0 引入
0.1 题目
0.2 背景
使用多实例学习 (Multi-instance learning, MIL) 的弱监督视频异常检测 (Viswo anomaly detection, VAD) 通常基于异常片段的异常分数高于正常片段的异常分数这一事实。在模型的训练伊始,由于模型的精度不足很容易选择出错误的异常片段。
0.3 方法
1)为了减少选择错误的概率,提出了一种多序列学习 (Multi-sequence learning, MSL) 方法和一种基于的MSL排序损失,它使用由多个片段组成的序列作为优化单元;
2)设计了一个基于变换的MSL网络来同时学习视频级别异常概率和片段级别异常得分;
3)在推理阶段,使用视频异常概率来抑制片段级别异常得分的波动;
4)由于VAD需要预测片段级别异常分数,通过逐渐减少所选序列的长度,提出了一种自训练策略来逐步细化异常分数。
0.4 Bib
@inproceedings{Li:2022:self,
author = {Shuo Li and Fang Liu and Li Cheng Jiao},
title = {Self-training multi-sequence learning with Transformer for weakly supervised video anomaly detection},
journal = {{AAAI} Conference on Artificial Intelligence},
year = {2022}
}
1 算法
1.1 符号与问题声明
在弱监督VAD领域,视频的标注信息仅于视频级别给出。即当视频包含异常信息时标记为1 (正),反之为0 (负)。给定一个包含个片段的视频
,其视频级别标签为
。基于MIL的方法将
看作是一个包,
则看作是一个实例。因此,一个正视频看作是一个正包
,一个负视频看作是一个负包
。
VAD的目标是习得一个将片段映射到区间的函数
。基于MIL的VAD假设异常片段的异常得分高于正常片段的异常得分。Sultani等人将VAD看作是一个异常得分问题,并提出了一个排序目标函数和MIL排序损失:
为了使得正实例与负实例之间的差距尽可能大,Sultani提供了一个合页损失函数:
在优化的初始,
需要一定的异常预测能力,否则它将选择一个正常实例作为异常实例。这种错误情况下,误差将会被延申到整个训练过程。此外,异常部分通常是多个连续的片段,但基于MIL的方法不考虑这个先验。
1.2 MSL
