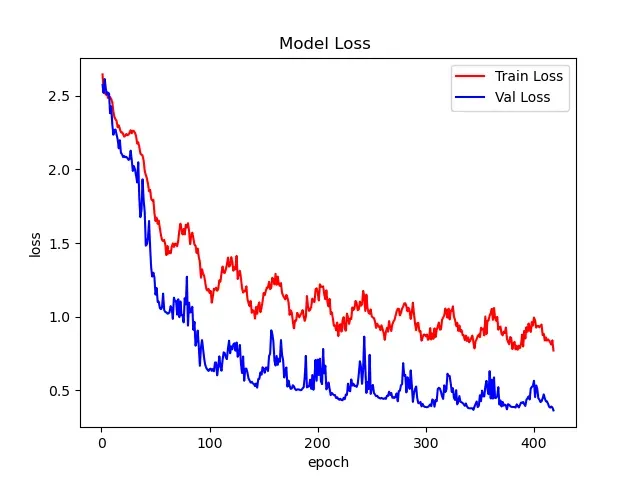
本文通过对植物幼苗分类的实际例子来感受一下ConvMAE模型的效果。模型来自官方,我自己写了train和test部分。从得分情况来看,这个模型不是很好,我训练了1000个epoch,最终得分是93.X%,而且收敛很慢。
所以就不详细介绍这个模型,带领大家从实战的角度体验一下。
这篇文章能让你学到:
- 如何使用数据增强,包括transforms的增强、CutOut、MixUp、CutMix等增强手段?
- 如何调用自定义的模型?
- 如何使用pytorch自带混合精度?
- 如何使用梯度裁剪防止梯度爆炸?
- 如何使用DP多显卡训练?
- 如何绘制loss和acc曲线?
- 如何生成val的测评报告?
- 如何编写测试脚本测试测试集?
- 如何使用余弦退火策略调整学习率?
- 如何使用AverageMeter类统计ACC和loss等自定义变量?
- 如何理解和统计ACC1和ACC5?
安装包
1、安装timm
使用pip就行,命令:
pip install timm
数据增强Cutout和Mixup
为了提高成绩我在代码中加入Cutout和Mixup这两种增强方式。实现这两种增强需要安装torchtoolbox。安装命令:
pip install torchtoolbox
Cutout实现,在transforms中。
from torchtoolbox.transform import Cutout
# 数据预处理
transform = transforms.Compose([
transforms.Resize((224, 224)),
Cutout(),
transforms.ToTensor(),
transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])
])
需要导入包:from timm.data.mixup import Mixup,
定义Mixup,和SoftTargetCrossEntropy
mixup_fn = Mixup(
mixup_alpha=0.8, cutmix_alpha=1.0, cutmix_minmax=None,
prob=0.1, switch_prob=0.5, mode='batch',
label_smoothing=0.1, num_classes=12)
criterion_train = SoftTargetCrossEntropy()
参数详解:
mixup_alpha (float): mixup alpha 值,如果 > 0,则 mixup 处于活动状态。
cutmix_alpha (float):cutmix alpha 值,如果 > 0,cutmix 处于活动状态。
cutmix_minmax (List[float]):cutmix 最小/最大图像比率,cutmix 处于活动状态,如果不是 None,则使用这个 vs alpha。
如果设置了 cutmix_minmax 则cutmix_alpha 默认为1.0
prob (float): 每批次或元素应用 mixup 或 cutmix 的概率。
switch_prob (float): 当两者都处于活动状态时切换cutmix 和mixup 的概率 。
mode (str): 如何应用 mixup/cutmix 参数(每个’batch’,‘pair’(元素对),‘elem’(元素)。
correct_lam (bool): 当 cutmix bbox 被图像边框剪裁时应用。 lambda 校正
label_smoothing (float):将标签平滑应用于混合目标张量。
num_classes (int): 目标的类数。
项目结构
ConvMAE_demo
├─data
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
├─models
│ ├─__init__.py
│ ├─models_convvit.py
│ └─vision_transformer.py
├─checkpoint.pth
├─mean_std.py
├─makedata.py
├─train.py
└─test.py
mean_std.py:计算mean和std的值。
makedata.py:生成数据集。
models_convvit.py和vision_transformer:来自官方的pytorch版本的代码。
checkpoint.pth:预训练权重。作者把预训练权重放到谷歌网盘上,不方便下载。我把它传到了CSDN上。
下载链接:https://download.csdn.net/download/hhhhhhhhhhwwwwwwwwww/85467960?spm=1001.2014.3001.5503
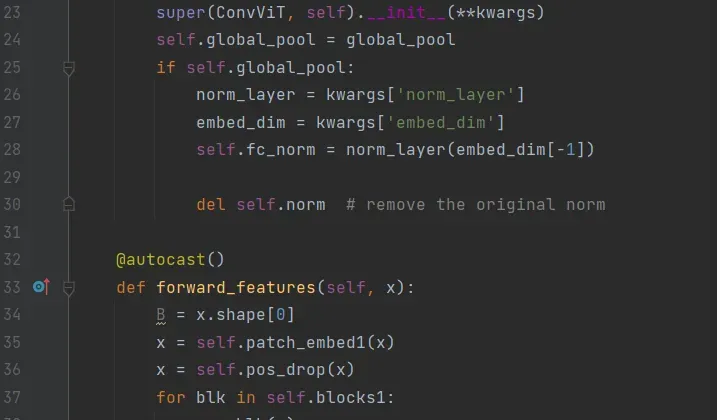
为了能在DP方式中使用混合精度,还需要在模型的forward函数前增加@autocast().
