前言:
笔者发现csdn上关于从头到尾逐个模块复现yolov1的代码资源较少,大多只谈论yolov1的思想,而新入手的小白(比如笔者)很多代码细节并不明白,也不知道从那里找到资源学习,所以写下这篇文章,希望能够帮助克服苦难。
整篇文章主要目的是记录新手在复现yolov1过程中遇到的主要问题,解决代码问题。如果想阅读本篇文章,前提要已经明白yolov1的运行过程,最好已经看过论文中具体的细节部分。
事先说明:
实现细节:笔者的实现细节与实际论文稍有出入,总体思想基本保持相同。
运行平台:kaggle,白嫖每周30h的GPU。
数据集:kaggle页面的add data处直接搜索voc数据集,然后直接添加进即可
编程语言以及第三方包:Python, Keras+numpy+matplotlib+opencv+pandas。主要是Keras与numpy;opencv只用于读图像,标注图像;matplotliab只用于显示图像;pandas几乎没用到。
在kaggle平台上已经安装好了,可以直接import,无需担心版本问题!!!
不足:由于是在kaggle平台运行的RAM资源有限,无法将5000张图片全部读入。以复现论文为目的,笔者将训练集前601张图片取出来训练,其余数据集用来测试看一看效果,确保方向正确,下面的训练时间也都是基于601张图片而言。
代码:因为笔者赶时间,所以代码写的较乱,如果真的有需要,可以私信发。
资料:
tensorflow官方文档,查API的指定地点
keras官方文档,有中文文档
stackoverflow,很多问题在这里可以得到回答
VOC数据集读取
voc数据集的文件结构:
文件结构
└── VOCdevkit #根目录
└── VOC2012 #不同年份的数据集,这里只下载了2012的,还有2007等其它年份的
├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等
├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本
│ ├── Action
│ ├── Layout
│ ├── Main
│ └── Segmentation
├── JPEGImages #存放源图片
├── SegmentationClass #存放的是图片,语义分割相关
└── SegmentationObject #存放的是图片,实例分割相关
以voc2007为例,取出第一个Annotations 的第一个xml文件:

yolov1做的是目标检测只需要object下的内容,而segmented中是用于图像分割的内容,这一部分我们并不需要。接下来就是如何提取出object的信息。
python中通常有两种方式来读取xml文件:
参考🔗1
参考🔗2
-
xml.sas
sas是读取xml文件的简单接口。在遇到Tag时会调用回调函数startElement告知查到一个Tag。然后遇到中间内容又会自动调用content函数。最后调用endElement函数告知到之前的Tag已经结束了。不同的阶段都留出来api供你处理。
好处在于:如果提取的信息不多,可以一个Tag一个Tag的列举出来,依次处理。
坏处在于:如果想获取的数据有结构,比如voc数据集中Box的4个值应该是一起存储的,还有如果遇到想要获取很多标签的情况,那么就很难全部列举出来,这时候就应该使用dom。 -
xml.dom
dom将整个xml文件以树的形式存储,这样既保留数据信息,还保留了层级结构信息,非常合理。以上面这张图为例,dom当中提供api,你可以指定你现在想要的根节点是什么,比如我们现在指定根节点为object,它就会把object下面所有的内容全部给我们提出来(注意:VOC数据集中有的xml文件里如果包含图像分割信息的话,object下面会多出一个part的子节点,一定要记得处理这种情况)。
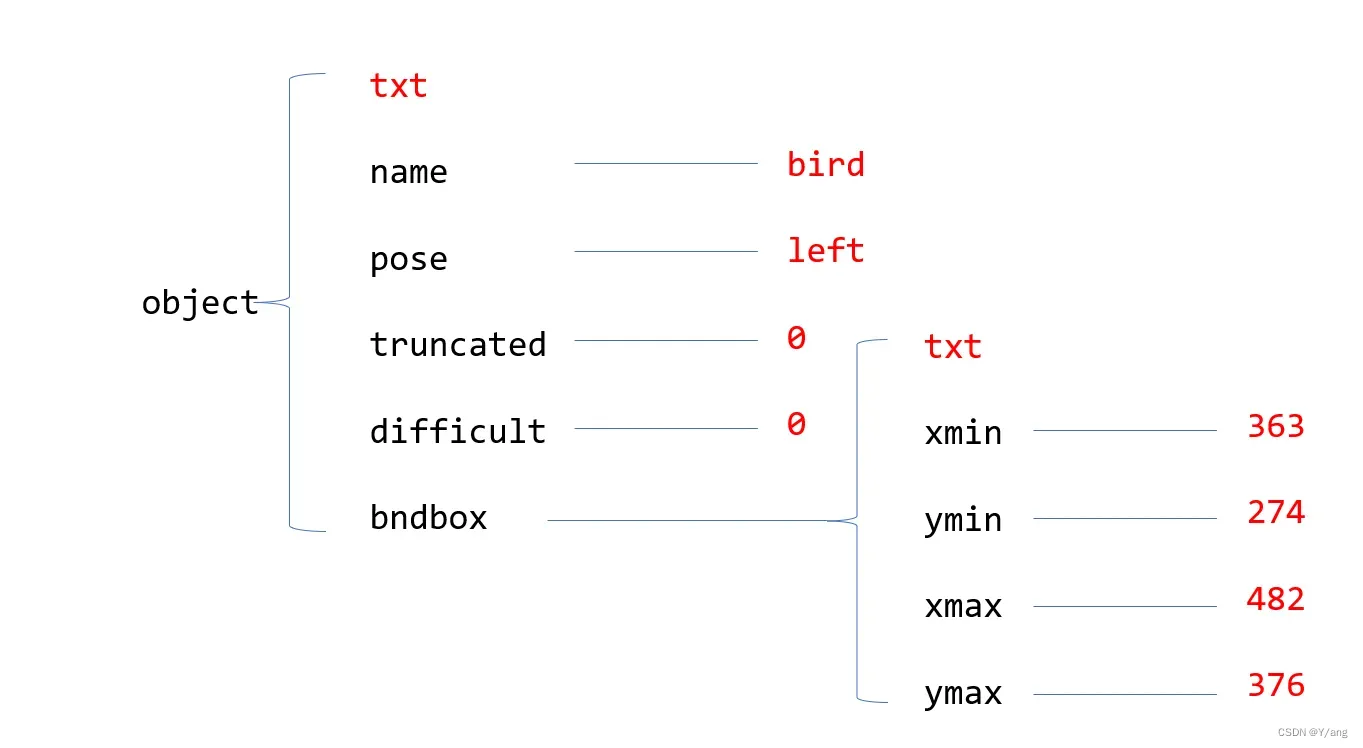
说明: -
图中标红色的为叶节点,txt是指一些无关的文本信息,比如换行符。
-
排除txt节点,提取有用节点的方法:
以Object为一级节点,查询object的子节点(即二级节点)的子节点数目,若为0则txt叶节点,若不为0(图中的name等节点,在本例中实际上都为1),则为有用的信息,我们想要提取该节点的子节点信息,可以使用label_node.childNodes[0].data。对于bndbox节点,我们可以在处理它时(可以用localName查询到节点名字),将其设为一级节点,重复object节点的操作。(Todo:可以使用递归的方式来做到这一点,类似于扫描所有子文件夹和文件的功能,但是有点麻烦就偷懒了╥﹏╥…)。
代码:
def read_from_xml(xml_path):
data_list = [] # 图片信息
filename = [] # 对应的图片文件名
document_tree = xml.dom.minidom.parse(xml_path)
collection = document_tree.documentElement # 获取所有元素
