入门 python 看这一篇就够了(建议收藏)
写这篇文章的初衷是我经常用诸如 MATLAB、C++\C、R 语言、python 等不同的语言,因为它们在数据结构和语法上的细小区别,经常让我搞混了,特此做个笔记,将 python 的常用数据结构和函数做一个基本备份,引以为查询用。
学习一门语言有必要系统体系地从头到脚学一遍吗?我认为有必要,但是没意义。如果你有一些其他语言的基础,想要入门 python,那么最好的方式就是了解一下它有哪些数据结构和循环等怎么写,并自己敲一些代码测试一下,剩下的就是直接拿它开始干你想让它帮你做的事,遇到问题面向浏览器编程,一点一点熟悉就好了。
基本数据结构(此 section 会动态更新)
Talk is cheap. Show you the code!
下面列出了 python 中最最最基础的数据结构和用法(列表、 numpy 数组等),你花 10 分钟,把它们每一条试一试都过一遍,理解不了运行结果是为什么那样的查一查搞明白,那们你的 python 已经入门了。主要是 python 的 6 个基本数据结构,numpy 包的用法。pandas 和 matplotlib 可以先放一放,因为相比之下他们显得不是特别关键。别的花里胡哨的东西,比如类、函数、匿名表达式等等,都不是关键,可以后面用到了再摸索。
from matplotlib import pyplot as plt
import numpy.matlib
import numpy as np
#基本运算
9 // 4 # 除法,得到一个整数
2 ** 5 # 乘方
## 基本数据类型
# Python3 中有六个标准的数据类型:Number(数字)String(字符串)
# List(列表)Tuple(元组)Set(集合)Dictionary(字典)
# 不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组);
# 可变数据(3 个):List(列表)、Dictionary(字典)、Set(集合)。
list = [2.23, 'test', 70.2] # list 相当于 MATLAB 的元胞数组,支持不同的类型,用中括号括起来
print(list) # 输出完整列表
list[1:3] # list 索引从 0 开始
list[1] = [] # 将对应的元素值设置为 [],并不代表去掉这个数
a = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
a[3:4] = [] # 去掉某一个数,a[3] = [] 这样不行,只有列表赋值列表可以
str = 'lusongno1' # 可以把字符串看成是每个位置都是一个字母的 list,但赋值后不可变
str[0:-1] # 下标从 0 开始,左开右闭区间,-1 表示最后一个位置
str[2:] # 用法和 MATLAB 类似,只不过 end 直接不写了
str * 2 # 输出字符串两次
str + "TEST" # 连接字符串直接用加号
dict = {} #大括号里面不写东西就是初始化为字典,否则初始化为字典
dict2 = {'one': 'test', 2: 'lusong'}
dict['one'] = "test"
dict[2] = "lusong"
dict.keys()
print(dict.values())
print(dict)
tuple1 = ('abcd', 786, 2.23) # 注意,元组是用小括号括起来的
print(tuple) # 打印元组
print(tuple1[1:3]) # 其他用法和list 类似,但是不可修改
tup1 = () # 空元组
tup2 = (20,) # 一个元素,需要在元素后添加逗号
sets = {'e1', 'e2', 3, 'e4', 'e5', 'e5'} #集合里面也支持不同元素
print(sets) #输出集合,重复的元素被自动去掉
a = set('abracadabra')
b = set('alacazam')
(a - b) # a 和 b 的差集
(a | b) # a 和 b 的并集
(a & b) # a 和 b 的交集
(a ^ b) # a 和 b 中不同时存在的元素
# 推导式用法
{x: x**2 for x in (2, 4, 6)} #元组遍历自动推导出字典,对别的数据结构也有类似用法
names = ['Bob', 'Tom', 'alice', 'Jerry', 'Wendy', 'Smith']
new_names = [name.upper() for name in names if len(name) > 3]#列表自动推导
a = (x for x in range(1, 10)) #返回的是生成器对象
tuple(a) # 使用 tuple() 函数,可以直接将生成器对象转换成元组
# numpy 用法
np.eye(4)
a1 = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
a1@a1 # np 的矩阵乘法
