Qilong Wang, Banggu Wu, Pengfei Zhu, Peihua Li, Wangmeng Zuo, & Qinghua Hu (2019). ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks computer vision and pattern recognition.
本文针对SENet通道注意力中降维产生的副作用进行了分析,为了克服副作用提出了ECA高效通道注意力,增加非常少的参数且获得了很好的表现。
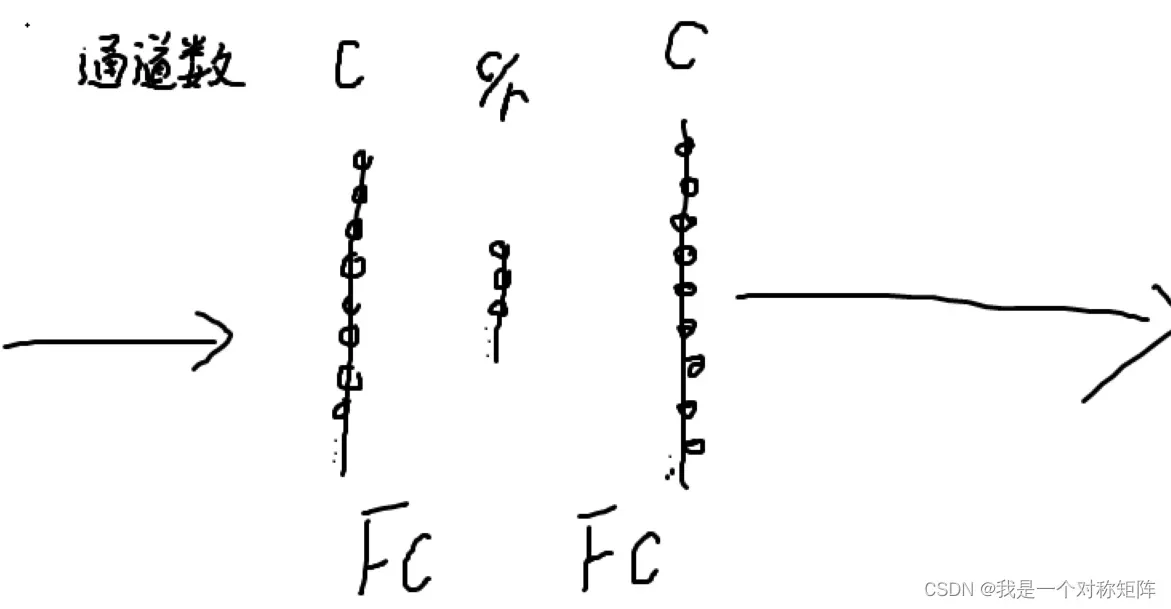