#print(collection.toxml())
filename_nodes=document_tree.getElementsByTagName("filename")
filename=filename_nodes[0].childNodes[0].data
object_nodes = document_tree.getElementsByTagName("object")
#print(object_nodes.length)
data_list.append(object_nodes.length) # 图片中object的数量
for object_node in object_nodes: # 遍历object父节点
for label_node in object_node.childNodes: # 遍历object下的一级节点
if(label_node.childNodes.length != 0): # 去除一级文本节点
if(label_node.localName != 'bndbox' and label_node.localName != 'part'): # 非bndbox节点直接输出信息
#print(label_node.childNodes[0].data)
data_list.append(label_node.childNodes[0].data)
elif(label_node.localName=='bndbox'): # 针对bndbox节点,处理二级节点
box_node=label_node # bndbox节点接管为一级节点
for box_feature_node in box_node.childNodes: # 遍历bndbox下的一级点节点
if(box_feature_node.childNodes.length != 0): # 去除一级文本节点
#print(box_feature_node.childNodes[0].data)
data_list.append(box_feature_node.childNodes[0].data)
return filename,data_list
对第一个label测试结果:
filename=008753.jpg
datalist=[1, 'bird', 'Left', '0', '0', '363', '274', '482', '367']
通过以上方式能够将voc2007下面的5000(虚数)张图片的标签全部读出来,并且于图片配对上。放在一个[[img0,label0], [img1,label1],...[imgn,labeln]]的list中存储起来。
图片编码与解码
图片编码的内容只有在理解论文的基础上才能做出来,建议看论文,此处只提出注意事项。
是针对grid cell而言的。将图片分为7*7的方框,每个grid cell 长宽为1时,
是针对整张图片而言的。整张图片长宽看作1,
明白图像编码之后,对于图像解码的问题自然会明白很多,但也有注意点。
- 因为有两个置信度,我们会选取置信度最大的那一个,抛弃置信度小的那一个。所以最后画出来的框,也会用的是置信度最大的那一个里面的
# 编码代码
def encoder(boxes,label):
global grid_num
target=np.zeros((grid_num,grid_num,30))
#print('boxes:\n{0}'.format((boxes)))
# 计算宽高
wh=boxes[:,2:]-boxes[:,:2]
# 计算中心点
x_center=((boxes[:,0]+boxes[:,2])/2).reshape(-1,1)
y_center=((boxes[:,1]+boxes[:,3])/2).reshape(-1,1)
cxcy=np.hstack((x_center,y_center))
cxcy=(boxes[:,2:]+boxes[:,:2])/2
for i in range(boxes.shape[0]):
cxcy_sample=cxcy[i]
ij=np.ceil((cxcy_sample*grid_num))-1
#print(ij)
target[int(ij[1]),int(ij[0]),4]=1
target[int(ij[1]),int(ij[0]),9]=1
target[int(ij[1]),int(ij[0]),int(9+label[i])]=1
xy=ij/grid_num
delta_xy=(cxcy_sample-xy)*grid_num
target[int(ij[1]),int(ij[0]),2:4]=wh[i]
target[int(ij[1]),int(ij[0]),7:9]=wh[i]
target[int(ij[1]),int(ij[0]),:2]=delta_xy
target[int(ij[1]),int(ij[0]),5:7]=delta_xy
return target
