序言
本文是对2021年秋季CS224W课程slides的速记,没有作业的解答。
CS224W其实看下来更偏向于是理论计算机方向的研究(比如图论),而非重点在图神经网络,因此很多内容理论性很强,本文是笔者花两天时间速过了一遍记录的一些对自己有用的要点,更偏向于图神经网络应用方面的摘要,一些没看懂的部分暂时没有深入研讨,仅先留个印象。
课程链接:http://web.stanford.edu/class/cs224w/
节点中心度
给定无向图,节点
的中心度(centrality)
用于衡量节点
的重要性,具体有如下几种计算方式:
-
特征向量中心度(eigenvector centrality):节点重要性由与它相邻节点的重要性决定
其中表示节点
的邻接点,
为标准化系数。
求解上式等价于求解
,其中
为无向图
的邻接矩阵,因此等价于求解
必然为正,则通常使用最大特征值
作为式
的解。
-
中介中心度(betweenness centrality):节点重要性由它中转多少对节点之间的最短路径决定
如在无向图中,
-
紧密中心度(closeness centrality):节点重要性由它与所有其他节点的距离之和决定
如在无向图
图基元
-
首先定义图的同形(isomorphism):称两个节点数相等的图
与
是同形的,若存在一一映射
,使得
(比如五角星和五边形就是同形图)。
判断两个图是否同形是NP-hard
-
图基元(graphlets):非同形的图构成的集合。
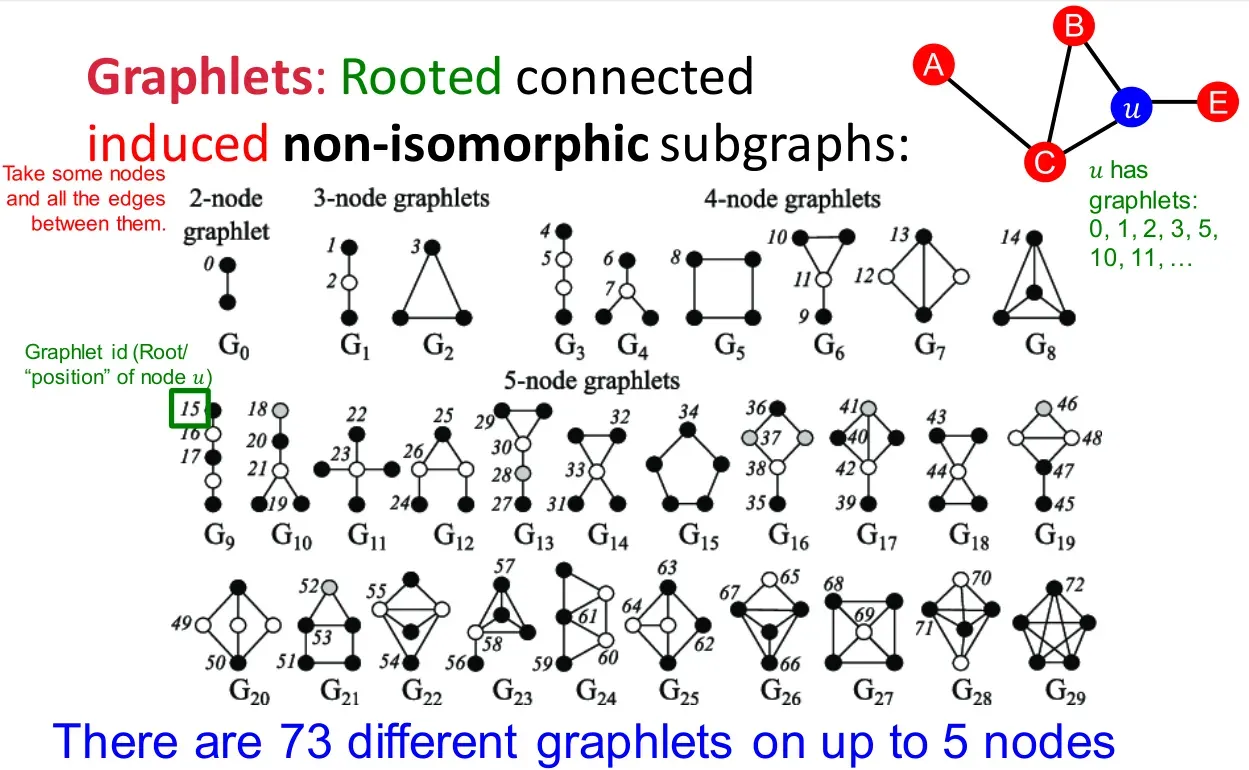
-
图基元度向量(graphlet degree vectors,GDV):
节点
的GDV由它所在的子图中不同图基元节点出现频率构成。
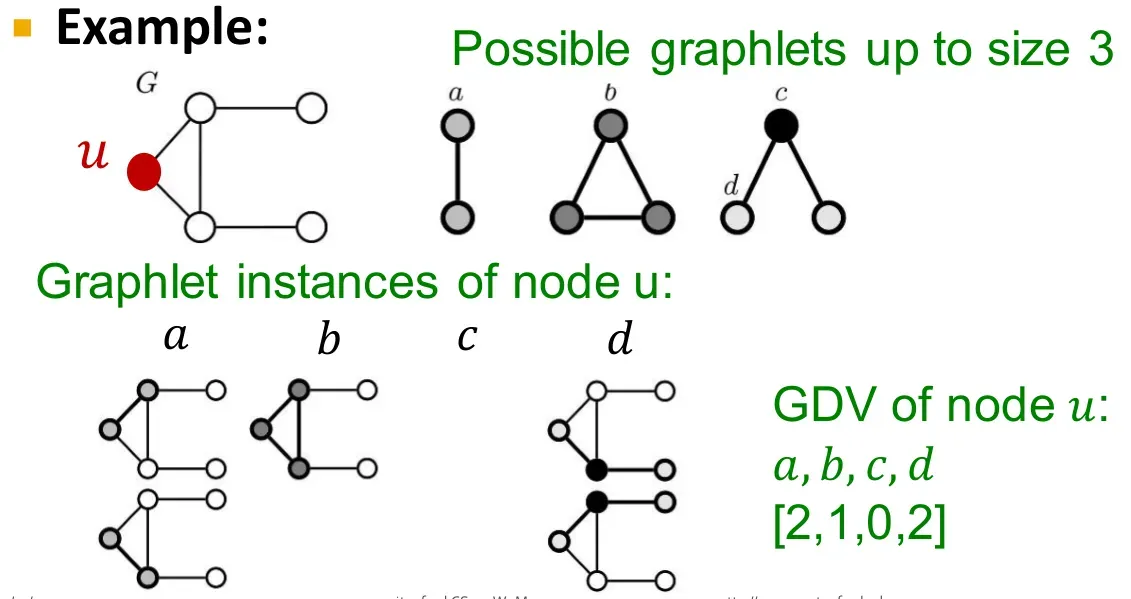
计算两个节点之间路径总数的巧解
定义无向图邻接矩阵
:
定义路径计数矩阵:
则可以证明,这里的路径可以不是简单路径(即路径重可以存在环或重复边)。
可以通过数学归纳法证明:
结论在有向图上同样适用,得到的称为Katz索引。
图核
图核(graph kernels)用于衡量图的相似性。
举个最简单的例子,对于两个图与
,执行某种图分解算法
:
基于分解得到的子图,定义核值(kernel value):
其中函数在两子图同构时取
,否则取
,这样就将大的图同构问题转化为小的图同构问题,不同的分解算法
和不同的同构定义
可以得到不同的图核计算方式。
此外还可以使用一些其他的图特征向量表示手段:
-
统计图中不同度数的节点数量,构成一个特征向量;
-
统计图中不同图基元的数量,构成一个特征向量;
笔者注:图基元的统计是非常复杂的,若图节点度数不超过
,则统计节点数不超过
的图基元的时间复杂度为
;
然后计算特征向量之间的相似度。
最后一种经典的算法是重染色(color refinement):
