


一、Classification as Regression?
1. Regression是指输入一个向量,输出一个数值,然后我们希望这个数值与某个label越接近越好。
2. 我们可以把Classification当作Regression来看。输入一个x,输出是一个scaler,也就是y。我们希望y跟正确的class越接近越好,但是y是一个数字,于是我们把class也变成数字。
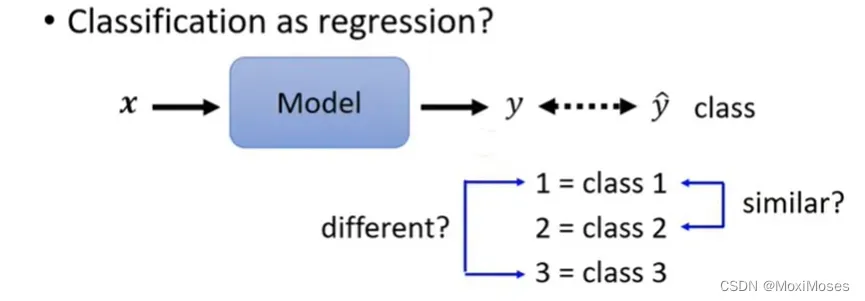
3. 如上图所示,在某些情况下,存在瑕疵。因为意味着我们认为Class 1与Class 2比较像,Class 1与Class 3比较不像。因此,当3个Class间存在某种关系时,是可行的;当3个Class间不存在某种关系时,是不可行的。


二、Class as one-hot vector
1. 在分类问题时,常见的做法是把你的Class用One-hot vector表示。因为用One-hot vector计算距离,Class之间两两距离是相等的。
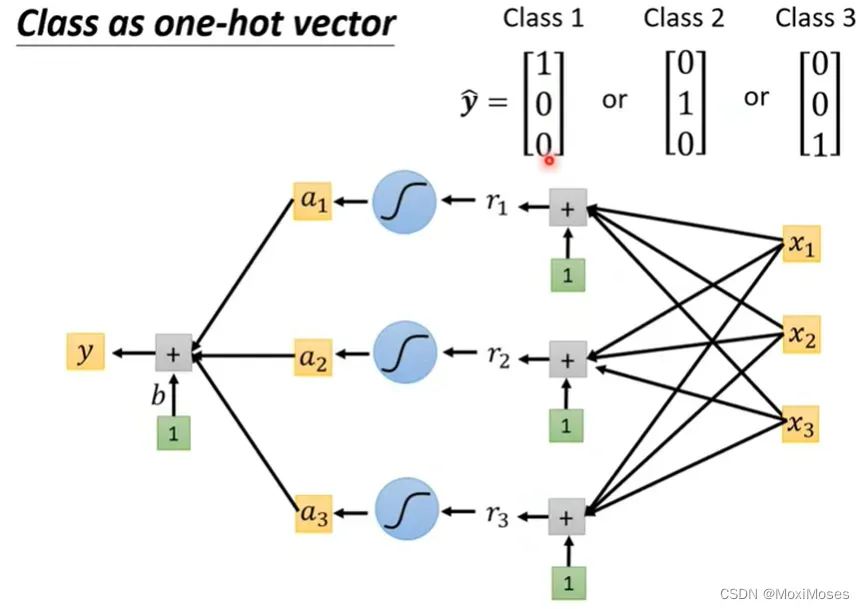
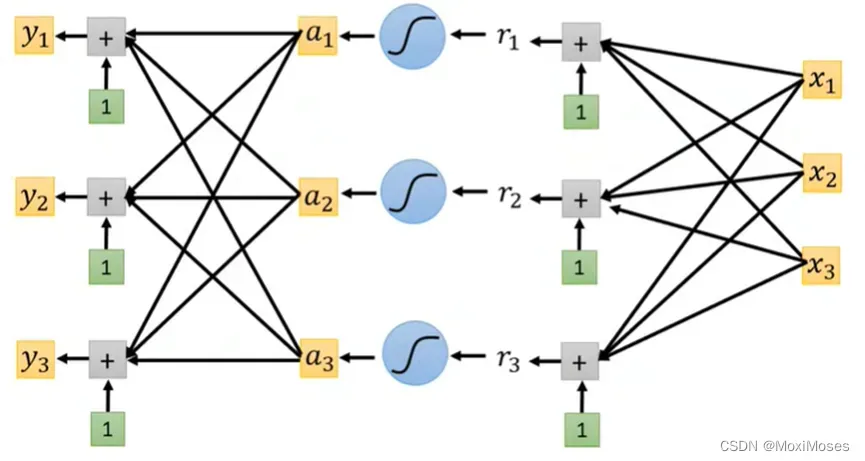
2. 我们现在的network只输出一个数值,因为我们之前做的都是Regression问题,所以输出一个数值。现在我们要把输出一个数值改成输出三个数值,我们只需要把输出一个数值的方法重复三遍。


