NVIDIA网站有一部分GPU编程系列的课程,具体的课程地址为:
https://www.nvidia.cn/developer/online-training/community-training/
以下为课程的部分记录笔记,仅供学习参考:
https://gg2ksnq1wg.feishu.cn/docs/doccnh2QtoPeGfUHR4eJIAvcGzd?from=from_copylink
课程中所涉及的代码:
https://github.com/jhzhang19/NVIDIA_CUDA_program.git
1、 利用CUDA实现卷积
这一部分cuda和OpenCV联合编译一直没有成功,可能是OpenCV需要安装cuda版本的,有测试成功的朋友欢迎交流。
#include"cuda_runtime.h"
#include<cudnn.h>
#include<cuda.h>
#include<device_functions.h>
#include<opencv4/opencv2/opencv.hpp>
#include<iostream>
using namespace std;
using namespace cv;
//定义卷积核(3x3 x input_channel x output_channel)
float3 data_kernel[] = {
make_float3(-1.0f, -1.0f, -1.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(1.0f, 1.0f, 1.0f),
make_float3(-2.0f, -2.0f, -2.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(2.0f, 2.0f, 2.0f),
make_float3(-1.0f, -1.0f, -1.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(1.0f, 1.0f, 1.0f),
make_float3(-1.0f, -1.0f, -1.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(1.0f, 1.0f, 1.0f),
make_float3(-2.0f, -2.0f, -2.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(2.0f, 2.0f, 2.0f),
make_float3(-1.0f, -1.0f, -1.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(1.0f, 1.0f, 1.0f),
make_float3(-1.0f, -1.0f, -1.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(1.0f, 1.0f, 1.0f),
make_float3(-2.0f, -2.0f, -2.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(2.0f, 2.0f, 2.0f),
make_float3(-1.0f, -1.0f, -1.0f), make_float3(0.0f, 0.0f, 0.0f), make_float3(1.0f, 1.0f, 1.0f),
};
int main(){
//利用opencv的接口读取图片相关信息
cv::Mat img = cv::imread("/home/zjh19/图片/00000.png");
int imgWidth = img.cols;
int imgHeight = img.rows;
int imgChannel = img.channels();
cv::Mat dst_gpu(imgHeight, imgWidth, CV_8UC3, cv::Scalar(0, 0, 0));
size_t num = imgChannel * imgHeight * imgWidth * sizeof(unsigned char);
// 1.在gpu上分配空间
unsigned char *in_gpu; //输入gpu的图像数据
unsigned char *out_gpu; //输出gpu的图像数据
float *filt_data;
cudaMalloc((void **)&filt_data, 3 * 3 * 3 * sizeof(float3));
cudaMalloc((void **)&in_gpu, num);
cudaMalloc((void **)*out_gpu, num);
// 2.初始化句柄
cudnnHandle_t handle;
cudnnCreate(&handle);
// 3.描述tensor
//input descriptor
cudnnTensorDescriptor_t input_descriptor;
cudnnCreateTensorDescriptor(&input_descriptor);
cudnnSetTensor4dDescriptor(input_descriptor, CUDNN_TENSOR_NHWC,
CUDNN_DATA_FLOAT, 1, 3, imgHeight, imgWidth);
//output descriptor
cudnnTensorDescriptor_t output_descriptor;
cudnnCreateTensorDescriptor(&output_descriptor);
cudnnSetTensor4dDescriptor(output_descriptor, CUDNN_TENSOR_NHWC,
CUDNN_DATA_FLOAT, 1, 3, imgHeight, imgWidth);
//kernel descriptor
cudnnFilterDescriptor_t kernel_descriptor;
cudnnCreateFilterDescriptor(&kernel_descriptor);
cudnnSetFilter4dDescriptor(kernel_descriptor, CUDNN_DATA_FLOAT,