下图是SEnet中通道注意力,中间c/r就是通道降维了。
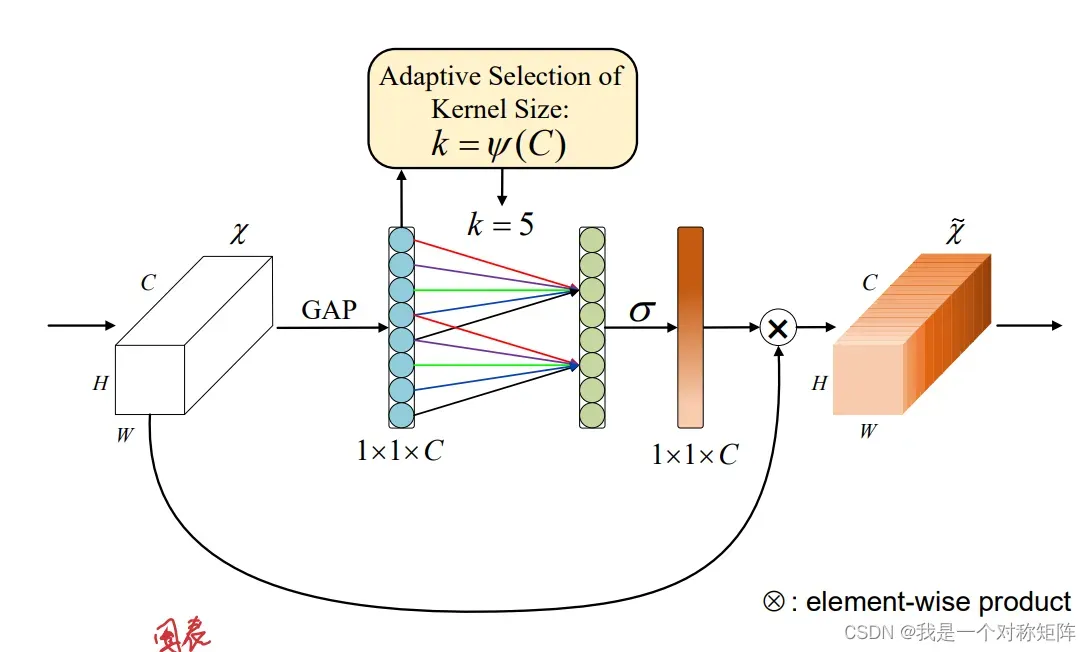
下图是ECA:
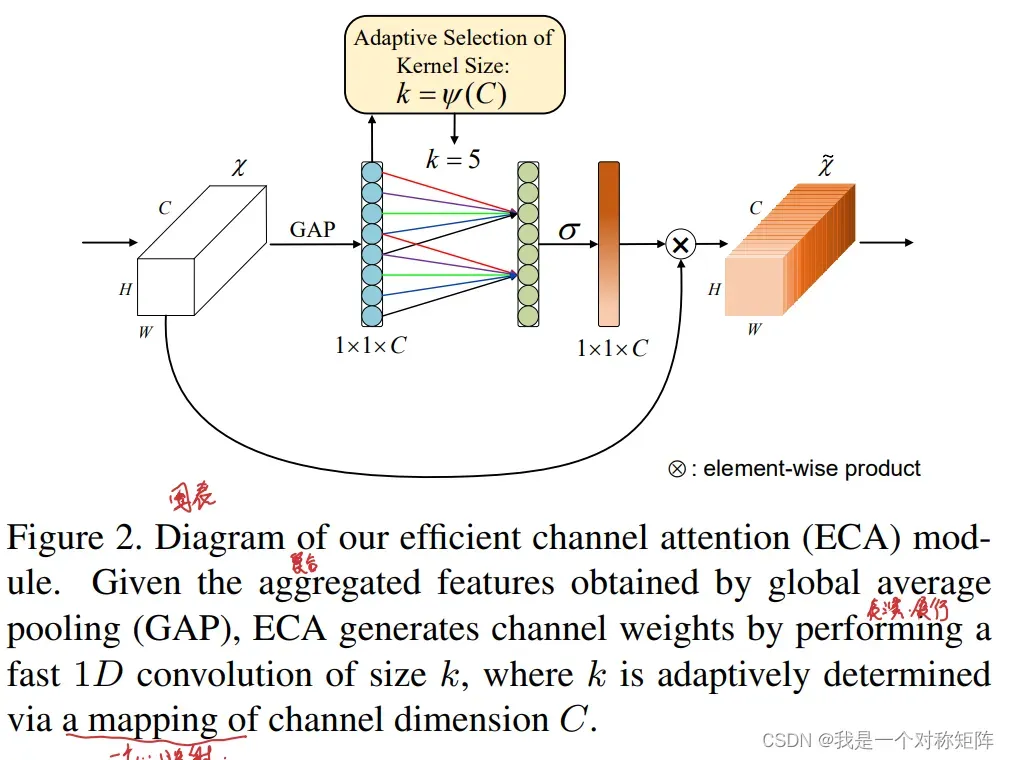
Q1、论文试图解决什么问题?
SEnet通道注意力中有降维操作,这会破坏通道间的直接交流,产生的通道权重不够好。但是如果不降维那这样的全连接会导致参数量暴涨。所以作者设计一个ECA,在不降维的情况下,控制参数量,实现高效高表现的通道注意力。
Q2、这是否是一个新的问题?