# 解码代码
columns=['aeroplane', 'bicycle', 'bird', 'boat', 'bottle', 'bus', 'car', 'cat', 'chair', 'cow', 'diningtable', 'dog', 'horse', 'motorbike', 'person', 'pottedplant', 'sheep', 'sofa', 'train', 'tvmonitor']
classes_id=pd.Series([i for i in range(1,21)],index=columns) # 存储每个类对应的标号
def decode(target,img,print_flag=False):
# 解码功能:输出编码前的目标的实际(lx,ly,rx,ry)以及类别信息
global grid_num
global confidence_threshold
global nw
global nh
img_show=img.copy() # 不去修改原始数据
for i in range(grid_num): # 遍历x方向
for j in range(grid_num): # 遍历y方向
encode_inform=target[i,j]
confidence_max= max(encode_inform[4],encode_inform[9]) # 取置信度最高的框
if(confidence_max > confidence_threshold): # 判定是否大于置信度阈值
confidenc_max_ix=np.argmax([encode_inform[4],encode_inform[9]])
[deltax,deltay,w,h]=encode_inform[5*confidenc_max_ix+1-1:5*confidenc_max_ix+5-1]
# 获取网格坐标
gridx=int(nw/grid_num*j)
gridy=int(nh/grid_num*i)
# 求解实际x,y偏移量
scalex=int(nw/grid_num)
scaley=int(nh/grid_num)
deltax=int(deltax*scalex)
deltay=int(deltay*scaley)
# 求解中心坐标以及宽高
cx=gridx+deltax
cy=gridy+deltay
w=int(w*nw)
h=int(h*nh)
# 绘图代码
lx=int(cx-w/2)
ly=int(cy-h/2)
rx=int(cx+w/2)
ry=int(cy+h/2)
img_show=cv.rectangle(img_show,(lx,ly),(rx,ry),(255,0,0),1) # 添加方框
class_id=np.argmax(encode_inform[10:]) # 找出概率最大的类名
class_name=classes_id.index.tolist()[class_id]
cv.putText(img_show,class_name,(lx,ly-10),cv.FONT_HERSHEY_SIMPLEX, 0.5, (0,0,255)) # 添加文字
if(print_flag==True):
print((encode_inform[4],encode_inform[9]))
print(class_name)
plt.imshow(img_show[:,:,::-1])
模型搭建
笔者采用的网络backbone是ResNet18,将224*224的图片输入进去后,发现输出为14*14,所以直接在外面加了一层卷积使尺寸变为7*7*30直接输出。
注意:我这里犯了一件很傻的错误,我直接卷积输出没有激活,导致开始训练时输出结果有负数,也就是是负数,这显然是不可接受。从原理上来讲,只要损失函数设定的正确,一定会朝目标数值逼近的,最后一定是正数,但是忽略了一件事情:收敛时间。事实证明:如果不用激活函数sigmoid(我选择的是这个)很有可能用V100训练3小时都无法将loss降下去,而用sigmoid激活函数后1500个epoch之后loss降为0.6,最终收敛,时间只用了1小时。回想起,yolov1编码时候
都
,我感觉应该作者本意也是要用激活函数使得最后得输出分布在
之间的。
模型搭建代码:
class ResnetBlock(Model):
def __init__(self,filters,strides=1,residual_path=False):
super(ResnetBlock,self).__init__()
self.fliters=filters
self.strides=strides
self.residual_path=residual_path
self.c1=Conv2D(filters=filters,kernel_size=(3,3),strides=strides,padding='same',use_bias=False)
self.b1=BatchNormalization()