CUDNN_TENSOR_NCHW, 3, 3, 3, 3);
// 4.描述操作并设置相关参数
cudnnConvolutionDescriptor_t conv_descriptor;
cudnnCreateConvolutionDescriptor(&conv_descriptor);
cudnnSetConvolution2dDescriptor(conv_descriptor, 1, 1, 1, 1, 1, 1,
CUDNN_CROSS_CORRELATION, CUDNN_DATA_FLOAT);
// 5.描述算法,让计算机自动选择最佳算法
cudnnConvolutionFwdAlgoPerf_t algo;
cudnnGetConvolutionForwardAlgorithm_v7(handle, input_descriptor, kernel_descriptor,
conv_descriptor, output_descriptor, 1, 0, &algo);
// 6.申请工作空间
size_t workspace_size = 0;
//计算工作空间大小
cudnnGetConvolutionForwardWorkspaceSize(handle, input_descriptor, kernel_descriptor, conv_descriptor, output_descriptor, algo.algo, &workspace_size);
//分配工作空间
void *workspace = nullptr;
cudaMalloc(&workspace, workspace_size);
// 7.将计算需要的数据传输到GPU
cudaMemcpy((void *)filt_data, (void *)data_kernel, 3 * 3 * 3 * sizeof(float3), cudaMemcpyHostToDevice);
cudaMemcpy(in_gpu, img.data, num, cudaMemcpyHostToDevice);
// 8.开始计算
auto alpha = 1.0f, beta = 0.0f;
cudnnConvolutionForward(handle, &alpha, input_descriptor, in_gpu,
kernel_descriptor, filt_data, conv_descriptor, algo.algo, &workspace, workspace_size, &beta, output_descriptor, out_gpu);
// 9.将计算结果回传到CPU
cudaMemcpy(dst_gpu.data, out_gpu, num, cudaMemcpyDeviceToHost);
// 10.释放资源
cudaFree(in_gpu);
cudaFree(out_gpu);
cudaFree(workspace);
cudnnDestroyTensorDescriptor(input_descriptor);
cudnnDestroyTensorDescriptor(output_descriptor);
cudnnDestroyFilterDescriptor(kernel_descriptor);
cudnnDestroyConvolutionDescriptor(conv_descriptor);
cudnnDestroy(handle);
return 0;
}
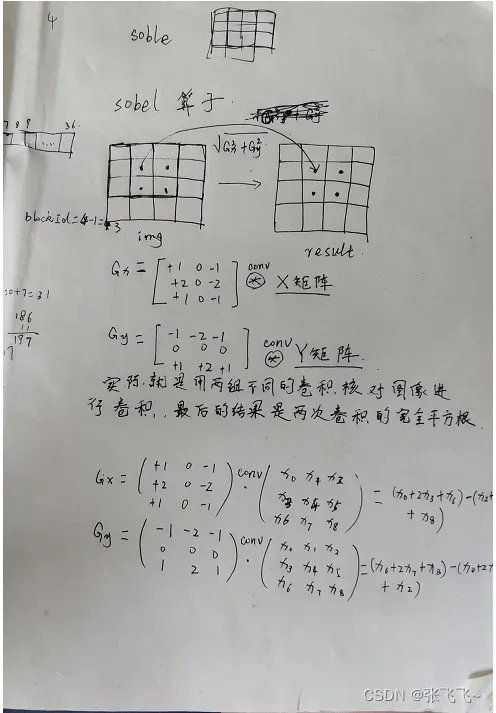
2、CUDA实现sobel边缘检测算子
#include<cuda.h>
#include<cudnn.h>
#include<cuda_runtime.h>
#include<opencv2/opencv.hpp>
#include<device_functions.h>
#include<iostream>
using namespace std;
using namespace cv;
//cpu实现边沿检测
void sobel_cpu(Mat srcImg, Mat dstImg, int imgHeight, int imgWidth){
}
//gpu实现sobel边沿检测
//3x3卷积核元素定义
// x0 x1 x2
// x3 x4 x5
// x6 x7 x8
__global__ void sobel_gpu(unsigned char* in, unsigned char* out, int imgHeight, int imgWidth){
int x = threadIdx.x + blockDim.x * blockIdx.x;
int y = threadIdx.y + blockDim.y * blockIdx.y;
int index = y * imgWidth + x;
int Gx = 0;
int Gy = 0;
unsigned char x0, x1, x2, x3, x4, x5, x6, x7, x8;
//没有在边缘进行padding,所以没有考虑图像边界处的像素,而且对于边界检测图像边缘一圈的像素
// 对其影响不大
if(x>0 && x<imgWidth && y>0 && y<imgHeight){
x0 = in[(y - 1) * imgWidth + x - 1];//以x4为中心的左上角元素
x1= in[(y - 1) * imgWidth + x ]; //上方元素
x2= in[(y - 1) * imgWidth + x + 1 ]; //右上
x3= in[y * imgWidth + x - 1 ]; //左
x4= in[y * imgWidth + x ]; //x4
x5= in[y * imgWidth + x + 1]; //右
x6= in[(y + 1) * imgWidth + x - 1 ]; //左下
x7= in[(y + 1) * imgWidth + x ]; //下
x8= in[(y + 1) * imgWidth + x + 1 ]; //右下
Gx = x0 + 2 * x3 + x6 - (x2 + 2 * x5 + x8); //x轴边界卷积核卷积操作