应该不是吧,SENet中也提到为了平衡效果和参数量,中间进行了c/r的降维,所以SEnet应该知道降维是有副作用,为了控制参数量只能降维。ECA另一个创新应该是使用跨K邻近通道交互,实现不降维也能控制参数量。
Q3、这篇文章要验证一个什么科学假设?
首先通过实验验证了降维的确有副作用,也通过实验验证了直接全连接(参数量为C*C)和跨K邻近通道交互(参数量为C*C/k)效果差不多,甚至跨K邻近通道交互效果还高一丢丢。
Q5、论文中提到的解决方案之关键是什么?
1)不降维;2)全连接中每个神经元与上层每个神经元都交互,ECA中每个神经元只与与它相近的K个神经元相互,实现高效。
0、Abstract
最近,通道注意力机制被证明在提高CNN的表现上有着非常大的潜力。越来越多的精密的注意力模块被提出来去实现更好的模型效果,但是他们都不可避免的增加了模型的复杂度。
为了克服性能和复杂度之间的平衡,本文提出了一个高效注意力慕课,它仅涉及很少的参数,却带来了明显的性能增益。
通过剖析SENet中的注意力模块,我们使用实验经验性地证明避免维度减少对于学习通道注意力是非常重要的,同时也证明了合适的跨通道交互能够在显著降低模型复杂度时保持性能。因此我们提出了一个不降维的局部跨通道交互策略,它能够通过使用1D卷积高效实现,对于跨通道跨多长(与多少的上层神经元交互)我们设计了一种自适应选择的方法。
这个ECA模块兼顾高效和有效,与ResNet50相比:
| ECA Module | ResNet50 | |
|---|---|---|
| 参数量 | 80 | 24.37M |
| 计算量 | 4.7e-4 | 3.86GFLOPs |
| 在Top1精度(没说什么任务)上提高超过2%(搭配ResNet50). | – | – |
同时在图像分类、物体检测、实例分割等任务上使用ResNets和MobileNetV2进行了广泛的验证,结果证明了ECA的有效性。
1、Introduction
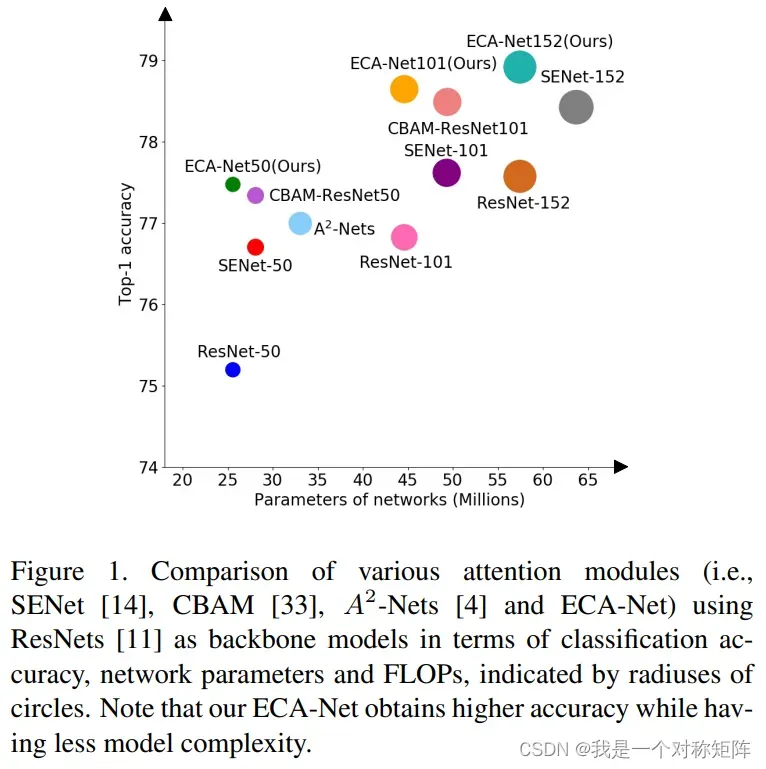
上图是各种注意力模块和ResNets结合的参数量和精度比较,可以看出ECA-Net50和ResNet-50在参数量上几乎一致,但是精度却提高很多。(注意的是虽然ECA-Net152精度最高,但是backbone的ResNet-152本身就比较高,提升幅度没有ResNet-50高,但是不影响ECA的有效性结论)
很多注意力模块都是模型复杂度换精度,本文抛出一个灵魂问题:有没有一种用更高效的方法学习有效的通道注意力?