-
首先给全图每一个节点都染上初始颜色
-
然后进行
轮迭代染色(
其中函数将不同的输入映射成不同的数值;
-
最后将具有同样染色序列(即
)的节点定义为同类型的节点,统计各类型节点的数量构成特征向量;
这种算法运行速度要远远快于统计图基元的做法。
节点嵌入之随机游走
随机游走(random walks)的思想源于如果从出发大概率能走到
,那么这表明两个节点是相似的。
首先定义几个标记:
-
:表示节点
-
:从节点
那么我们认为近似等于
和
将会同时出现在一条随机游走路径中的概率。通常我们会固定随机游走的长度为一个固定值且不会太大,长度为
时退化为邻接点搜索。
具体而言,从节点出发,根据某种随机游走的策略进行序列生成,然后优化各个节点的嵌入表示以拟合上述概率:
其中是节点嵌入映射,
表示从节点
出发,在策略
下随机游走能够抵达的所有近邻(neighborhood),实际仿真中
就等于从节点
出发抵达的节点集合。
上式中的目标函数本质上就是最大似然,即给定节点的情况下,预测它的近邻节点:
我们可以使用softmax函数来计算上式中的概率值:
这里又提到计算softmax函数的复杂度很高(主要是分母的计算太复杂),因此需要做负采样:
其中是sigmoid激活函数,
是随机采样得到的节点,此时无需计算softmax分母上所有节点的点积,只需要对采样得到的
个随机负样本
进行计算即可。负样本量
的取值通常在
到
,采样概率分布与节点的度数成正比。
最后说明随机游走策略的选取,这里只介绍一种偏差随机游走(biased random walks)方法:
-
每次定义往回走(即回到前一个节点)的概率
和不往回走的概率
-
对于偏向于广度优先搜索的随机游走,赋予
以较低的值(即大概率往回走);
-
对于偏向于深度优先搜索的随机游走,赋予
以较低的值(即大概率往下走);
这里的概率都是未经标准化过的概率,一般来说会在往下走的节点里面找到一个节点编号最小的(即深度优先搜索默认的下一个节点)来赋予它的概率权重为(同样是未经标准化的),然后将一大堆
和
进行标准化后得到最终的概率值。
一些其他随机游走方法的相关研究:
整图嵌入
-
方法一:计算每个节点的嵌入并累和。
这个方法在参考文献中有使用。 -
方法二:引入一个虚拟节点来表示整图(或子图),然后计算虚拟节点的嵌入。
这个方法似乎只能用于子图嵌入的学习,整图就只有一个虚拟节点无法学习。在参考文献首次提出。
-
方法三:匿名游走嵌入(anonymous walk embeddings)。
参考文献首次提出,具体操作如下所示:
-
首先还是若干次随机游走采样,只不过这次记录随机游走的节点序列的方式稍有变化,一般情况下我们记录的是ABCBC,这里因为是匿名,所以记录为
,注意到在匿名的情况下ABCBC与DEFEF是完全没有区别的。
-
在匿名的条件下,不同长度的随机游走序列的数量如下图所示:
随机游走序列长度 不同随机游走序列数量 以长度为
为例,不同的序列有
-
然后以匿名的方式,采样
条随机游走路径(用于刻画图的一个概率分布):
其中是上表中给定长度的匿名随机游走序列的种类数(如采样长度为
时
),并期望有不超过
的概率得到的分布误差超过
-
接着直接学习每一条匿名随机游走序列的嵌入表示
-
最后将学习得到的所有
通过某种运算得到整图嵌入
:
上式中目标函数的含义是来预测在一个大小为的窗口内,同一个匿名随机游走序列同时出现的概率,
表示采样得到的随机游走序列的数量。
举个例子,采样得到
,固定
,则预测
在给定
下出现的概率。
-
但是提出文里的操作稍有区别,这里的采样通常是从一个固定节点
的随机游走序列:
然后预测随机游走序列同时出现在大小为的嵌入为
其中:
同理上式softmax概率的计算依然需要使用负采样来简化,部分的意思是先将各个随机游走序列的嵌入取均值,再和整图嵌入
是需要学习的参数,其实就是一个全连接层。
-
最终我们得到了整图嵌入
-
PageRank算法
计算PageRank的方法有点类似计算马尔可夫链中的稳态概率,原始的PageRank做了一个很强的假定,即一个页面指出去的所有链接都是等权重的,这构成了一个特殊的马尔克夫矩阵。然后计算
即可得到所有页面的权重构成的权重向量
求解有很多近似迭代算法,最简单的方法就是初始化
是等权重的,然后每次迭代
即可收敛。
但是PageRank算法存在两个问题:
-
页面是死胡同(没有指出链接),就会造成页面重要性泄漏;
解决方案:让死胡同节点以等概率指向所有其他页面。
-
页面所有的指出链接都属于同一个group,即存在一大堆页面构成的孤岛区域,此时页面重要性就会被这个孤岛吸收掉,这称为蛛网陷阱(spider traps)。
解决方案:每次随机游走以小概率跳到随机页面中。
一般
非常简单的例子,两个页面,,此时就会发生死胡同问题;如果是
,则会发生蛛网陷阱问题。
二分图推荐
常见的商品和用户(购买与评分)会构成二分图的关系,根据这样的关系可以对用户进行商品推荐,如查询与某个商品关联度最高的另一个商品。
从路径的角度来看,可以计算两个商品之间的距离,但是只看距离肯定是不够的,比如两个商品被同一个人购买,与两个商品被同一群人购买,这两个商品的相似度肯定是不一样的。
因此类似PageRank,我们认为每个商品都有一个重要性,可以通过随机游走来衡量这种重要性,算法代码如下:
item = QUERY_NODES.sample_by_weight()
for i in range(N_STEPS):
user = item.get_random_neighbor()
item = user.get_random_neighbor()
item.visit_count += 1
if random() < ALPHA: # 跳转
item = QUERY_NODES.sample_by_weight()