Gy = x6 + 2 * x7 + x8 - (x0 + 2 * x1 + x2); //y轴边界卷积核卷积操作
out[index] = (abs(Gx) + abs(Gy)) / 2; //输出结果,采用简化算法(|gx|+|gy|)/2
}
}
int main(){
//利用opencv接口读取图片
Mat grayImg = imread("1.jpg", 0);
int imgWidth = grayImg.cols;
int imgHeight = grayImg.rows;
//利用opencv对读取的图片进行去噪处理
Mat gaussImg;
GaussianBlur(grayImg, gaussImg, Size(3, 3), 0, 0, BORDER_DEFAULT);
//cpu结果为dst_cpu,gpu结果为dst_gpu
Mat dst_cpu(imgHeight, imgWidth, CV_8UC1, Scalar(0));
Mat dst_gpu(imgHeight, imgWidth, CV_8UC1, Scalar(0));
//调用sobel_cpu处理图像
sobel_cpu(gaussImg, dst_cpu, imgHeight, imgWidth);
//申请指针将它指向gpu空间
size_t num = imgHeight * imgWidth * sizeof(unsigned char);
unsigned char *in_gpu;
unsigned char *out_gpu;
cudaMalloc((void **)&in_gpu, num);
cudaMalloc((void **)&out_gpu, num);
//定义grid和block的维度
dim3 threadsPerBlock(32, 32);
dim3 blocksPerGrid((imgWidth + threadsPerBlock.x - 1) / threadsPerBlock.x,
(imgHeight + threadsPerBlock.y - 1) / threadsPerBlock.y);
//将数据从CPU传输到gpu
cudaMemcpy(in_gpu, gaussImg.data, num, cudaMemcpyHostToDevice);
//调用在gpu上运行的核函数
sobel_gpu<<<blocksPerGrid, threadsPerBlock>>>(in_gpu, out_gpu, imgHeight, imgWidth);
//将计算结果回传到CPU内存
cudaMemcpy(dst_gpu.data, out_gpu, num, cudaMemcpyDeviceToHost);
//显示处理结果
imshow("gpu", dst_gpu);
imshow("cpu", dst_cpu);
waitKey(0);
//释放gpu内存空间
cudaFree(in_gpu);
cudaFree(out_gpu);
return 0;
}
3、CUDA多流操作(锁页内存)
single stream
#include<stdio.h>
#include<iostream>
#include<cuda.h>
#include<cudnn.h>
#include<cuda_runtime.h>
#include<device_functions.h>
using namespace std;
//(A+B)/2=C
#define N (1024*1024) //向量长度,每个流执行数据大小
#define FULL (N*20) //全部数据的大小
__global__ void kernel(int *a, int *b, int *c){
int idx = threadIdx.x + blockDim.x * blockIdx.x;
if(idx < N){
c[idx] = (a[idx] + b[idx]) / 2;
}
}
int main(){
//查询设备属性
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDeviceProperties(&prop, whichDevice);
if(!prop.deviceOverlap){
cout << "Device will not support overlap!" << endl;
return 0;
}
else{
cout<<prop.deviceOverlap<<" yes"<<endl;
}
//初始化计时器时间
cudaEvent_t start, stop;
float elapsedTime;
//声明流和Buffer指针
cudaStream_t stream;
int *host_a, *host_b, *host_c;
int *dev_a, *dev_b, *dev_c;
//创建计时器
cudaEventCreate(&start);
cudaEventCreate(&stop);
//初始化流
cudaStreamCreate(&stream);
//在GPU端申请内存空间
cudaMalloc((void **)&dev_a, N * sizeof(int));
cudaMalloc((void **)&dev_b, N * sizeof(int));
cudaMalloc((void **)&dev_c, N * sizeof(int));
//在CPU端申请内存空间,要使用锁页内存
cudaHostAlloc((void **)&host_a, FULL * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void **)&host_b, FULL * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void **)&host_c, FULL * sizeof(int), cudaHostAllocDefault);
//初始化A,B向量
for (int i = 0; i < FULL;i++){
host_a[i] = rand();
host_b[i] = rand();
}