为了回答这个问题,我们首先回看SENet中的通道注意力模块,给定一个输入features=[h,c,w],SEBlock首先对每个通道进行进行全局均值池化,得到[1,1,c],然后使用两个FC层后跟Sigmoid去生成通道权重值。这两个FC曾被设计去捕获非线性跨通道交互,使用了通道降维去控制模型复杂度(参数量为,如果不降维则没有中间那个,则参数量为
,通常
都是比较大的,故降维后参数量确实要少)。
虽然降维这个策略在随后的通道注意力模块中被广泛使用,但是我们的经验性实验证明降维操作会对通道注意力的权重预测带来副作用,所以降维是一种在捕获跨通道依赖关系时的低效且不必要的操作。
之所以叫类全连接层,实际上这里的跨通道交互只考虑每个通道和它的k个邻近上级神经元,这个局部跨通道交互在后面的实验被证实是有效且高效的。
注意,这里的局部跨通道交互其实通过设定卷积尺寸为k的1D卷积就可以实现。
当然对于k取多少,如果手动调确实够呛,作者们通过实验提出一种自适应的方法,后面会将其实就是通道数和k值符合一个函数关系,知道C就可以计算出k的最佳值。

贡献如下:
1)我们分析SEBlock,并通过实验证明避免通道降维和适当的跨通道交对于高效学习通道注意力是非常重要的。
2)基于以上分析,我们提出了一种极度轻量化的通道注意力模块ECA,只增加一丢丢参数却带来明显的性能提升
3)在ImageNet1K和MSCOCO上证明ECA以更低的模型复杂度实现了有竞争力的表现。(意思是可以和SOTA们打一架?)
2、Related Work
略
3、Proposed Method
首先我们分析了SENet,然后用实验验证和分析证明通道降维确实有害和跨通道交互确实有用。这也是我们提出ECA的动机。然后我们还提出了一种自适应确定k值的方法,最后我们展示ECA用于CNNs的效果。
3.1、回看SEBlock中的通道注意力
还是这张图,中间这个降维操作能够降低模型的复杂度,但是它破坏了通道之间的直接交流和通道权重。这种操作先将通道特征投射到低维空间,然后再映射回高维空间,这就让通道间和权重的交流变成间接的了。
(信息被压缩再解压?)