a = np.array([1, 2, 3, 4, 5], ndmin=2) #ndmin 表示生成的数据是几维的,低于实际维数不起效
a = np.array([1, 2, 3], dtype=complex) #复数类型的
dt = np.dtype([('name', 'S20'), ('age', 'i1'), ('marks', 'f4')]) #用元组来定义类型名称和类型
a = np.array([('abc', 21, 50), ('xyz', 18, 75)], dtype=dt) #相当于定义了一张表,dt 是表头
print(a['age'])
a = np.arange(24)
print(a.ndim) # a 现只有一个维度,python 是行优先的
b = a.reshape(2, 4, 3) # b 现在拥有三个维度,等价于使用 a.shape = (2,4,3)
print(b.ndim)
print(a.shape)
xx = np.empty([3, 2], dtype=int)
print(xx)
x = np.zeros([5,2]) #方法的方式,一般同一参数输入用列表或者元组圈一起
x2 = np.zeros([5,2]) #方法的方式,一般同一参数输入用列表或者元组圈一起
x = np.ones([2, 2], dtype=int)
print(x)
x = [(1, 2, 3), (4, 5,6)]
a = np.asarray(x) #把任意的数据结构转成 numpy array,比较随意
print(a)
x = np.arange(10, 20, 2) #指定间隔生成数组
print(x)
a = np.linspace(1, 10, 5) #均分的方式生成数组,和 MATLAB 类似
a = np.logspace(0.0,2.0,10, base=10) #把 0 到 2 十等分,再取 10 为底数
a = np.arange(10) #表示 [0,10],python 总是左闭右开的
b = a[2:7:2] # 从索引 2 开始到索引 7 停止,间隔为 2,这和 MATLAB 类似,只不过间隔是最后一个
a = np.array([[1, 2, 3], [3, 4, 5], [4, 5, 6]])
print(a)
print(a[1:]) #取第 1 行到最后 1 行,标号从 0 开始
a = np.array([[1, 2, 3], [3, 4, 5], [4, 5, 6]])
print(a[..., 1]) # 第2列元素,... 相当于是 MATLAB 的 1:end,即取全部 :
print(a[1, ...]) # 第2行元素
print(a[..., 1:]) # 第2列及剩下的所有元素
x = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11]])
rows = np.array([[0, 0], [3, 3]])
cols = np.array([[0, 2], [0, 2]])
y = x[rows, cols] #得到和 rows与cols规模大小一样的矩阵,其中 rows 行标,cols 列标
print(y)
a = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
b = a[1:3, 1:3]
c = a[1:3, [1, 2]] #注意,1:3 并不等同于 [1,2]
d = a[..., 1:] #当输出的结果形状无要求的时候,用法和 MATLAB 一致
x = np.array([[0, 1, 2], [3, 4, 5], [6, 7, 8], [9, 10, 11]])
print(x[x > 5]) #使用 bool 方式类索引,和 MATLAB 一致
x = np.arange(32).reshape((8, 4))
print(x[[-4, -2, -1, -7]]) #索引一个位置的参数,只能输入一个对象
x = np.arange(32).reshape((8, 4))
print(x[np.ix_([1, 5, 7, 2], [0, 3, 1, 2])]) #取出1572行的0312列
x[1:5, [0, 3, 1, 2]]# 不同于 x[[1,2,3,4], [0, 3, 1, 2]]
a = np.array([[0, 0, 0],
[10, 10, 10],
[20, 20, 20],
[30, 30, 30]])
b = np.array([1, 2, 3]) #自动广播机制
print(a + b)
a = np.arange(6).reshape(2, 3) #数据的内存排布方式由创建时就有了,而不由 reshape 改变
for x in np.nditer(a.T):
print(x, end=", ")#在输出中自动包含换行取消,改成 ‘,’
print('\n')
print(a.flatten()) #按行拉成一条,相当于 MATLAB 的 (:),和 nditer 不同,不是由数据创建时就决定了