//single stream开始计算
cudaEventRecord(start, 0);
//每次传输计算长度为N的数据
for (int i = 0; i < FULL;i+=N){
//传输数据到device,并进行计算
cudaMemcpyAsync(dev_a, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
cudaMemcpyAsync(dev_b, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream);
kernel<<<N / 256, 256, 0, stream>>>(dev_a, dev_b, dev_c);
//将计算结果从GPU传输到CPU
cudaMemcpyAsync(host_c + i, dev_c, N * sizeof(int), cudaMemcpyDeviceToHost, stream);
}
//最后需要同步流
cudaStreamSynchronize(stream);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cout << "Single Time is:" << float(elapsedTime) << " s" << endl;
//释放内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaStreamDestroy(stream);
return 0;
}
multi stream
#include<stdio.h>
#include<iostream>
#include<cuda.h>
#include<cudnn.h>
#include<cuda_runtime.h>
#include<device_functions.h>
using namespace std;
//(A+B)/2=C
#define N (1024*1024) //向量长度,每个流执行数据大小
#define FULL (N*20) //全部数据的大小
__global__ void kernel(int *a, int *b, int *c){
int idx = threadIdx.x + blockDim.x * blockIdx.x;
if(idx < N){
c[idx] = (a[idx] + b[idx]) / 2;
}
}
int main(){
//查询设备属性
cudaDeviceProp prop;
int whichDevice;
cudaGetDevice(&whichDevice);
cudaGetDeviceProperties(&prop, whichDevice);
if(!prop.deviceOverlap){
cout << "Device will not support overlap!" << endl;
return 0;
}
else{
cout<<prop.deviceOverlap<<" yes"<<endl;
}
//初始化计时器时间
cudaEvent_t start, stop;
float elapsedTime;
//声明流和Buffer指针
cudaStream_t stream0;
cudaStream_t stream1;
int *host_a, *host_b, *host_c;
int *dev_a0, *dev_b0, *dev_c0;
int *dev_a1, *dev_b1, *dev_c1;
//创建计时器
cudaEventCreate(&start);
cudaEventCreate(&stop);
//初始化流
cudaStreamCreate(&stream0);
cudaStreamCreate(&stream1);
//在GPU端申请内存空间
cudaMalloc((void **)&dev_a0, N * sizeof(int));
cudaMalloc((void **)&dev_b0, N * sizeof(int));
cudaMalloc((void **)&dev_c0, N * sizeof(int));
cudaMalloc((void **)&dev_a1, N * sizeof(int));
cudaMalloc((void **)&dev_b1, N * sizeof(int));
cudaMalloc((void **)&dev_c1, N * sizeof(int));
//在CPU端申请内存空间,要使用锁页内存
cudaHostAlloc((void **)&host_a, FULL * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void **)&host_b, FULL * sizeof(int), cudaHostAllocDefault);
cudaHostAlloc((void **)&host_c, FULL * sizeof(int), cudaHostAllocDefault);
//初始化A,B向量
for (int i = 0; i < FULL;i++){
host_a[i] = rand();
host_b[i] = rand();
}
//single stream开始计算
cudaEventRecord(start, 0);
//每次传输计算长度为2*N的数据(两个流,所以是2N)
for (int i = 0; i < FULL;i+=2*N){
//传输数据到device,并进行计算
cudaMemcpyAsync(dev_a0, host_a + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_a1, host_a + i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1);
cudaMemcpyAsync(dev_b0, host_b + i, N * sizeof(int), cudaMemcpyHostToDevice, stream0);
cudaMemcpyAsync(dev_b1, host_b + i+N, N * sizeof(int), cudaMemcpyHostToDevice, stream1);