比如上面代码从出发,设定
,我们可以统计每个商品被访问的次数,然后即可得到与
相似度最高的商品集合。
这种算法考虑到了商品和用户之间的多重联系、多重路径,直接与间接联系,因此是具有很高可信度的。
节点分类之消息传递
-
场景:图中一些节点已有标签,如何给其他节点赋上标签?
-
算法:
其中表示节点
这样就将每个节点的标签信息进行了传播。
注意上式的收敛性不能得到保证。
-
具体而言,首先将每个节点的标签概率赋好,有标签的直接给对应标签赋确定概率,没有标签的给每个标签赋等概率值。然后通过上面的消息传递算法进行迭代。
当然节点分类也可以直接用节点的特征向量来表示(用来预测
),有一个经典算法是迭代分类器(iterative classifier),在迭代过程中不断修正
和
,不过个人觉得直接用机器学习来得容易些。
后面还有一个Correct & Smooth的分类器,重点是预测分类完之后做的后处理算法,看起来很高端,但是我觉得好像没有什么用,感觉很像是对训练残差做二次训练。找到一篇论文精读和实现的博客,可以参考,不一定有用。
置换等变异性
置换等变异性(permutation equivariance)是说图节点本身没有次序可言,定义一个图,其中
是邻接矩阵,
是所有节点特征向量拼成的特征矩阵,对于不同次序的节点编号,
的行列可能是需要置换的,那么如果存在一个函数
,使得对于任意两个不同次序的节点编号得到的
和
,都有
成立,则称
是置换等变异性函数。
GCN(mean-pool)
[Kipf & Welling, ICLR 2017]
-
思想:节点的近邻定义了一个计算图(computational graph),即每个节点可以根据近邻的边来聚合近邻的信息。
-
基本方法:对近邻节点的信息取平均实现消息传递。
其中是节点
是总网络层数,
和
是可学习的参数。
通过某种方法初始化
,最后一层的输出作为节点嵌入
可以改写为矩阵形式:
其中,
是节点度数对角矩阵。
-
图卷积层是置换等变异性函数
-
一般损失函数可以定义为:
其中是标签值,在
相似时标注为
,否则为
(其实一般只有
才标注为
可以理解为向量内积,外面套着的是交叉熵。
-
与CNN的对比:显然CNN就是一种特殊的GNN。
-
与Transformer的对比:事实上Transformer也可以看作是一种特殊的GNN,它的计算图就是一个完全图(所有输入分词看作节点,节点之间相互有边相连)。
消息计算与消息聚合
广义上的GNN网络层的逻辑由消息计算和消息聚合两步组成,合在一起就是消息传递。
-
消息计算:
每个节点生成信息,用于传递给其他节点,最简单的形式如 -
消息聚合:
简单的聚合函数可以是求和、取平均、取最大值等。
这里有一个问题就是我们可能担心节点
即直接把上一层节点
通常来说GNN中进行BatchNorm和Dropout(随机丢弃图中节点,剩下节点构成子图)也是很必要的。
