定义
语义分割 (Semantic Segmentation):从像素水平(pixel-level)上,理解、识别图片的内容。
根据语义信息对图像中的像素进行分割。
输入:图片
输出:同尺寸的分割标记(像素水平)[每个像素会被识别为一个类别 category]评价指标
像素准确率(Pixel Accuracy PA) or (global acc)
类别像素准确率(Class Pixel Accuracy CPA)
类别平均像素准确率(Mean Accuracy or Mean Pixel Accuracy MPA)
平均交并比(Mean Intersection over Union MIoU)
若想理解以上指标,必须知道什么叫做混淆矩阵(Confusion Matrix),因为这些指标都是以混淆矩阵为基础。
混淆矩阵:分别统计分类模型归错类,归对类的观测值个数;之后,将结果呈现在一个表格中,这个表格便为混淆矩阵。
首先,我们定义混淆矩阵的四个基础指标:
- 真实值为Positive,模型预测也是Positive的数量(True Positive = TP)
- 真实值为Positive,模型预测为Negative的数量(False Negative = FN)
- 真实值为Negative,模型预测为Positive的数量(False Positive = FP)
- 真实值为Negative,模型预测也是Negative的数量(True Negative = TN)
注意表格中预测值和真实值的位置!
| 预测\真实 | Positive | Negative |
|---|---|---|
| Positive | TP | FP |
| Negative | FN | TN |
则指标有
准确率(Accuracy)
Accuracy = (TP+TN)/(TP+TN+FP+FN)
对角线计算,预测结果中正确的数量占总预测数量的比例 (对角线元素值的和/总元素值的和)
精准率(Precision)
Precision = TP/(TP+FP) or TN/(TN+FN)
预测结果中某类别预测正确的概率
召回率(Recall)
Recall = TP/(TP+FN) or TN/(TN+FP)
标签中某类别被预测正确的概率
举个栗子
| 预测\真实 | 猫 | 不是猫 |
|---|---|---|
| 猫 | 10 | 3 |
| 不是猫 | 8 | 45 |
Accuracy = (TP+TN)/(TP+TN+FP+FN) = 55/66
Precision(猫) = TP/(TP+FP) = 10/13
Recall(猫) = TP/(TP+FN) = 10/18
将其思维带入语义分割评价指标中
语义分割 将 图片中的像素点 (可看作 混淆矩阵 ) 分类
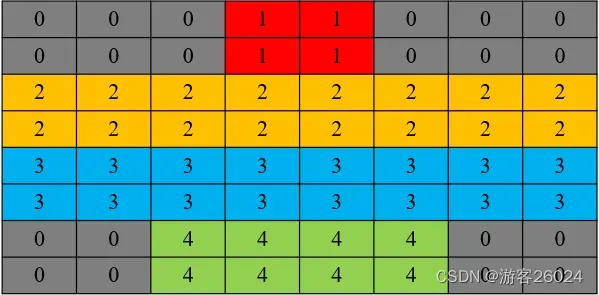
下图的表格代表一张8*8的图像,0-4代表像素值,比如横坐标为1,纵坐标也为1的像素值为0
图像的真实标签
图像的预测标签
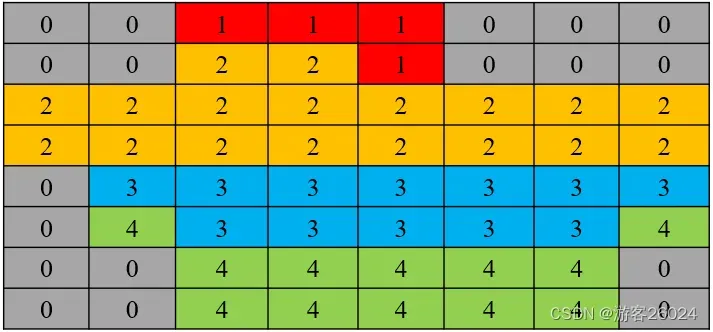
将其翻译为 混淆矩阵
| 预测\真实 | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| 0 | 16 | 0 | 0 | 2 | 0 |
| 1 | 1 | 3 | 0 | 0 | 0 |
| 2 | 1 | 1 | 16 | 0 | 0 |
| 3 | 0 | 0 | 0 | 12 | 0 |
| 4 | 2 | 0 | 0 | 2 | 8 |
像素准确率
(Pixel Accuracy PA or Global Acc)
可对应 混淆矩阵中的 准确率 Accuracy
对角线元素之和/矩阵所有元素之和
带入上面的值:
类别像素准确率
(Class Pixel Accuracy CPA)
可对应 混淆矩阵中的 精准率 Precision
在类别 i 的预测值中,真实属于i类的像素准确率,换言之 预测正确的值占预测总值的比例
带入上面的值:
类别平均像素准确率
(Mean Accuracy or Mean Pixel Accuracy MPA)
分别计算每个类别被正确分类像素数量的比例 -> 将CPA累加再求平均
带入上面的值:
平均交并比
(Mean Intersection over Union MIoU)
首先计算类别IoU (CIoU)累加再求平均
带入上面的值:
参考:
文章出处登录后可见!