kernel<<<N / 256, 256, 0, stream0>>>(dev_a0, dev_b0, dev_c0);
kernel<<<N / 256, 256, 0, stream1>>>(dev_a1, dev_b1, dev_c1);
//将计算结果从GPU传输到CPU
cudaMemcpyAsync(host_c + i, dev_c0, N * sizeof(int), cudaMemcpyDeviceToHost, stream0);
cudaMemcpyAsync(host_c + i+N, dev_c1, N * sizeof(int), cudaMemcpyDeviceToHost, stream1);
}
//最后需要同步流
cudaStreamSynchronize(stream0);
cudaStreamSynchronize(stream1);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
cudaEventElapsedTime(&elapsedTime, start, stop);
cout << "Multi Time is:" << float(elapsedTime) << " s" << endl;
//释放内存
cudaFree(dev_a0);
cudaFree(dev_b0);
cudaFree(dev_c0);
cudaFree(dev_a1);
cudaFree(dev_b1);
cudaFree(dev_c1);
cudaFreeHost(host_a);
cudaFreeHost(host_b);
cudaFreeHost(host_c);
cudaStreamDestroy(stream0);
cudaStreamDestroy(stream1);
return 0;
}
4、CUDA-python 图片处理
对图片像素值进行操作
import imp
import cv2 as cv
# print(cv.__version__)
import numpy as np
import numba
from numba import cuda
import time
import math
@cuda.jit #标注为gpu执行
def process_gpu(img, channels):
#计算线程在全局数据下的索引
tx = cuda.blockIdx.x * cuda.blockDim.x + cuda.threadIdx.x
ty = cuda.blockIdx.y * cuda.blockDim.y + cuda.threadIdx.y
for c in range (channels):
color = img[tx, ty][c] * 2.0 + 30.0 #每个通道的像素值都增大
#对像素范围进行限定
if color > 255:
img[tx, ty][c] = 255
elif color < 0:
img[tx, ty][c] = 0
else:
img[tx, ty][c] = color
def process_cpu(img, dst):
rows, cols, channels = img.shape
for i in range(rows):
for j in range(cols):
for c in range(channels):
color = img[i, j][c] * 2.0 + 30.0
if color > 255:
dst[i, j][c] = 255
elif color < 0:
dst[i, j][c] = 0
else:
dst[i, j][c] = color
if __name__ == "__main__":
#载入图片
img = cv.imread("test.png")
#读取图片像素行列信息
rows, clos, channels = img.shape
#cpu,gpu处理的数据
dst_cpu = img.copy()
dst_gpu = img.copy()
#调用函数进行处理
#gpu处理
dImg = cuda.to_device(img) #将图片数据拷贝到device上
#设置线程/block数量
threadsperblock = (16, 16) #数量为16倍数,最大不超过显卡限制
blockspergrid_x = int(math.ceil(rows/threadsperblock[0])) #往上取整是为了让线程覆盖所有图像像素,防止遗漏像素,block个数是32的倍数
blockspergrid_y = int(math.ceil(clos/threadsperblock[1]))
blockspergrid = (blockspergrid_x, blockspergrid_y)
#同步一下cpu和device的计算进度
cuda.synchronize()
#gpu处理时间
print("GPU processing:")
start_gpu = time.time()
process_gpu[blockspergrid, threadsperblock](dImg, channels)
cuda.synchronize()
end_gpu = time.time()
time_gpu = end_gpu - start_gpu
dst_gpu = dImg.copy_to_host()
print("GPU process time is: " + str(time_gpu) + "s")
#cpu处理
print("CPU processing:")
start_cpu = time.time()
process_cpu(img, dst_cpu)
end_cpu = time.time()
time_cpu = end_cpu - start_cpu
print("CPU process time is: "+ str(time_cpu) + "s")
#保存处理结果
cv.imwrite("result_cpu.png", dst_cpu)
cv.imwrite("result_gpu.png", dst_gpu)
print("Process Done!")