3.2.1 避免降维
为了验证3.1降维确实是有害的,接下来设计了一系列实验:
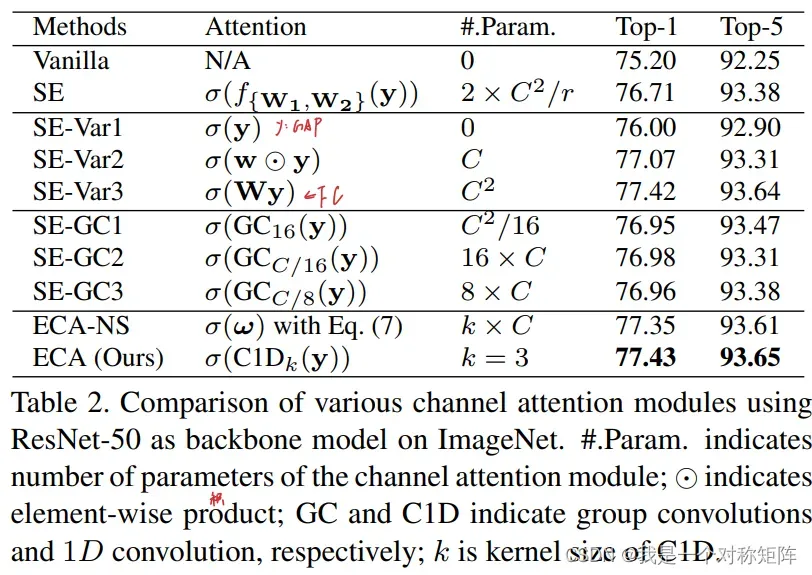
y=GAP(input features),即y是经过GAP后没有任何的值,shape=[1,1,C]
- SE-Var1是没有任何参数的,但是仍比Vanilla(原始网络,不加通道注意力)高,证明通道注意力确实是有效的。
- SE-Var2独立地为每个通道学习到一个权重参数(应该是这个权重不是由通道特征计算得来的,而是一个可学习的参数),其效果稍微超过SEBlock(参数量还低),证明了更好的权重需要和通道直接交流。
- SE-Var3使用的是单个FC层,如下图所示,在SEBlock中使用了两个FC层,中间涉及了降维,SE-Var3中仅使用一个不降维的FC层,其效果比SE好。
以上都清楚了说明了避免降维对于学习到有效的通道注意力是非常有帮助的。
3.2.2 局部跨通道交互
实际上这部分就是以矩阵形式分析了局部跨通道交互。略。
3.2.3 局部跨通道交互的覆盖范围(即k的值)