三、Classification with softmax
1. 我们在做Classification时,y不在是一个数值,而是一个矢量。我们会把y通过softmax得到y’,再去计算y’与ŷ之间的距离。
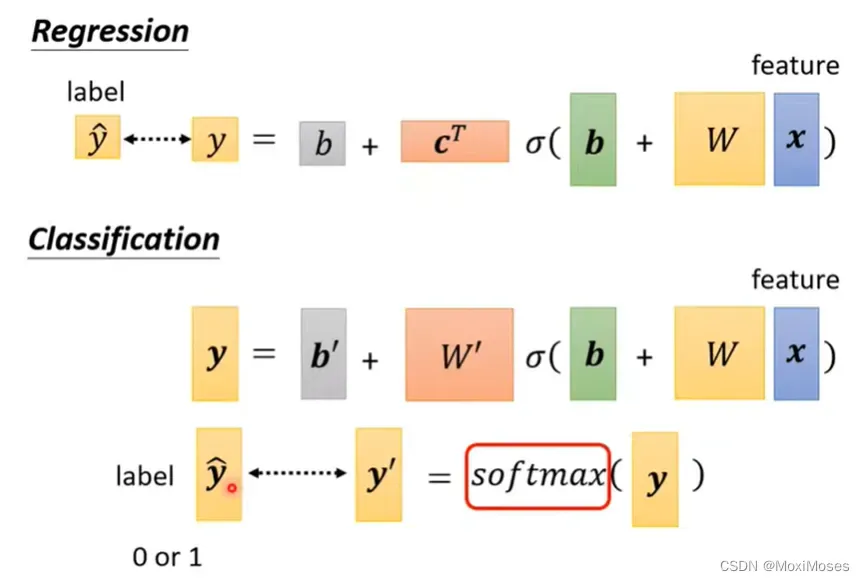
2. ŷ里面的值只能是0和1,而y里面可以是任何值。现在目标是0和1,但y有任何值,于是我们把它Normalize到0到1之间,然后去跟label计算相似度。
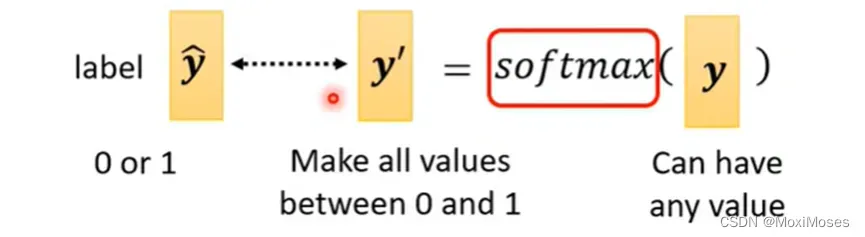


四、Softmax
1. 如下图所示,我们会发现y1’,y2’,y3^’都介于0到1之间,并且它们的和是1。Softmax会让大的值跟小的值差距更大。
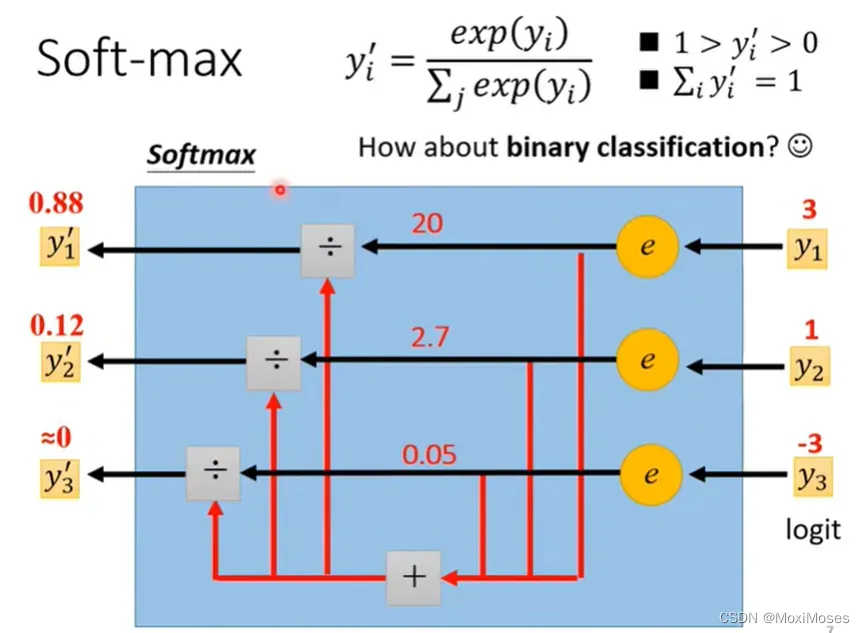
2. 当考虑两个Class时,我们除了直接用softmax,还可以取sigmoid。两个Class用sigmoid和softmax两个Class是等价的。

