前言
本文简要介绍使用 HALCON 进行 OCR。 介绍从训练文件生成到训练再到阅读的所有重要步骤。
提示:以下是本篇文章正文内容,下面案例可供参考
一、生成训练文件
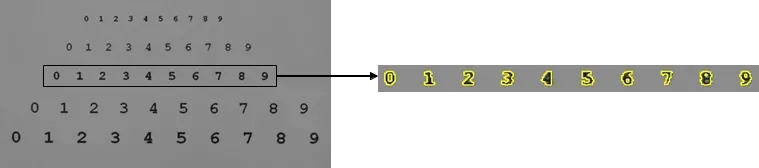
图中显示了一个训练图像,其中第四行中的字符用作训练样本。 对于这个示例图像,分割非常简单,因为字符明显比背景暗。 因此,可以使用阈值。
用于训练的字符行数由变量 TrainingLine 指定。 要选择这一行,首先使用操作符 closing_rectangle1 将字符水平组合成行。 然后这些线通过connected转换为它们的连接组件。 在所有行中,使用 select_obj 选择相关行。 通通过使用 intersection 与原始分割和选定的行作为输入,返回用于训练的字符。 这些是使用 sort_region 从左到右排序的。
TrainingLine := 3
threshold (Image, Region, 0, 125)
closing_rectangle1 (Region, RegionClosing, 70, 10)
connection (RegionClosing, Lines)
select_obj (Lines, Training, TrainingLine)
intersection (Training, Region, TrainingChars)
connection (TrainingChars, ConnectedRegions)
sort_region (ConnectedRegions, SortedRegions, 'first_point', 'true', 'column')
现在,字符可以存储在训练文件中。 作为准备步骤,删除可能存在的较旧的培训文件。 在所有字符的循环中,选择单个字符。 变量 Chars 包含作为字符串元组的字符名称。 使用操作符 append_ocr_trainf 将所选区域连同灰度值和相应的名称一起添加到训练文件中。
Chars := ['0','1','2','3','4','5','6','7','8','9']
TrainFile := 'numbers.trf'
dev_set_check ('~give_error')
delete_file (TrainFile)
dev_set_check ('give_error')
for i := 1 to 10 by 1
select_obj (SortedRegions, TrainSingle, i)
append_ocr_trainf (TrainSingle, Image, Chars[i - 1], TrainFile)
endfor
1.1 完整代码
* gen_training_file.hdev: create a training file for OCR
*
dev_update_off ()
dev_close_window ()
* ****
* step: acquire image
* ****
read_image (Image, 'numbers_scale')
get_image_pointer1 (Image, Pointer, Type, Width, Height)
dev_open_window (0, 0, Width, Height, 'black', WindowID)
dev_set_part (0, 0, Height - 1, Width - 1)
dev_set_line_width (2)
dev_set_color ('yellow')
dev_set_draw ('margin')
dev_display (Image)
disp_continue_message (WindowID, 'black', 'true')
stop ()
* ****
* step: specify character names
* ****
Chars := ['0','1','2','3','4','5','6','7','8','9']
* index of the line used for the training (1..5)
TrainingLine := 3
disp_continue_message (WindowID, 'black', 'true')
stop ()
* ****
* step: segment image
* ****
threshold (Image, Region, 0, 125)
closing_rectangle1 (Region, RegionClosing, 70, 10)
connection (RegionClosing, Lines)
select_obj (Lines, Training, TrainingLine)
intersection (Training, Region, TrainingChars)
connection (TrainingChars, ConnectedRegions)
sort_region (ConnectedRegions, SortedRegions, 'first_point', 'true', 'column')
* visualize result
dev_display (SortedRegions)
dev_display (Training)
smallest_rectangle1 (TrainingChars, Row1, Column1, Row2, Column2)
RowROI1 := Row1 - 5
ColROI1 := Column1 - 5
RowROI2 := Row2 + 5
ColROI2 := Column2 + 5
ZoomFactor := 2
dev_open_window (20, 0, (ColROI2 - ColROI1) * ZoomFactor, (RowROI2 - RowROI1) * ZoomFactor, 'black', WindowHandleZoom)
dev_set_part (round(RowROI1), round(ColROI1), round(RowROI2), round(ColROI2))
dev_display (Image)
dev_display (SortedRegions)
disp_continue_message (WindowID, 'black', 'true')
stop ()
* ****
* step: write regions into training file
* ****
TrainFile := 'numbers.trf'
* clear file first
dev_set_check ('~give_error')
delete_file (TrainFile)
dev_set_check ('give_error')
for i := 1 to 10 by 1
select_obj (SortedRegions, TrainSingle, i)
append_ocr_trainf (TrainSingle, Image, Chars[i - 1], TrainFile)
endfor
disp_continue_message (WindowID, 'black', 'true')
stop ()
dev_close_window ()
1.2 结果
二、创建和训练 OCR 分类器
准备好训练文件后,OCR 分类器的创建和训练就非常简单了。 首先,确定训练文件和最终字体文件的名称。 通常,使用具有不同扩展名的相同基础。 我们建议使用“.trf”作为训练文件。 对于字体文件,即 OCR 分类器,我们建议使用“.obc”作为框分类器(不再推荐),“.omc”作为神经网络分类器,“.osc”作为基于支持的分类器 向量机。 如果在读取过程中没有指定扩展名,那么对于框或神经网络分类,它也会搜索带有扩展名“.fnt”的文件,这在早期的 HALCON 版本中这两种分类器都很常见。