要想ECA能合适地进行局部通道交互,那么要确定合适的k值,手动调肯定不行。
作者们找到了k值和通道数之间的一个关系,在网路中通过知道通道数就能计算出最佳k值,从而实现自适应k值。
首先来看,在k和C(通道数)之间可能存在这样一种关系:
最简单的一种映射就是一个线性,比如:
因为线性也是限制,所以不太合适。
进一步地,我们知道通道数通常是2的指数,因此作者将上面的线性关系扩展到非线性关系:
则在实际应用中,当我们知道通道数后,我们就可以计算出最佳k值:
表示t的最邻近偶数
然后通过实验,最终确定了关系使用的系数:
- γ=2
- b=1
3.3 ECA模块
图2给出ECA模块的结构图,图3给出Pytorch实现的ECA模块。
首先对输入特征图进行GAP运算,再对结果进行1D卷积(kernel_size=k),最后跟上一个sigmoid函数。
4、Experiments
一些细节就不展开了,重点中介一下实验结果。
4.1 分类
表3展示了再ImageNet任务上不同注意力方法的表现。需要注意的是,ECA的精度不一定是最好的,但是请注意ECA和主干ResNet相比,其参数量Param和计算量FLOPs几乎持平(肯定有增加,但是非常少),但是提升的精度却很大
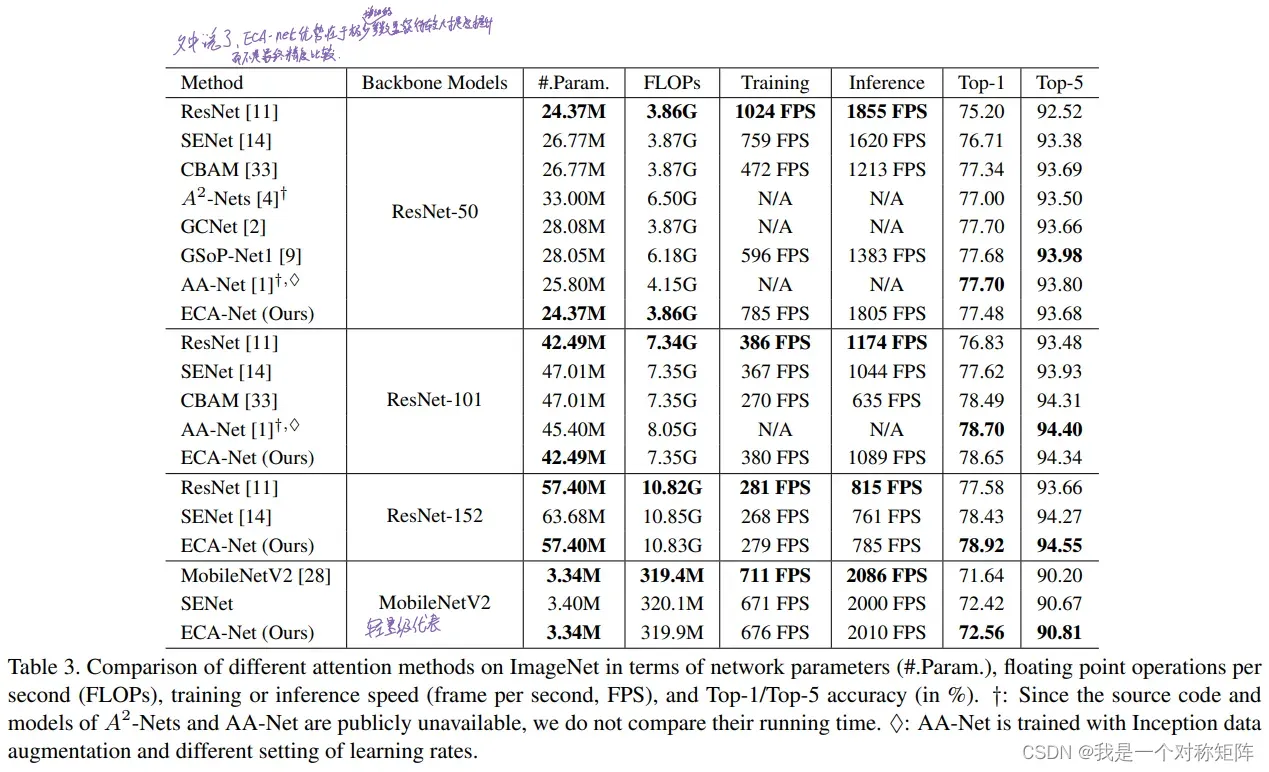
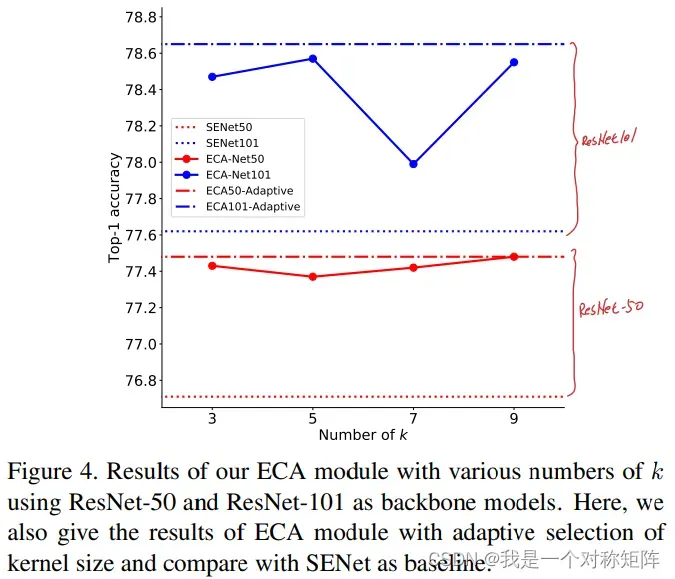
图4展示了手动调K值和自适应确定k值的方法的比较,可以看出自适应方法总是高于手动调k的,证明自适应k值是有效的。
4.2 物体检测
能打
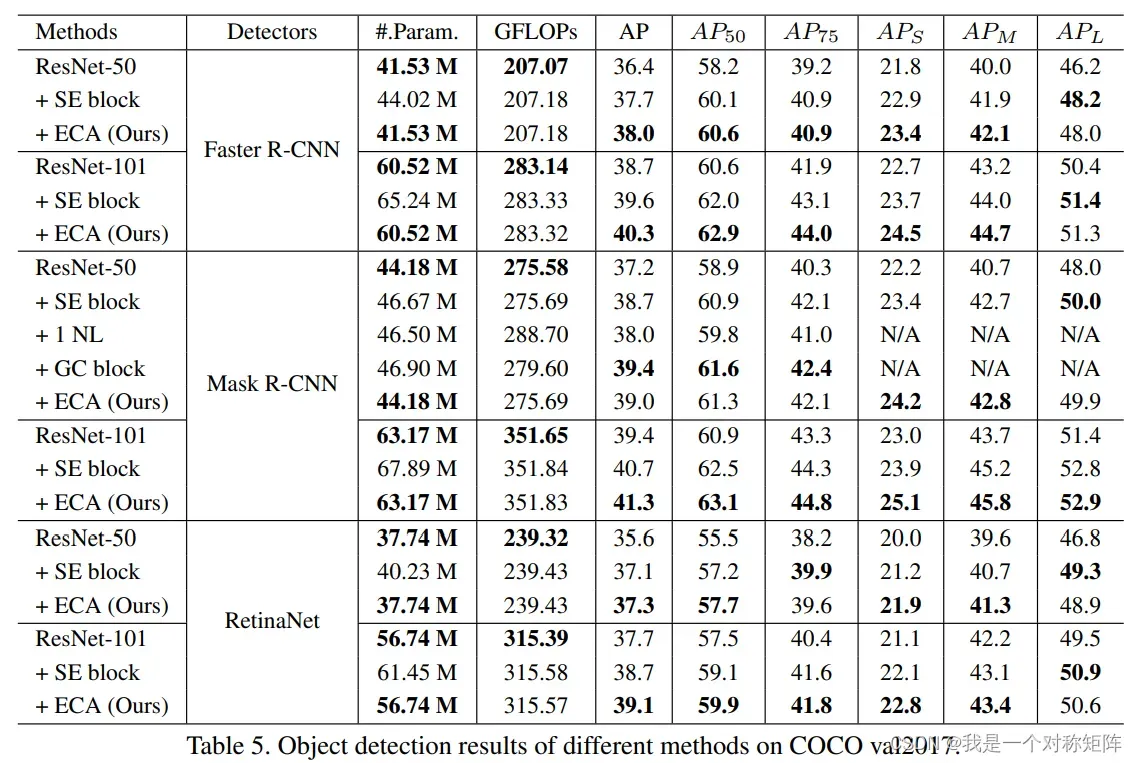
4.3 实例分割
能打
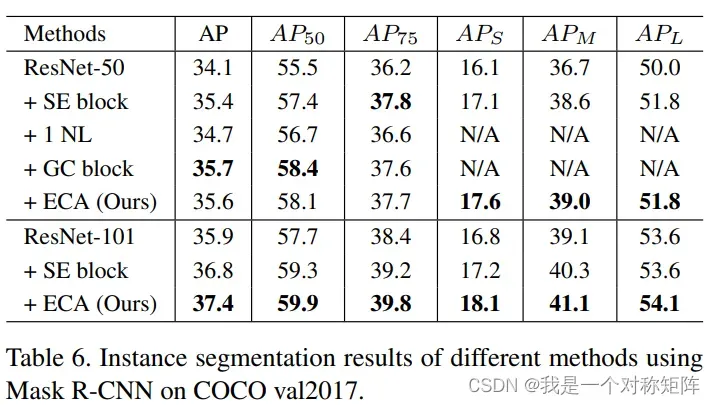
5、Conclusion
在本文中,我们实现了一个高效且有效的注意力模块ECA。它可以非线性地自适应计算k值并使用1D卷积快速实现。通过各种实验表明ECA是一个非常轻量化的能提高各种网络结构的即插即用插件。在图像分类、物体检测和实例分割等任务上也有非常好的泛化能力。
下一步是研究一种ECA的空间注意力模块。
文章出处登录后可见!