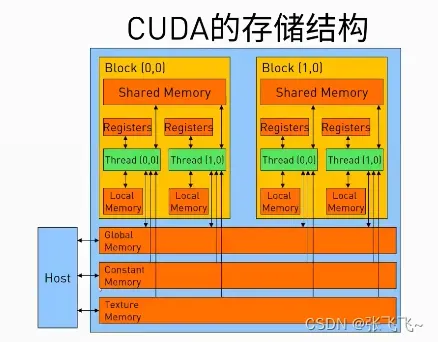
5.CUDA python 内存操作
矩阵相乘计算A*B=C,分别使用CPU、GPU共享内存、GPU全局内存进行计算存储,比较时间快慢。
import numba
from numba import cuda
import math
import numpy as np
import time
#每个block里的thread数量
TPB = 16
@numba.jit(nopython=True) #使用numba加速cpu处理
def matmul_cpu(A, B, C):
for y in range(B.shape[1]):
for x in range(A.shape[0]):
tmp = 0.
for k in range(A.shape[1]):
tmp = A[x,k] * B[k, y] #矩阵A的第x行与矩阵B的第y列逐元素相乘累加
C[x, y] = tmp
@cuda.jit
def matmul_gpu(A, B, C):
row, col = cuda.grid(2) #当前线程在grid中的索引
if row<C.shape[0] and col < C.shape[1]:
tmp = 0.
for k in range(A.shape[1]):
tmp += A[row, k] * B[k, col]
C[row, col] = tmp
@cuda.jit
def matmul_shared_mem(A, B, C):
#每次利用shared memory 读取一部分数据
sA = cuda.shared.array(shape=(TPB, TPB), dtype=numba.float32)
sB = cuda.shared.array(shape=(TPB, TPB), dtype=numba.float32)
x, y = cuda.grid(2) #当前线程在grid中的block索引
tx = cuda.threadIdx.x
ty = cuda.threadIdx.y
if x >=C.shape[0] and y <= C.shape[1]:
return
tmp = 0.
for i in range(int(A.shape[1]/TPB)):
sA[tx, ty] = A[x, ty+i*TPB] #每次读取矩阵A中TPB长度的一行
sB[tx, ty] = B[tx+i*TPB, y] #每次读取矩阵B中TPB长度的一列
cuda.syncthreads() #此处是同步线程
for j in range(TPB):
#计算两个子矩阵相乘
tmp += sA[tx, j] * sB[j, ty]
cuda.syncthreads()
C[x, y] = tmp
#输入数据
A = np.full((TPB*500, TPB*500), 3, np.float)
B = np.full((TPB*500, TPB*500), 4, np.float)
#输出结果 A*B=C
C_cpu = np.full((A.shape[0], B.shape[1]), 0, np.float)
#CPU 处理计时
print("Start processing in CPU")
start_cpu = time.time()
matmul_cpu(A, B, C_cpu)
end_cpu = time.time()
time_cpu = end_cpu - start_cpu
print("CPU process time is: "+ str(time_cpu)+" s")
#GPU处理
#数据传输到gpu上
A_global_mem = cuda.to_device(A)
B_global_mem = cuda.to_device(B)
C_global_mem = cuda.device_array((A.shape[0], B.shape[1]))
C_shared_mem = cuda.device_array((A.shape[0], B.shape[1]))
threadsperblock = (TPB, TPB)
blockspergrid_x = int(math.ceil(A.shape[0]/threadsperblock[0]))
blockspergrid_y = int(math.ceil(B.shape[1]/threadsperblock[1]))
blockspergrid = (blockspergrid_x, blockspergrid_y)
# gpu_global_memory处理计时
print("GPU processing")
start_gpu = time.time()
matmul_gpu[blockspergrid, threadsperblock](A_global_mem, B_global_mem, C_global_mem)
cuda.synchronize()
end_gpu = time.time()
time_gpu = end_gpu - start_gpu
C_global_gpu = C_global_mem.copy_to_host() #传回host
print("GPU time is: "+str(time_gpu)+" s")
#gpu_shared_memory处理计时
start_gpu_shared = time.time()
matmul_shared_mem[blockspergrid, threadsperblock](A_global_mem, B_global_mem, C_shared_mem)
cuda.synchronize()
end_gpu_shared = time.time()
time_gpu_shared = end_gpu_shared - start_gpu_shared
print("GPU time(shared memory) is: " + str(time_gpu_shared) + " s")
C_shared_gpu = C_shared_mem.copy_to_host()
文章出处登录后可见!
已经登录?立即刷新