print(a.flatten(order='F')) #列优先,也是 MATLAB 的风格
print(a.T) #求转置
a = np.arange(8).reshape(2, 2, 2)
print(np.where(a == 6)) # 使用 where查找满足条件的下标
a = np.empty([4,4]) #生成空数组
x = np.arange(9).reshape(1, 3, 3)
y = np.squeeze(x) #把一维的维度给挤压掉,
a = np.array([[1, 2], [3, 4]])
b = np.array([[5, 6], [7, 8]])
print(np.concatenate((a, b))) #沿着 x 轴拼接,输入方式以元组的方式提供
print(np.concatenate((a, b), axis=1)) #沿着 y 轴拼接
s1 = np.stack((a, b), 0) #自然堆叠到第 3 维
s2 = np.stack((a, b), 1) # a b 第一行堆叠到第一个维度
c = np.hstack((a, b)) #水平拼接,同 concatenate
c = np.vstack((a, b)) #竖直拼接
a = np.arange(12)
b = np.split(a, 3) #平均分成 3 份的列表
b = np.split(a, [4, 7]) #在 4 和 7 两个位置分割,47 分到了下一份
a = np.arange(16).reshape(4, 4)
b = np.split(a, 2) #第一个维度,即行分割成两份
c = np.split(a, 2, 1) #沿列方向分割
b = np.vsplit(a, 2) #沿着 x 方向分割
d = np.hsplit(a, 2) #沿着 y 方向分割
a = np.floor(10 * np.random.random((2, 6))) #随机数和取整
a = np.array([[1, 2, 3], [4, 5, 6]])
b = np.resize(a, (3, 3)) #不够的话会重复地利用
np.append(a, [[7, 8, 9]], axis=0) #在 x 轴上拼接
np.append(a, [[5, 5, 5], [7, 8, 9]], axis=1) #和list 也可以拼接
a = np.array([[1,2],[3,4],[5,6]])
b = np.insert(a, 3, [11, 12]) #在标号为 3 的数字前面插入 [11,12],并拉成一列(因为未传递参数)
c = np.insert(a, 1, [11,12], axis=0) #在行 1 前面,插入一行 11 12
d = np.insert(a, 1, 11, axis=1)# 在列 1 前面,插入一行全 11
a = np.arange(12).reshape(3, 4)
print(np.delete(a, 5))
print(np.delete(a, 1, axis=1)) #删除列 1
a = np.array([5, 2, 6, 2, 7, 5, 6, 8, 2, 9])
u = np.unique(a) #去重并且进行了一个从小到大的排列
u, indices = np.unique(a, return_index=True) #去重并返回新数组在原数组中的下标
u, count = np.unique(a, return_counts=True) #返回计数
ans = np.char.add(['hello'], [' xyz']) #连接两个字符串列表
np.char.multiply('hi, ', 3)
str = np.char.center('abcde', 20, fillchar='*') #两边填充字符串到总长度 20
print(np.char.capitalize('lusoNG!')) #变成只有首字母大写的形式
print(np.char.title('i LOVe yOu !')) #每个单词首字母大写
print(np.char.lower(['AMSs', 'GOOGLE'])) #小写全部字母
print(np.char.upper(['Lsec', 'google'])) #大写全部字母
print(np.char.split('i like runoob?')) #分割字符串,默认空格为分隔符
print(np.char.split('www.runoob.com', sep='.')) #以 . 为分隔符
print(np.char.splitlines('i\nlike runoob?')) #识别 \n 为分隔符
print(np.char.splitlines('i\rlike runoob?')) #识别 \r 为分隔符
print(np.char.strip('ashokaaa aruaaanbaaa', 'a')) #移除数组元素头尾的 a 字符
print(np.char.join(':', 'lusongno1')) #用冒号分隔每个字母
print(np.char.join([':', '-'], ['baidu', 'google'])) #两个单词用不同的分隔符