要创建 OCR 分类器,需要确定一些参数。 最重要的是所有可能的字符名称的列表。 使用操作符 read_ocr_trainf_names 可以轻松地从训练文件中提取此列表。
TrainFile := 'numbers.trf'
read_ocr_trainf_names (TrainFile, CharacterNames, CharacterCount)
另一个重要参数是神经网络隐藏层的节点数。 在这种情况下,它被设置为 20。根据经验,这个数字应该与不同符号的数量相同。 除了这两个参数,这里只对 create_ocr_class_mlp 使用默认值。 使用 trainf_ocr_class_mlp 应用训练本身。 我们建议也在这里简单地使用默认值。
NumHidden := 20
create_ocr_class_mlp (8, 10, 'constant', 'default', CharacterNames, NumHidden, 'none', 1, 42, OCRHandle)
trainf_ocr_class_mlp (OCRHandle, TrainFile, 200, 1, 0.01, Error, ErrorLog)
最后,分类器存储到磁盘并释放内存。
FontFile := 'numbers.omc'
write_ocr_class_mlp (OCRHandle, FontFile)
clear_ocr_class_mlp (OCRHandle)
请注意,对于更复杂的 OCR 分类器,即,特别是,如果训练数据还包含非常嘈杂和变形的样本,建议创建一个基于 MLP 的 OCR 分类器,对内部权重进行正则化(参见 set_regularization_params_ocr_class_mlp)。 这增强了分类器的泛化能力,并防止了对单个退化训练样本的过度拟合。
如果为自动文本阅读器创建了 OCR 分类器,建议额外定义一个带有 set_rejection_params_ocr_class_mlp 的拒绝类,这有助于区分字符和背景杂乱。
2.1 完整代码
* simple_training.hdev: train an OCR classifier (MLP) based on the training file created by gen_training_file.hdev
*
dev_update_window ('off')
* ****
* step: read training data
* ****
TrainFile := 'numbers.trf'
read_ocr_trainf_names (TrainFile, CharacterNames, CharacterCount)
stop ()
* ****
* step: create and train classifier
* ****
NumHidden := 20
create_ocr_class_mlp (8, 10, 'constant', 'default', CharacterNames, NumHidden, 'none', 1, 42, OCRHandle)
trainf_ocr_class_mlp (OCRHandle, TrainFile, 200, 1, 0.01, Error, ErrorLog)
stop ()
* ****
* step: save classifier
* ****
FontFile := 'numbers.omc'
write_ocr_class_mlp (OCRHandle, FontFile)
* free memory
clear_ocr_class_mlp (OCRHandle)
2.1 结果
![]()
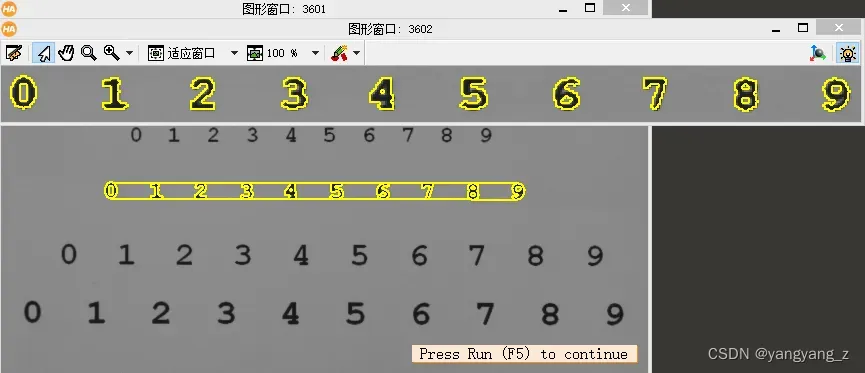
三、读取数字
此示例程序演示了如何使用自动文本阅读器(参见上述创建和训练OCR分类器)使用预训练的 OCR 字体阅读简单文本。 它读取图 17.2 中描绘的图像中的数字。 无需使用运算符阈值和连接手动分割数字,然后对分割区域进行分类,而是使用自动文本阅读器一步读取数字,无需任何参数调整,只需使用运算符 find_text .
create_text_model_reader ('auto', 'Document_0-9_NoRej', TextModel)
find_text (Image, TextModel, TextResultID)
get_text_result (TextResultID, 'class', Classes)
3.1 完整案例
* This example program demonstrates how to read text with the
* Automatic Text Reader using a pretrained OCR font
*
dev_update_off ()
*
* Acquire the image
read_image (Image, 'numbers_scale')
get_image_pointer1 (Image, Pointer, Type, Width, Height)
dev_close_window ()
dev_open_window (0, 0, Width, Height, 'black', WindowID)
dev_set_part (0, 0, Height - 1, Width - 1)
dev_set_line_width (2)
dev_set_color ('yellow')
dev_set_draw ('margin')
dev_display (Image)
set_display_font (WindowID, 12, 'mono', 'true', 'false')
stop ()
*
* Create the Automatic Text Reader with a pretrained OCR font
create_text_model_reader ('auto', 'Document_0-9_NoRej', TextModel)
*
* Segment the image and read the text
find_text (Image, TextModel, TextResultID)
*
* Display the segmentation results
get_text_object (Characters, TextResultID, 'all_lines')
dev_display (Image)
dev_display (Characters)
stop ()
* Display the reading results
get_text_result (TextResultID, 'class', Classes)
count_obj (Characters, Number)
for Index := 1 to Number by 1
dev_set_color ('yellow')
select_obj (Characters, SingleChar, Index)
dev_set_color ('white')
Class := Classes[Index - 1]
smallest_rectangle1 (SingleChar, Row1, Column1, Row2, Column2)
set_tposition (WindowID, Row1 - 17, (Column2 + Column1) * 0.5 - 5)
write_string (WindowID, Class[0])
endfor
stop ()
*
* Free memory
clear_text_result (TextResultID)
clear_text_model (TextModel)
3.2 结果
文章出处登录后可见!