self.a1=tf.keras.layers.LeakyReLU(alpha=0.1)
self.c2=Conv2D(filters=filters,kernel_size=(3,3),strides=1,padding='same',use_bias=False)
self.b2=BatchNormalization()
if(residual_path):
self.down_c1=Conv2D(filters=filters,kernel_size=(1,1),strides=strides,padding='same',use_bias=False)
self.down_b1=BatchNormalization()
self.a2=tf.keras.layers.LeakyReLU(alpha=0.1)
def call(self,x):
x_shortcut=x
x=self.c1(x)
x=self.b1(x)
x=self.a1(x)
x=self.c2(x)
x=self.b2(x)
if(self.residual_path):
x_shortcut=self.down_c1(x_shortcut)
x_shortcut=self.down_b1(x_shortcut)
y=self.a2(x+x_shortcut)
return y
class yoloV1(Model):
def __init__(self,block_list,initial_filters=64):
super(yoloV1,self).__init__()
self.num_block=len(block_list)
self.block_list=block_list
self.out_filters=initial_filters
self.c1=Conv2D(initial_filters,kernel_size=(3,3),strides=(1,1),padding='same',use_bias=False,\
kernel_initializer='he_normal')
self.b1=BatchNormalization()
self.a1=tf.keras.layers.LeakyReLU(alpha=0.1)
self.blocks=tf.keras.models.Sequential()
for block_id in range(len(block_list)):
for layer_id in range(block_list[block_id]):
if(layer_id == 0):
block=ResnetBlock(filters=self.out_filters,strides=2,residual_path=True)
else:
block=ResnetBlock(filters=self.out_filters,strides=1,residual_path=False)
self.blocks.add(block)
self.out_filters *= 2
self.c2=Conv2D(filters=30,kernel_size=(3,3),strides=(2,2),padding='same')
self.a2=Activation('sigmoid')
def call(self,x):
x=self.c1(x)
x=self.b1(x)
x=self.a1(x)
x=self.blocks(x)
x=self.c2(x)
y=self.a2(x)
return y
损失函数
这是最让我头疼的地方,因为第一次使用自定义损失函数,很多tensorflow的特性之前并不会。
- 进入损失函数的
(y_pred, p_true)的size为(None, 7, 7, 30),所以计算loss时是计算的整个batch的loss,并不是计算单独一个样本的loss。 - tensorflow中是不允许创建一个variable类型的变量,然后计算一种类型的loss之后进行自加的,会出现error: …assignment这种分配错误。(这是我尝试的第一种方案)
- 网上用
tf.where(a,b,c)的方式也不适合这种复杂逻辑的损失函数。 - 使用mask才是最终的正确打开方式。笔者也是仿照一篇yolov1的损失函数的代码写出来的,但是源代码写的有点点复杂,参考他写掩码的做法,之后自己独立写了一份。
mask中元素是bool类型,代表的含义是满足条件为1,反之为0。
loss设计思想:将loss分解为4部分,然后对7*7grid都进行指定的损失函数计算,通过mask将满足条件的损失保留,不满足的置0,相当于没有计算这部分损失,最后全部相加,完成类似于带if…else的损失函数计算。
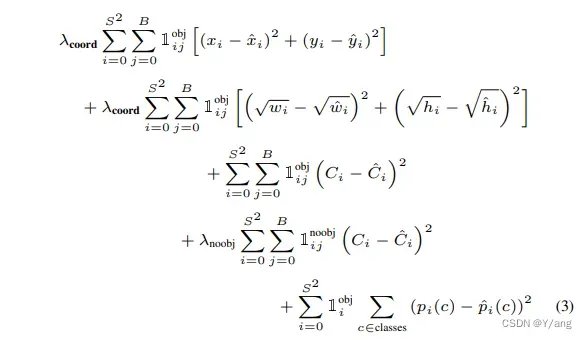
lambda_coord=10 # 原论文中为5
lambda_noobj=0.5
import keras.backend as K
def custom_loss(y_true, y_pred):
