摘要
本节主要讲述了batch和momentum,主要讲述为什么要用batch,通过对比讲述了batch大小的特点;通过物理例子引出momentum,讲述了以前的梯度下降和加上动量的梯度下降。
一、Batch
实际在做微分的时候不是对所有数据算出来的L算微分,是把所有的数据分成一个一个的batch,每次是拿一个batch里的资料计算gradient,然后更新参数,所有的batch看过一遍叫做一个epoch。把所有资料分成一个一个的batch的做法叫shuffle,在每一个epoch开始前会分一次batch,每个epoch的batch都不一样,如下图。
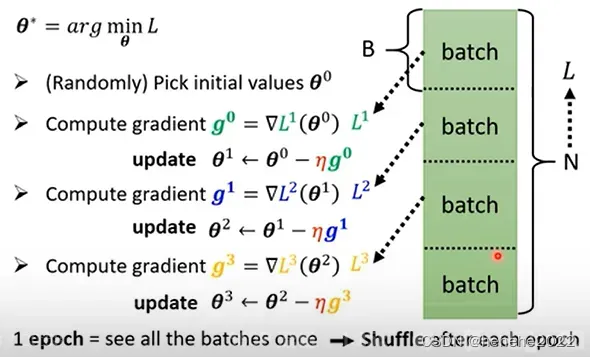
为什么要用batch?
假设有20笔训练资料,下图左边是没有用batch的,batch的大小为N(也叫Full batch);右边的batch的大小为1。在左边必须把所有的资料看完才能计算loss和gradient更新参数;右边每次更新只用看一笔资料就好了,在一个epoch中更新20次。
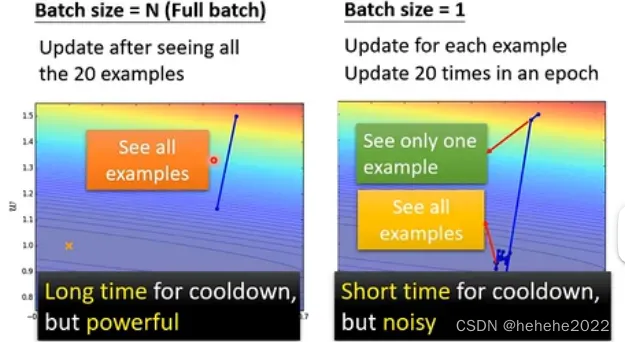
左右两边的对比:
左边蓄力的时间比较长,要看过所有的资料,右边蓄力的时间比较短;但实际上考虑平行运算的话,左边的不一定时间长。
下面是真正的实验结果,比较大的batch先算loss再算gradient不一定比batch小的化的时间长。
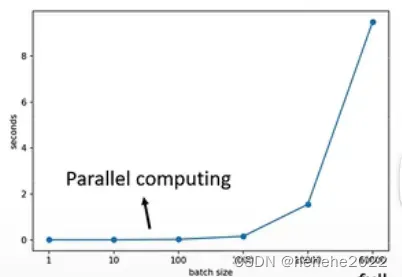
MNIST 手写数字辨识,给机器一张图片判断是0-9的哪个,做数字的分类。
上图横轴时batch的大小,纵轴时花费的时间;发现batch的大小从1-1000所花费的时间几乎是一样的,1000笔资料所花的时间并不是一笔资料的1000倍;但并行计算的能力也是有限的,在大小为10000-60000时可以看到花费的时间在增加。
因为有平行计算的能力,小的batch跑完一个epoch花的时间比大的batch size还要多。
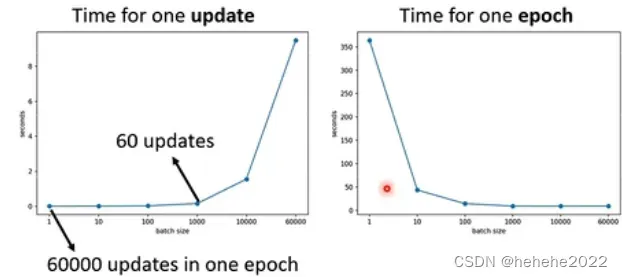
假设训练资料有60000笔,batch size为1,要更新60000次跑完一个epoch;batch size为1000,更新60次,gradient的时间差不多的话,60000次和60次时间差很大,下图左边是一个batch更新一次参数所要的时间,右边是跑完一个epoch花的时间。两个趋势正好相反,大的batch化的时间反而比较小。
noisy的gradient反而可以帮助训练,拿不同的batch训练模型,左边是作用在MNIST上,右边是作用在CIFAR-10上,横轴时batch size,纵轴代表正确率,越往上越高。可以看到batch size越大,正确率越低,可能时optimization的问题。
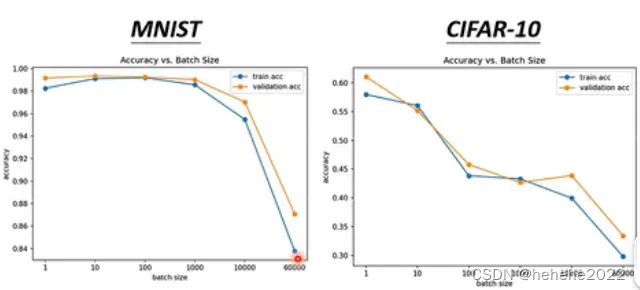
为什么小的batch size 在训练上会有好的结果?
