参考资料
GMM-HMM语音识别模型 原理篇
语音识别中的HMM-GMM模型:从一段语音说起
动态规划之隐含马尔可夫模型(HMM)和维特比算法(Viterbi Algorithm)
机器学习-隐马尔可夫模型算法
HMM——维特比算法(Viterbi algorithm)
动手搭建一个基于GMM-HMM的嵌入式命令词识别系统
b站视频
前言
一般分为“独立词”和“声韵母”两种,找了很多资料,看了一些公式推导,把整个算法流程大概梳理了一下
算法
- 数据集准备,标注,以及使用开源语音包将音节级别的标注转化到音素级别
- 特征提取,MFCC
- 构建HMM模型,一般为四状态
分别对应音素的前,中,后,结束,其中因为状态的自转化,可以让我们能够对连续语音建模,因为由于自转化,一个音素可以持续一段时间。
- 构建GMM混合高斯模型一般为3高斯
- 分帧,将帧平均分配给每一个状态,目的是为了初始化模型,因为模型初始化需要先进行对齐,才能统计数据,进而初始化模型。
- 此时,每一个
平均对应几个观测值,这里观测值是提取的MFCC特征,为了能够初始化GMM(三个高斯加权得到的)
三个参数,需要进行
聚成三类,然后分配给每一个GMM分量,分配好以后相应的权重跟平均值方差都可以计算出来也就是B发射概率矩阵,同样A转移概率矩阵也可以计算出来。
- 初始化模型后,就可以训练了,训练一般需要对参数进行修正,同样就需要对数据对齐,一般有两种一种是硬对齐(维比特算法),另一种是软对齐(前后项概率)。有啥区别,具体而言就是硬对齐是直接按照概率最大找了一组状态对齐观测值,这种是一一对齐的,而软对齐是根据概率乘特征向量对齐,一个特征可以分配到两个不同的状态上,不知道这种理解对不。//TODO:以后加深理解
- 通过新的对齐状态我们,我们可以重新计算,模型参数,有了新的模型参数又可以进行新的对齐,通过EM算法不断迭代,最终训练到收敛。
- 判断收敛可以利用维比特算法,比较相邻两次似然概率差值,小与某个数值,认为收敛。
- 有了模型,可以进行分类,即输入一段语音的特征,计算相似概率,选出概率最大的,就是语音对应的模型,进而得到语音内容
重点
- 维比特算法
- Gmm-Hmm模型
- 隐马尔科夫链及其假设
- 前后向算法
- EM算法
- MFCC特征提取的步骤及其(D,T)代表的意义
- 正则化
- 观测值与状态值的对齐
- 参数更新的步骤
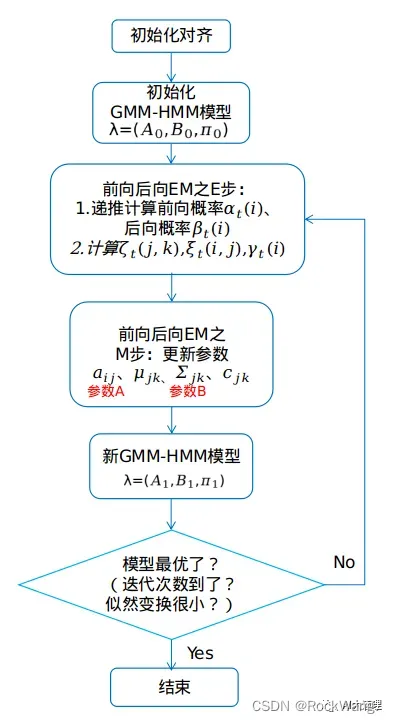
这张图片挺清晰的,文章也不错可以看一下。
程序源码,可以看参考文献倒数第二篇文献。
文章出处登录后可见!
已经登录?立即刷新