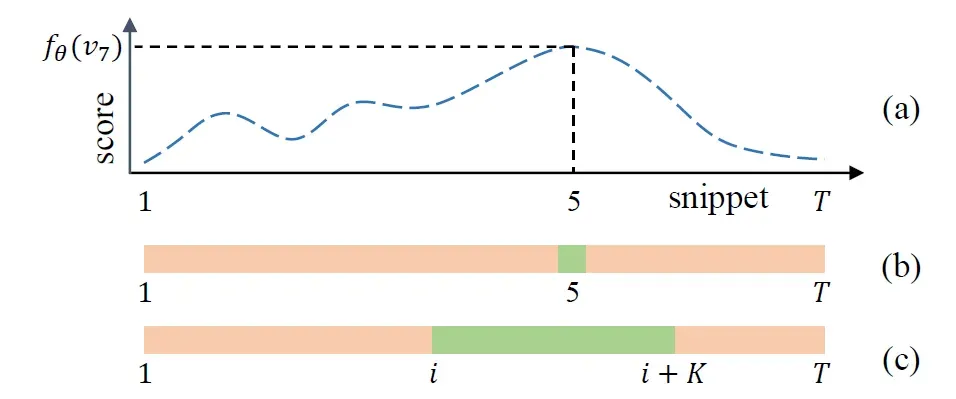
为了缓解以上MIL方法的不足,我们提出了一个新颖的MSL方法。如图2所示,给定包含个片段的视频
,首先通过映射函数
预测得到异常得分曲线。假设第5个片段有最大异常得分
。在基于MIL的方法中,第5个片段将被选择用于优化网络。在所提出的MSL中,我们提供了一个序列选择方法,它将选择包含
个序列的连续片段。具体地,我们计算
个连续片段的所有可能序列的异常分数的平均值:
其中
表示从第
个片段开始的异常得分平均值。然后,具有最大异常得分的序列将被选择,即
。
基于以上序列选择方法,可以得到MSL排序优化函数:
其中
和
分别表示异常视频和正常视频的异常得分。为了保证正负实例之间较大的间距,与公式3类似,我们的MSL合页排序损失被定义为:
MIL可以看作是MSL的一种特殊情况,当
时两者等价;当
时,MSL任务异常视频中的每一个片段都是异常的。
1.3 基于变换的MSL网络
1.3.1 卷积变换编码器
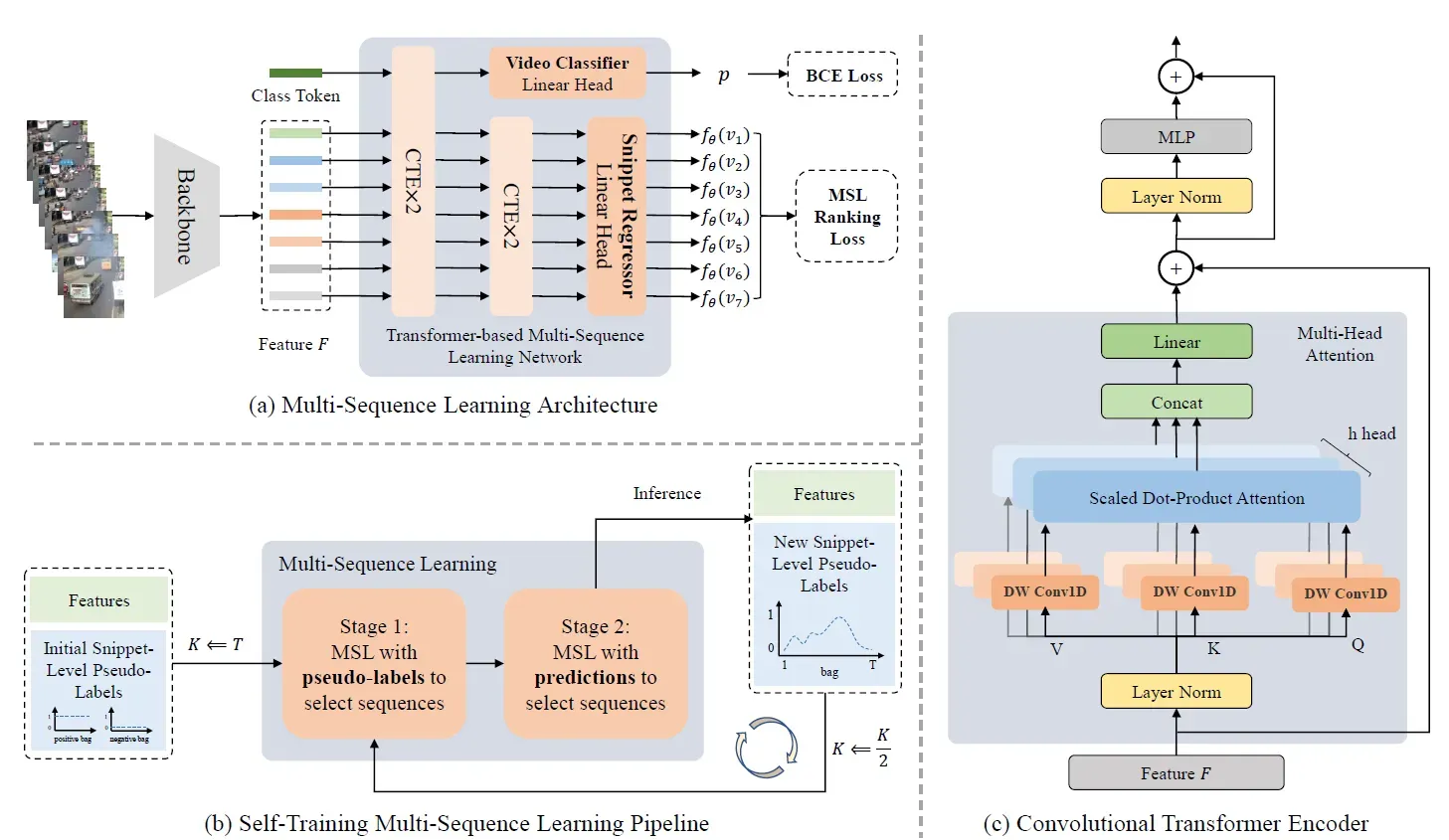
变换器 (Transformer) 使用序列数据作为输入从而对长期关联建模,已在多个领域成果显著。视频的片段之间的表示非常重要。然而,变换器并不擅长学习相邻片段的局部表示。受此启发,如图1(c )所示,我们将原始变换器中的线性投影替换为DW Conv1D投影。 新的Transformer被命名为卷积变换编码器 (Convolutional transformer encoder, CTE)。
1.3.2 MSL变换网络
如图1(a)所示,所设计架构包含一个骨架和MSLNet。任意的行为识别方法都可以作为骨架,如C3D、I3D,以及VideoSwin。本文的骨架使用行为识别数据集上的预训练权重,每个视频将获取一个特征。
MSLNet包含一个视频分类器和一个片段回归器。视频分类器包含两个CTE层和一个用于预测视频是否包含异常的线性头:
其中
是线性头的参数、
是视频异常预测概率,以及class token是用于预测汇聚于CTE上特征的概率。由于VAD是一个二分类问题,因此sigmoid函数
被选用。
片段回归器用于预测每一个片段的异常得分:
其中
是线性头的参数、
是第
个片段的特征。由于片段异常得分预测属于回归问题,因此同样选用
。
视频分类和片段回归可以看作是一个多任务问题,因此总的优化目标为:
为了降低片段回归器的异常得分预测波动,我们提出了一个干预阶段的异常得分纠正机制:
1.4 自训练MSL
如图1(b)所示,自训练机制用于训练过程的精细化。MSLNet的训练过程包含两个阶段,这之前包含初始化过程:首先获取训练视频的伪标签,片段级别的伪标签则通过视频的真实标签
获取,即片段标签与视频真实标签等同。
在训练的初试阶段,的异常得分获取能力是不足的,
将很可能选择到错误的序列。因此,MSL的两个阶段为:
1)阶段1—临时阶段:通过将公式4中的预测异常得分使用片段的伪标签
替换,来选择具有最大伪标签平均值的序列。基于该序列计算
和
,并通过合页排序损失优化MSLNet:
在
轮训练后,MSLNet将具备初步的异常得分预测能力。
2)阶段2:这一阶段使用公式5和6来优化,在轮训练,可以获取新的片段级伪标签
。通过将序列长度减半并重复以上两个步骤,预测得分的预测能力将逐步精进。自训练MSL的伪代码如算法1。

2 实验
2.1 数据集和评价指标
1)ShanghaiTech是一个包含437个校园监控130个校园事件13个场景的中等规模视频数据集。然而,其所有的训练数据是正常的。在弱监督设置下,使用238个训练视频和199个测试视频的划分。
2)UCF-Crime是一个大规模数据集,包含1900个未经修剪的真实街道和室内监控视频,包含13类异常事件,总持续时间为128小时。训练集包含1610个带有视频级标签的视频,测试集包含290个带有帧级标签的视频。
3)XD-Violence是一个大规模数据集,包含4754个未修剪的视频,总时长为217小时,并从多个来源收集,例如电影、体育、监控和闭路电视。 训练集包含3954个带有视频级标签的视频,测试集包含800个带有帧级标签的视频。
前两个数据集的评价指标使用AUC和ROC,后一个数据集使用平均精度 (AP)。
2.2 实现细节
1)从Sports-1M上的预训练C3D的fc6层中提取4096D特征;
2)从预训练I3D的混合5c层中提取1024D特征;
3)在Kinetics-400以及来自Kinetics-400上预训练VideoSwin的Stage4层提取1024D特征;
4)、
、
;
5)优化器使用SGD、学习率设置为0.001、权重衰减设置为0.0005、批次大小设置为64;
6)、
;
7)每个mini-batch由32个随机选择的正常和异常视频组成。在异常视频中,随机选择前 10%的片段之一作为异常片段;
8)在CTE中,headers的数量设置为12,并使用内核大小为3的DW Conv1D。
文章出处登录后可见!