假设时full batch ,在更新参数的时候是沿着loss函式更新参数,走到一个local minima或者saddle point停下来,用gradient descent没办法在更新参数;如果是small batch,每次挑一个batch出来算loss,每次更新参数用的loss函式是略有差异的,第一个batch用L1算gradient,第二个batch用L2算gradient,如果L1卡住了,L2不一定卡住,还可以继续训练,所以用noisy的batch训练比较好。
小的batch对测试数据也有帮助。
如下图,小的batch有256笔资料,大的batch是0.1x data set (60000笔),在大小batch都训练到差不多的training accuracy,但在testing accuracy上小的batch差,代表overfitting。
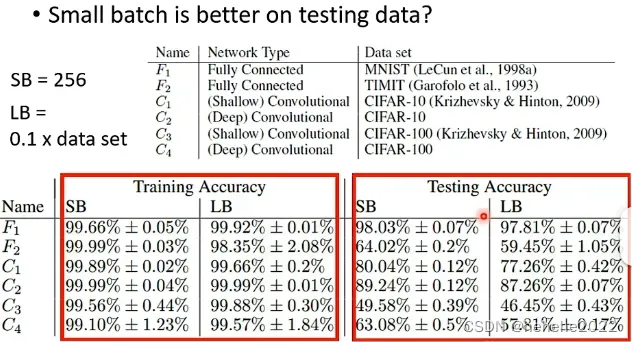
为什么出现上面的情况?
假设training loss是下图所示的,在training loss上可能有很多个local minima,这些local minima还是有好坏之分的,在峡谷里想右边的点那样就是好的minima,在平原上的点,像左边的点那样就是坏的minima,假设training loss和testing loss之间是有差距的,对左边的minima来说,他在training loss和testing loss上的结果不会差的太多,对右边的点来说就差很多了;部分人认为大的batch size会倾向于走到峡谷里面,小的倾向于走到盆地里面。
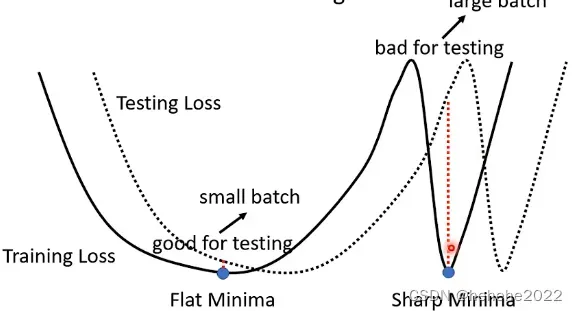
大小batch的比较:
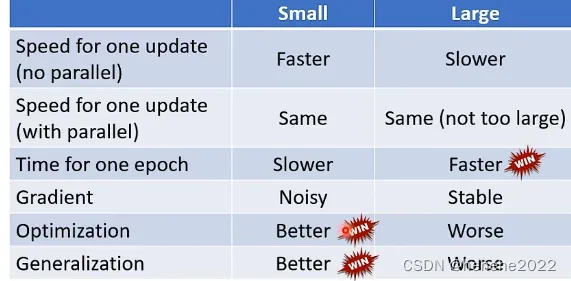
在没有平行运算的情况下,小的batch有效,大的计算时间较长;在有平行运算的情况下,大小batch的运算时间差不太多;但是一个epoch需要的时间,小的batch比较长,大的则更快;小的batch更新的方向比较noisy,大的则stable,noisy的更新方向反而在optimization和testing时会占到优势。
二、momentum
momentum的概念可以想象成是在物理的世界里,假设error surface就是一个斜坡,而参数就是一个球,把球从斜坡上滚下来,就算滚到了saddle point和local minima由于惯性还是会往前走,把这种概念运用到gradient descent中。
以前的gradient
找一个初始的⊖⁰,计算gradient g⁰,更新⊖¹,向gradient 的反方向移动参数。。。
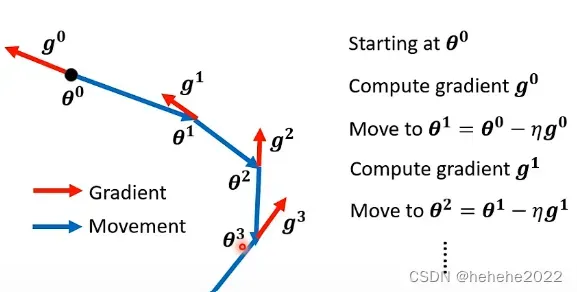
gradient descent+momentum
移动的方向是gradient加上前一步移动的方向,两者加起来的结果。
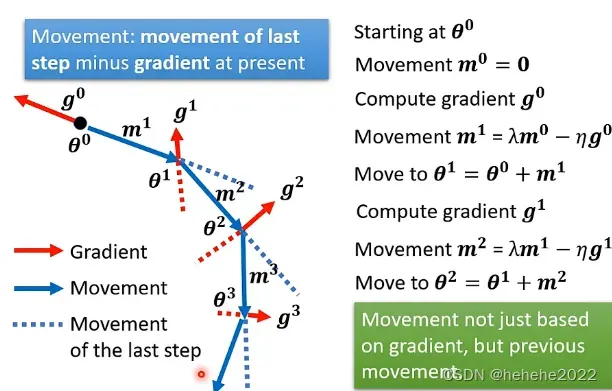
找一个初始的参数,刚开始的前一步的变化量设为0,在⊖⁰处计算g⁰,移动的方向是gradient加上前一步的方向,再计算g¹,新的更新方向是m²,移动的方向走⊖¹和m²的折中⊖²,以此类推。

可以就看出mi是所有gradient的weighted sum加权总和。
总结
小的batch和大的batch一次更新所花的时间差不多,但在平行计算时,由于大的batch更新的次数少,反而花的时间更少。动量在更新参数的时候考虑了之前的更新方向。
文章出处登录后可见!