GraphSage(max-pool)
[NeurIPS 2017]
GCN显然可以套用上面的形式,记录一个常用的GraphSAGE层:
常用的聚合方法有:
-
平均:
-
池化:
-
LSTM:
表示对近邻进行打乱顺序。
此外GraphSage中对隐层状态进行正则化:
否则生成的节点嵌入的尺度会不一样。
GAT
图注意力网络(Graph Attention Networks,GAT):
在GCN或GraphSage中,是等权重的,这里会类似注意力机制,根据节点相似性一个注意力权重。
一些常见的做法:
-
定义注意力函数
,得到一个得分值:
比如可以是:
-
使用softmax函数计算得分值的权重分布:
此外还可以是多头注意力,即多用几个不同的注意力函数,生成不同的权重
,然后对结果取聚合:
比如函数可以直接就是拼接,这样信息损失得最少。
GNN使用技巧
-
图结构增强:
① 图太稀疏,则添加虚拟节点或虚拟边(比如将二级近邻之间也连上边,或者直接
)。
② 图太稠密,则消息传递时选择对近邻进行采样。
③ 图太庞大,则采样子图计算子图的嵌入,如可以通过重复的随机游走来采样,但要尽可能保持原始图的连通性(从消息传递的角度来说是这样的)。
-
图特征增强:比如使用节点的度数、聚类稀疏、PageRank、中心度等。
-
GNN训练管道:输入图
GNN网络层迭代
-
节点级别的预测头:直接
(节点嵌入输入到一个全连接层)
-
边级别的预测头:
,简单的方法就是拼起来然后输入到全连接层,即
,也可以取点积
(这个只能输出一个标量),或是二次型
(这个可以多用几个不同的
,将得到的标量结果拼起来,得到的是一个向量)
-
图级别的预测头:这个就与GNN网络层中的
-
层级图池化(hierarchical global pooling):
直接对所有节点嵌入的每一维进行池化是不合理的,这样嵌入的每一维都容易损失很多信息,因此可以两个两个进行池化,这样就少损失一些。
举个例子,对所有数字进行求和池化:
,
,这两个就没有区别了,但是两个两个使用
来池化,就很不一样了。
-
图划分:用于划分训练集,验证集和测试集,对于那种很大的图上的分类问题,一般就是随机采样节点得到子图作为验证集和测试集,剩下的大部分节点构成的子图作为训练集(注意这种做法要多随机划分几次,报告不同随机种子下的训练情况),这种配置称为是Inductive的。
注意只用子图可能也会影响图结构,因此有时候会选择Transductive的配置,即训练、验证都用全图,只不过训练时只计算训练集中节点或边的计算损失函数,验证时用验证集中节点或边的标签计算评估指标。
GIN
[ICLR 2019]
图同形网络(graph isomorphsim network):
GIN的近邻聚合函数是单射(injective),GIN是目前最具有区分度的GNN(消息传递类型的GNN)!