print(np.char.replace('i like dooooog', 'oo', 'cc')) #替换,一对一对替换
a = np.array([0, 30, 45, 60, 90])
np.sin(a/180*np.pi/6) #sin 函数
np.degrees(np.pi/2)#把弧度转为角度
a = np.array([1.0, 5.55, 123, 0.567, 25.532])
print(np.around(a)) #四舍五入
print(np.around(a, decimals=1)) #保留一位小数
print(np.around(a, decimals=-1)) #保留到十位
print(np.floor(a)) #向下取整
print(np.ceil(a)) #向上取整
a = np.arange(9, dtype=np.float_).reshape(3, 3)
b = np.array([10, 20, 30])
print(np.add(a, b)) #广播机制,a的每一列和b的每个元素操作
print(np.subtract(a, b))
print(np.multiply(a, b))
print(np.divide(a, b))
print(np.reciprocal(a)) #求倒数
print(np.power(a, 2))
a = np.array([10, 20, 30])
b = np.array([3, 5, 7])
print(np.mod(a, b)) #求余数
print(np.remainder(a, b)) #也是求余数
a = np.array([[3, 7, 5], [8, 4, 3], [2, 4, 9]])
print(np.amin(a, 1)) #取每一行的最小
print(np.amin(a, 0)) #取每一列的最小
print(np.amax(a))
print(np.amax(a, axis=0))
a = np.array([[3, 7, 5], [8, 4, 3], [2, 4, 9]])
print(np.ptp(a))
print(np.ptp(a, axis=1)) #每一行的最大减最小
print(np.ptp(a, axis=0)) #每一列的最大减最小
print(np.percentile(a, 50))
print(np.percentile(a, 50, axis=0))
print(np.percentile(a, 50, axis=1))#求每一行的 50% 分位数
print(np.percentile(a, 50, axis=1, keepdims=True)) #保持原来的维度不变
print(np.median(a, axis=1)) #求每一行的中位数
print(np.mean(a, axis=1)) #求每一行的均值
a = np.array([1, 2, 3, 4])
wts = np.array([40, 30, 20, 10])
print(np.average(a, weights=wts)) # 求加权平均
print(np.std([1, 2, 3, 4]))
print(np.var([1, 2, 3, 4]))
a = np.array([[3, 7], [9, 1]])
print(np.sort(a)) #把每一行进行排序
print(np.sort(a, axis=0)) #把每一列拿出来进行排序
dt = np.dtype([('name', 'S10'), ('age', int)])
a = np.array([("raju", 21), ("anil", 25),
("ravi", 17), ("amar", 27)], dtype=dt)
print(np.sort(a, order='name')) #根据列名来排序
x = np.array([3, 1, 2])
y = np.argsort(x) #或者排序后的索引
nm = [3,3,2,8,1,9]
dv = [27,1,17,6,37,4]
ind = np.lexsort((dv, nm))#多级排序,先按 nm 进行排序,相同再按 dv,有电箱排序的第一关键字,第二关键字,返回索引
a = np.array([3, 4, 2, 5,10,11,8,6,4])
np.partition(a, 5) #分割,比位 3 的数字小的排前面,比它大的排后面
arr = np.array([46, 57, 23, 39, 1, 10, 0, 120])
arr.sort()
arr[np.argpartition(arr, 2)[2]] #找到数组的第 3 小(index=2)的值,速度快
arr[np.argpartition(arr, -2)[-2]] #找到数组第 2 大(index=-2)的值
a = np.array([[30, 40, 70], [80, 20, 10], [50, 90, 60]])
print(np.argmax(a)) #找到最大值对应的索引,矩阵按行优先