五、Loss of Classification
1. 计算y’跟ŷ之间的距离不只一种做法。第一种是Mean Square Error,第二种是Cross-entropy。当ŷ跟y’相同时,我们可以Minimize Cross-entropy的值,这个时候Mean Square Error是最小的,Cross-entropy也是最小的。
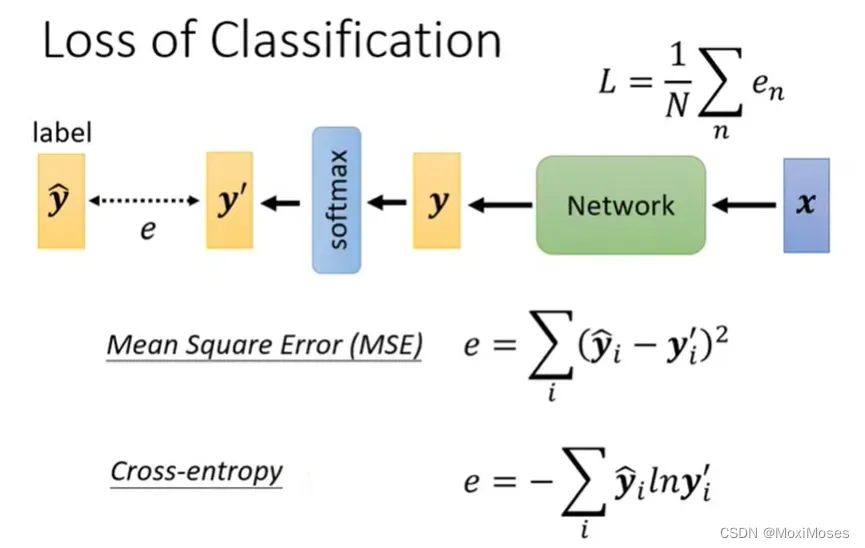
2. Minimize Cross-entropy与maximize likehood(极大似然)一模一样,但Cross-entropy更常用在Classification里面。在pytorch里面,Cross-entropy与softmax绑定在一起,你只需要copy Cross-entropy,里面就会自动内建softnmax。

3. 从optimization的角度说明Cross-entropy比Mean Square Error更常用到Classification上,如下图所示。
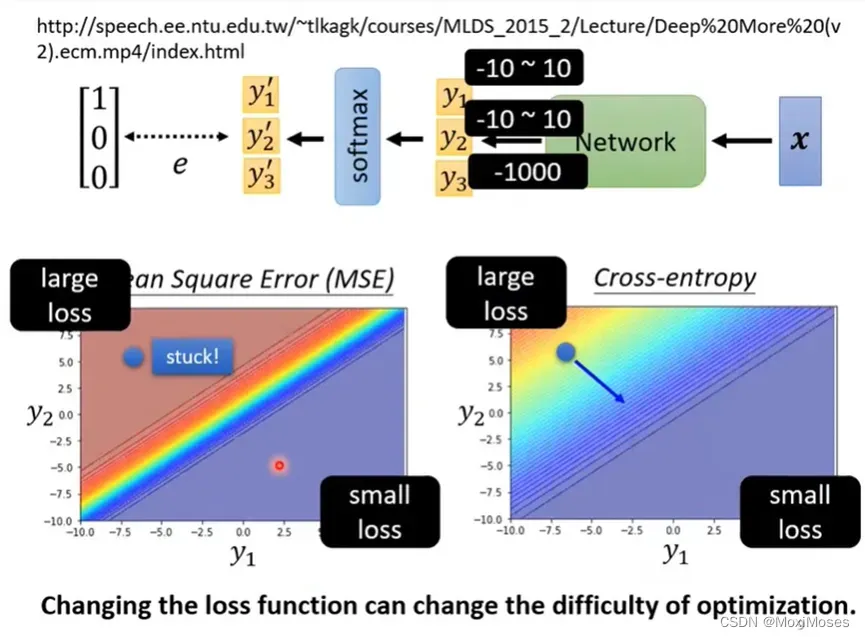
1) 我们把y3设成一个定值,观察y2和y3有变化时,把很多e加起来成Loss,看对我们的e和Loss有什么影响。
2) 现在用红色代表Loss大,蓝色代表Loss小。y1大,y2小,代表了y₁’会很接近1,y₂’会很接近0,所以不管对Mean Square Error,还是Cross-entropy而言,这种情况Loss都是小的。y1小,y2大,这时的Loss会比较大。
3) 当开始的地方在左上角时,如果选择Cross-entropy,这个地方gradient很大,因此可以到达右下角的地方;如果选择Mean square error,在这个Loss很大的地方,gradient趋近于0,因此不能够到达右下角。



总结
对于Loss Function的定义,都可以影响Training的难易度,因此我们可以通过修改Loss Function来改变Optimization的难度。
文章出处登录后可见!