GCN和GraphSAGE的聚合函数可能会将不同的multi-set输入映射成同样的输出,因此不是那么具有区分度,理想的那种将multi-set输入进行单射的函数应当形如:
其中和
都是非线性函数,
是multi-set输入(比如所有近邻的信息)。
记得前文提过的那个重染色法的函数就是一个单射,GIN相当于是用神经网络来模拟单射的
函数:
建模即为:
上面这种单射提升的是GNN的expressive power
异构图
异构:
,带关系的边
- 节点类型:
- 关系类型
RGCN
即关系型图卷积网络(Relational GCN),图的边上带有关系标签:
其中,即以关系
连接的邻接点数量。同样上式符合消息生成与消息聚合的形式。
每个关系对应
个矩阵(网络共有
层):
,其中
一般来说,需要对进行贵正则化,比如令
是对角块矩阵,或是令
,其中
是所有关系共用的一个矩阵(基础矩阵)。
-
RGCN用于链接预测:
① 首先RGCN对训练监督的边
进行评分
② 构建一个负边(negative edge,即加一条假边)
③ RGCN对负边进行评分
④ 目标函数包括最大化训练监督的边的得分和最小化负边的得分:
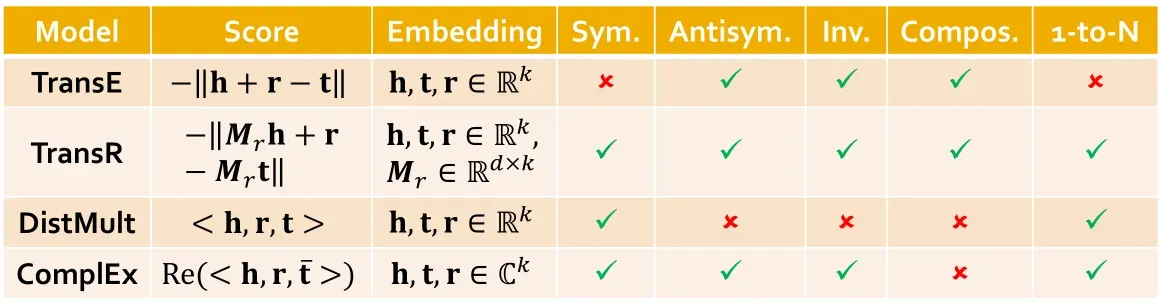
知识表示学习
知识图谱中关系类型:
- 对称关系(家人,室友):来回的关系一样;
- 互逆关系(导师,学生):来回的关系不一样;
- 复合关系(妈妈的爸爸是公公):关系叠加;
- 一对多关系(老师有多个学生):
指向多个
- 反对称(antisymmetric)关系:上位词(hypernym)和下位词,
,注意TransE可以建模反对称关系,即
得分函数:
-
翻译类型的得分函数:
-
TransE:

TransE可以建模互逆关系,复合关系,反对称关系,但无法建模对称关系和一对多关系。
训练的损失函数:
-
TransR:建模实体在空间
中,关系在空间
中,再来一个投影矩阵
(从实体空间映射到关系空间)。
①
,
②
此时TransR可以建模对称关系,反对称关系,一对多关系互逆关系,复合关系。
-
DistMult:
,即为连乘求和。
可以建模一对多关系,对称关系,不能建模反对称关系,互逆关系,复合关系。
-
ComplEx:
,
表示取实部。
其中向量是在
中建模,即是复数嵌入向量,
是共轭复数。
可以建模一对多关系,对称关系,反对称关系(使用),互逆关系,但不能建模复合关系。
关于对称关系的推导:
知识图谱与多级推理
-
知识图谱中的查询类型:
① 一级(one-hop)查询:
② 路径查询:
(这种就是多级推理)
③ 联合(conjunctive)查询:
举个联合查询的例子:什么药物能够治疗乳腺癌并且引发头痛?
理想情况下,如果知识图谱足够完备,那么直接通过逻辑搜索即可解决查询问题,然而实际上知识图谱永远不可能是完整的(随着时间需要更新,人工编纂也必然遗漏信息)。
-
知识图谱补全(KGC):
遍历知识图谱中长度为
路径的时间复杂度为
,其中
为节点最大度数。
但是我们可以在向量空间中遍历知识图谱的所有关系和节点!