maxindex = np.argmax(a, axis=0)#把每一列的最大值找出来
maxindex = np.argmax(a, axis=1)#找出每一行的最大值
a = np.array([[30, 40, 0], [0, 20, 10], [50, 0, 60]])
print(np.nonzero(a)) #返回非零的元素的下标 x y 下标各一个向量
x = np.arange(9.).reshape(3, 3)
y = np.where(x > 3) #返回大于 3 的二维索引
print(x[y]) #找出大于 3 的数
x = np.arange(9.).reshape(3, 3)
condition = np.mod(x, 2) == 0
b = np.extract(condition, x) #同a = x[condition]
i = np.matrix('1,2;3,4') #字符串生成矩阵,有点诡异啊
print(i)
j = np.asarray(i)
print(j)
k = np.asmatrix(j)
print(k)
a = np.array([[1, 2], [3, 4]])
b = np.array([[11, 12], [13, 14]])
print(np.dot(a, b)) #矩阵点乘,同 a@b np.matmul(a, b)
print(np.vdot(a, b)) #计算内积,最后称为一个数
np.inner(np.array([1, 2, 3]), np.array([0, 1, 0])) #向量内积
a = np.array([[1, 2], [3, 4]])
np.linalg.det(a) #计算行列式
x = np.array([[1, 2], [3, 4]])
y = np.linalg.inv(x) #求逆
A = np.array([[1, 1, 1], [0, 2, 5], [2, 5, -1]])
b = np.array([[6], [-4], [27]])
x = np.linalg.solve(A, b) #求解 A^-1 @ b
x = np.arange(1, 11)
y = 2 * x**2 + 5
plt.title("Matplotlib demo")
plt.xlabel("x axis caption")
plt.ylabel("y axis caption")
plt.plot(x, y)
plt.show()
恭喜你,到这里,你的 python 已经入门了,下面就可以实操你的项目了。显然,你现在不能够完全记住它们,不过没关系,你可以把上述代码当成一个基础版新华字典,等到需要的时候,打开这个博客,快速地用眸子扫描,或者使用 Ctrl+F 进行关键字查询即可。
面向浏览器的编程
学习了基本数据结构和 numpy 的用法,不足以支撑你完成一个项目,但是你至少解决了你打开 IDE 不知道写点什么的窘境,因为至少你会写 import 了。
不系统学习的一个缺点就是,你不知道 “有哪些东西可用”。我们可以利用各个编辑器的智能补充提示和补充功能。你在每个对象后面打个点 “.”(或许有的 IDE 还要加个 Tab) 就会给你提示有哪些方法,基本上顾名思义你就知道这些函数干嘛用的,完全没必要去百度 “numpy 怎么样 xxxxxx”、 “python 如何 xxxxxx” 之类的。如下
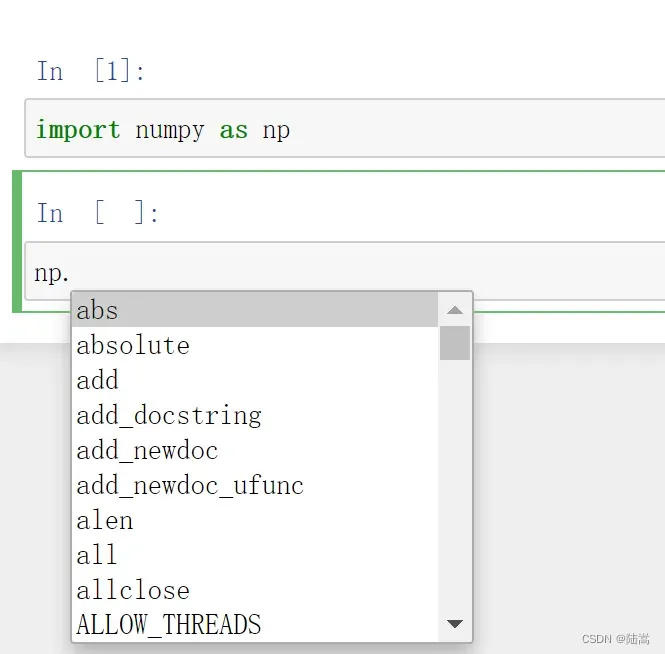
过 “.” 提示,得知了哪个函数方法可以实现你的操作,辅以 IDE 的函数接口提示,连蒙带猜地你就能把这个语句写下来了。 doc 帮助似乎看不懂的时候,你就可以去 GOOGLE 或者 Baidu 了。
类似地,遇到任何编程语言的现有工具解决不了的问题,都可以面向浏览器。需要提醒的是,面向浏览器的编程,需要你通过一定的思考,把问题精确地描述出来,否则,很可能找不到你想要的答案。对于搜索到的答案,也要认真思考是不是迎合你的问题,不要一股脑地瞎试。一般来说,对于抛出的错误,直接把错误提示复制到浏览器窗口搜索即可。
所谓孰能生巧,滴水穿铜孔。一个数据结构,比如 List,一个模块,比如 numpy,你可能一开始不熟悉,你在面向你要做的事情里反复地用,慢慢地就很熟悉了。
其他的学习
python 有很多东西,特别是海量的可以 import 的模块。这个你根据自己的需求去摸索既可以了。对于 pandas,你可以利用上述的方式,把它的基本模块过一遍,可以参考我的这篇博客:
其他资料我就不推荐了,因为有背于我我不推荐你进行系统学习的本意。如果真的不认同我这点想法,或者你的基础真的差到 IDE 安装都需要有个教程,那么你可以上菜鸟教程、慕课网、 B 站、github 等等上面找一些系统的视频或者文字教程看看,不反对,但是也不提倡。
你问我 IDE 用什么,人各有志,我就不推荐了,每个哈姆雷特都有能力把自己用过的 IDE 高高地举起来,然后前面加四个大字——强烈推荐。但是,既然你能来看我这些废话,我自然不会推荐你用 vim,无他,我觉得你用不好。语法学习的话,jupyter notebook 不错啊,反正就一点一点试一试。
文章出处登录后可见!