confidence1=y_pred[...,4]
confidence2=y_pred[...,9]
confidences=y_pred[...,4:10]
confidence_mask=tf.cast(confidence1 > confidence2,dtype=tf.float32) # 置信度掩码
confidence_mask = K.expand_dims(confidence_mask) # None*7*7*1
label_class=y_true[...,10:]
predict_class=y_pred[...,10:]
predict_xy1=y_pred[...,0:2]
predict_xy2=y_pred[...,5:7]
true_xy=y_true[...,0:2]
predict_wh1=K.sqrt(y_pred[...,2:4]+)
predict_wh2=K.sqrt(y_pred[...,7:9])
true_wh=K.sqrt(y_true[...,2:4])
response_mask=y_true[...,4] # 响应掩码
response_mask = K.expand_dims(response_mask)# None*7*7*1
nobj_loss=lambda_noobj*(1-response_mask)*K.square(K.max(confidences,axis=-1,keepdims=True)-0)
obj_loss=response_mask*K.square(1-K.max(confidences,axis=-1,keepdims=True))
confidence_loss = nobj_loss + obj_loss
confidence_loss = K.sum(confidence_loss)
class_loss=response_mask*K.square(label_class - predict_class)
class_loss = K.sum(class_loss)
xy_loss=response_mask*confidence_mask*K.square(true_xy-predict_xy1)+response_mask*(1-confidence_mask)*K.square(true_xy-predict_xy2)
wh_loss=response_mask*confidence_mask*K.square(true_wh-predict_wh1)+response_mask*(1-confidence_mask)*K.square(true_wh-predict_wh2)
box_loss=xy_loss+wh_loss
box_loss=K.sum(lambda_coord*box_loss)
loss = confidence_loss + class_loss + box_loss
return loss
训练以及保存模型过程
重点说一下模型保存的过程,因为创建模型的时候使用的是继承Model类创建子类的方式,所以正常的保存到HDF5文件的方法不能使用,模型保存后无法使用hdf文件复现。所以只能使用SavedModel格式保存。
训练的时候不要着急,只要整体趋势是下降的,哪怕有loss上升的时候都没关系。
官方文档关于模型保存的链接

# 训练代码
model=yoloV1([2,2,2,2])
model.compile(optimizer=tf.keras.optimizers.Adam(learning_rate=0.0001),loss=custom_loss)
history=model.fit(x=x_train,y=y_train,batch_size=64,epochs=1500)
因为笔者是在kaggle中训练的,所以使用!mkdir -p saved_model命令创建文件夹,笔者也是第一次发现,原来jupyter中也可以输入终端命令,只要在前面加上!即可。
#模型保存代码
model.save('saved_model/yolo_model')
model.summary()
# 绘制loss曲线
loss=history.history['loss']
plt.plot(loss)
输入新的图片查看效果如何
# 模型复用代码
new_model = tf.keras.models.load_model('saved_model/yolo_model',custom_objects={'custom_loss':custom_loss})
new_model.summary()
y_pred=new_model.predict(x_test[0:700])
ix=0
confidence_threshold=0.9
decode(y_pred[ix],x_test[ix])
最后是一些过程截图:
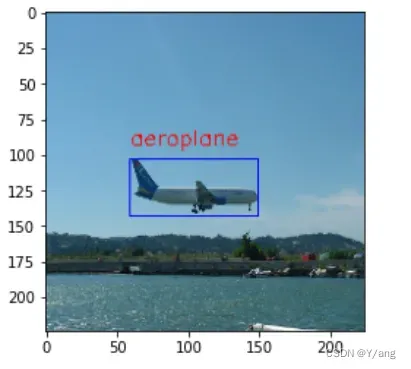
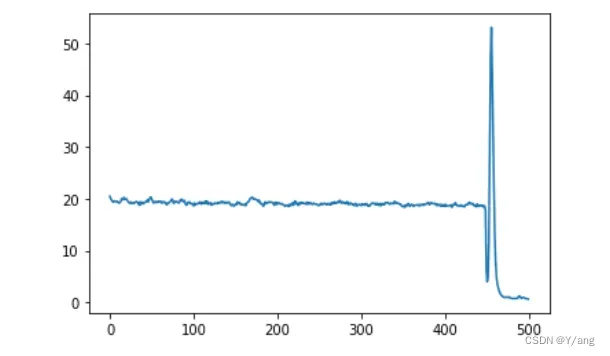
文章出处登录后可见!