计算mean和std
为了使模型更加快速的收敛,我们需要计算出mean和std的值,新建mean_std.py,插入代码:
from torchvision.datasets import ImageFolder
import torch
from torchvision import transforms
def get_mean_and_std(train_data):
train_loader = torch.utils.data.DataLoader(
train_data, batch_size=1, shuffle=False, num_workers=0,
pin_memory=True)
mean = torch.zeros(3)
std = torch.zeros(3)
for X, _ in train_loader:
for d in range(3):
mean[d] += X[:, d, :, :].mean()
std[d] += X[:, d, :, :].std()
mean.div_(len(train_data))
std.div_(len(train_data))
return list(mean.numpy()), list(std.numpy())
if __name__ == '__main__':
train_dataset = ImageFolder(root=r'data1', transform=transforms.ToTensor())
print(get_mean_and_std(train_dataset))
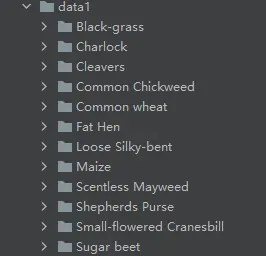
数据集结构:
运行结果:
([0.3281186, 0.28937867, 0.20702125], [0.09407319, 0.09732835, 0.106712654])
把这个结果记录下来,后面要用!
生成数据集
我们整理还的图像分类的数据集结构是这样的
data
├─Black-grass
├─Charlock
├─Cleavers
├─Common Chickweed
├─Common wheat
├─Fat Hen
├─Loose Silky-bent
├─Maize
├─Scentless Mayweed
├─Shepherds Purse
├─Small-flowered Cranesbill
└─Sugar beet
pytorch和keras默认加载方式是ImageNet数据集格式,格式是
├─data
│ ├─val
│ │ ├─Black-grass
│ │ ├─Charlock
│ │ ├─Cleavers
│ │ ├─Common Chickweed
│ │ ├─Common wheat
│ │ ├─Fat Hen
│ │ ├─Loose Silky-bent
│ │ ├─Maize
│ │ ├─Scentless Mayweed
│ │ ├─Shepherds Purse
│ │ ├─Small-flowered Cranesbill
│ │ └─Sugar beet
│ └─train
│ ├─Black-grass
│ ├─Charlock
│ ├─Cleavers
│ ├─Common Chickweed
│ ├─Common wheat
│ ├─Fat Hen
│ ├─Loose Silky-bent
│ ├─Maize
│ ├─Scentless Mayweed
│ ├─Shepherds Purse
│ ├─Small-flowered Cranesbill
│ └─Sugar beet
新增格式转化脚本makedata.py,插入代码:
import glob
import os
import shutil
image_list=glob.glob('data1/*/*.png')
print(image_list)
file_dir='data'
if os.path.exists(file_dir):
print('true')
#os.rmdir(file_dir)
shutil.rmtree(file_dir)#删除再建立
os.makedirs(file_dir)
else:
os.makedirs(file_dir)
from sklearn.model_selection import train_test_split
trainval_files, val_files = train_test_split(image_list, test_size=0.3, random_state=42)
train_dir='train'
val_dir='val'
train_root=os.path.join(file_dir,train_dir)
val_root=os.path.join(file_dir,val_dir)
for file in trainval_files:
file_class=file.replace("\\","/").split('/')[-2]
file_name=file.replace("\\","/").split('/')[-1]
file_class=os.path.join(train_root,file_class)
if not os.path.isdir(file_class):
os.makedirs(file_class)
shutil.copy(file, file_class + '/' + file_name)
for file in val_files:
file_class=file.replace("\\","/").split('/')[-2]
file_name=file.replace("\\","/").split('/')[-1]
file_class=os.path.join(val_root,file_class)
if not os.path.isdir(file_class):
os.makedirs(file_class)
shutil.copy(file, file_class + '/' + file_name)
完成上面的内容就可以开启训练和测试了,详见下面的链接:
文章出处登录后可见!