比如给定一级查询
,然后找个与
即可。
多级查询
同理,联合查询等价于
,那就是要找一个
和
都接近(下面会告诉你具体怎么做)。
这种查询的思想也可以用于KGC。
-
盒嵌入(box embeddings):
可能有人注意到联合查询其实是不容易处理的,如果节点嵌入和关系嵌入学得不好,可能
因此可以考虑使用盒嵌入,即一类实体的嵌入(在超空间中就是一个超矩形的区域):
记录这块超矩形区域的中心和边界即可,然后联合查询就化简为超矩形取交集(应该也是一块超矩形),最后的目标就是找一个实体具体而言,关于盒嵌入有很多不同的做法,这里只举一种可行的做法:
① 实体嵌入都是向量,但关系嵌入是盒嵌入
② 那么
就映射到了一块盒空间:
③ 然后若干盒子的交集还是一个盒子(具体需要用神经网络训练这种映射):
④ 关于点到盒子的距离:
其中是点
边界的最短距离,然后
是从边界位置到盒子
是正则系数。
-
与或查询(AND-OR queries):
上面这种联合查询是交集,即是与查询,那么还可能有取并集,即或查询。
注意在二维平面上,三个节点
构成锐角三角形时,我们总是可以两两画出盒子将两个点框起来而不框进第三个点,但是如果是钝角三角形,就无法满足这种情况了,推广到高维空间亦是如此。因此或查询要更加复杂。
结论是:对于任意
个联合查询
以及互不覆盖(non-overlapping)的答案,我们需要
维的空间才能处理所有的或查询。
那么既然做与或查询这么困难,实际方法是先分别查询,然后在最后一步再取并集。
-
查询到盒子(query2box)的训练方法:
① 从训练图
中随机采样一个查询
,以及一个负样本
② 嵌入查询
③ 计算
与
④ 最优化损失函数
):
子图与Motif
motif好像就是节点导出子图(induced subgraph),主要是用于刻画图的局部特征,motif可以视为图的一个子结构,这种子结构可能在图中有多次出现。
关于motif的几个指标
-
:
用于刻画motif i的统计显著性
其中是图中motif i出现的次数,
是在随机生成的图中motif i出现的平均次数
-
网络显著性(network significance profile):
总的来说,图越大,越高。
我们很多时候是想要在图中挖掘出出现频次很高的motif,有点类似数据挖掘里的频繁项集,但是寻找频繁motif是一个NP-hard的问题。
跟下面的神经子图匹配一样,也有通过神经方法来解决这个频繁motif挖掘的问题(但是我还是每太看懂,这两个的方法其实是很接近的,但是就是看不明白)。
神经子图匹配(没有看懂)
神经子图匹配(Neural subgraph matching)问题定义:给一个整图和一个小图
,判断
是否是
的子图?
这个问题其实很复杂(要逐点逐边进行对比,显然是NP-hard),但我们可以使用神经网络的方法来解决(这倒是很新奇)。
思想是通过节点嵌入进行对比,但是原理每太看明白,感觉有点奇特。
推荐一篇其他人写的这章slide的博客,里面稍微记了一些笔记内容,但是不多,还是不太搞得明白。
推荐系统
问题抽象:给定用户与商品之间的交互信息,需要预测用户在将来会与哪些商品进行交互,这可以视为是链接预测问题。
TopK推荐:给每个用户至多推荐个商品,评估指标是Recall@K,即推荐的
个商品中,正确的商品数占用户真实将来交互的商品数的比例(
)
-
基于嵌入的模型:定义
是用户集合,
是商品集合,
是交互边
旨在计算
,那么就是计算两个节点嵌入的相似度
:
注意这种损失函数(称为Binary Loss)是非个性化的(non-personalized),因为所有正边和负边都是对于所有用户生效的,但是评价指标Recall@K是个性化的(要根据每个用户的来定)。
因此提出贝叶斯个性化排行损失:
总的损失函数定义为:
-
基于GNN的模型:
-
[Wang et al. 2019] Neural Graph Collaborative Filtering (NGCF)
协同过滤的神经版本,根据节点的嵌入来做的协同过滤。
-
[He et al. 2020] LightGCN
这个后面有一个章节(LightGCN概述)是讲这个网络的原理的,这里不赘述。不过这里的slide讲得好像更详细一些。其实本质上还是用的用户嵌入和商品嵌入计算得分函数。
LightGCN里聚合就是简单的等权平均。
-
PinSAGE [Ying et al. 2018]
这个是用于图像处理的GNN,是目前GCN最大的工业应用。
-
Louvain算法
Louvain算法是基于模块度的社区发现算法,该算法在效率和效果上都表现较好,并且能够发现层次性的社区结构,其优化目标是最大化整个社区网络的模块度。
GraphRNN
转载自https://zhuanlan.zhihu.com/p/272854914
图由若干个点和边构成,一个很自然的想法是,逐个生成这些点和边,也就是生成节点和连边的序列,这正是RNN擅长的事,所以有了GraphRNN模型。
下图是一个GraphRNN的示意图,表示序列每一步生成的元素,与传统RNN不同的是,GraphRNN每一步不仅要生成节点,还要生成这个节点与其他节点之间的连边,而要生成若干个连边,需要另一个序列生成模型,所以GraphRNN生成的序列S是一个Seq of Seq,即,序列的序列,这也正是GraphRNN复杂的地方。
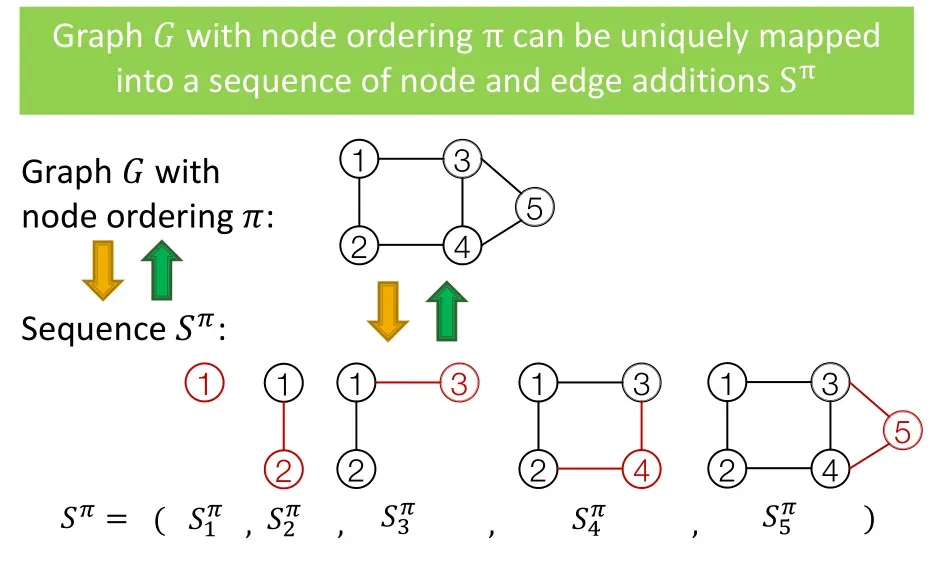
下面来看一个GraphRNN的示例,第一个unit是序列的其实状态,第二个unit生成了1号节点,然后生成了下一个节点与1号节点的连边关系,值是1,因此第三个unit生成了节点2,并且节点2与节点1相连,然后生成下一个节点与节点1和2的连边,即图中的,节点3和节点1连接,与节点2不连接,由此到下一个unit,生成了节点3,剩余unit可以以此类推。这里,Node-level的RNN只负责生成Edge-level RNN的初始状态,Edge-level RNN负责生成连边关系。
课程中还提到,训练时采用Teacher Forcing方式,即,下一个unit的输入不来自上一个unit的输出,而是上一个unit的label,这就保证了GraphRNN一定可以生成一张一模一样的图,但是这种过拟合的方法在实践中是否管用,笔者持保留意见。
一些前沿研究
-
位置感知(position-aware)的GNN:
相对概念的结构感知的图,结构感知的图会将图中的等价节点标注为一类(可以看Graphlet的那个图里,只标注的同类节点,未标注的其他节点在结构上都有同等的对应),位置感知的图则有点类似聚类的标注,比如同属于一个三角形的三个顶点会标为一类,另一个三角形的三个节点标为另一类。
GNN总是会在位置感知的任务上失败,因为GNN对位置并不敏感。
因此需要引入一个锚定点(Anchor),随机选取即可,以相对于锚定点的距离来判定不同节点的位置。
类似有推广到锚定集合,即选一群点作为锚定。
基于此可以训练得到带有位置信息的节点嵌入和边嵌入。
-
身份感知(identity-aware)的GNN:
这个考虑的问题是,在一些情况下,输入不同的图,但是它们的计算图是完全相同的。
这个问题感觉偏理论计算机研究的领域,由此衍生出的概念是ID-GNN
看到这里越来越觉得GNN真的没有看起来那么简单,相比于神经网络,GNN有更多需要发掘的理论问题,根源就是图论的复杂性,很多图论问题都可以拉到GNN里来考虑。
-
GNN的鲁棒性(robustness):即对图做微扰,预测结果发生的变化。
LightGCN概述
[Wu et al. ICML 2019],从原先的GCN模型中去除了非线性激活层。
数学标记定义:
- 邻接矩阵
,这个在GCN里也是这么处理的;
- 节点度数矩阵
- 正则化的邻接矩阵
表示第
,
为可学习得到参数;
文章出处登录后可见!