



文@314896
0 基于 Transformer 复现的 13 种方法
Transformer 是 Google 的团队在 2017 年提出的一种经典模型,一诞生就席卷了 NLP 领域,被认为是当年 NLP 领域的年度最佳论文。
如今,Transformer 这把火已经烧到了计算机视觉领域,可以说成为今年最大的热点。本着全心全意为社区服务的精神,OpenMMLab 当然不会对此无动于衷。
为了方便大家研究学习,我们基于 MMCV 在 OpenMMLab 中 6 个方向的 repo 复现了 13 种基于 Transformer 的方法,快来看看有没有你需要的吧。
1 MMCV
GitHub地址:
我们在 MMCV 中实现了 FFN, MultiHeadAttention 等基本组件,以及 BaseTransformerLayer,TransformerLayerSequence 等基类,以增加代码复用性能。用户可以通过 Config 灵活的组合控制各个组件的结构,为了各个方向实现能够风格统一, 我们设计了一个统一的 data-flow,从而兼容各种各样的 Transformer 结构。
同时,对于 BaseTransformerLayer,我们允许通过指定 operation_order 来组合出各种各样的网络结构,并且其内置了ON LAYER NORMALIZATION IN THE TRANSFORMER ARCHITECTURE 中的pre norm 的功能,在operation_order 第一个为 norm 会自动启动。

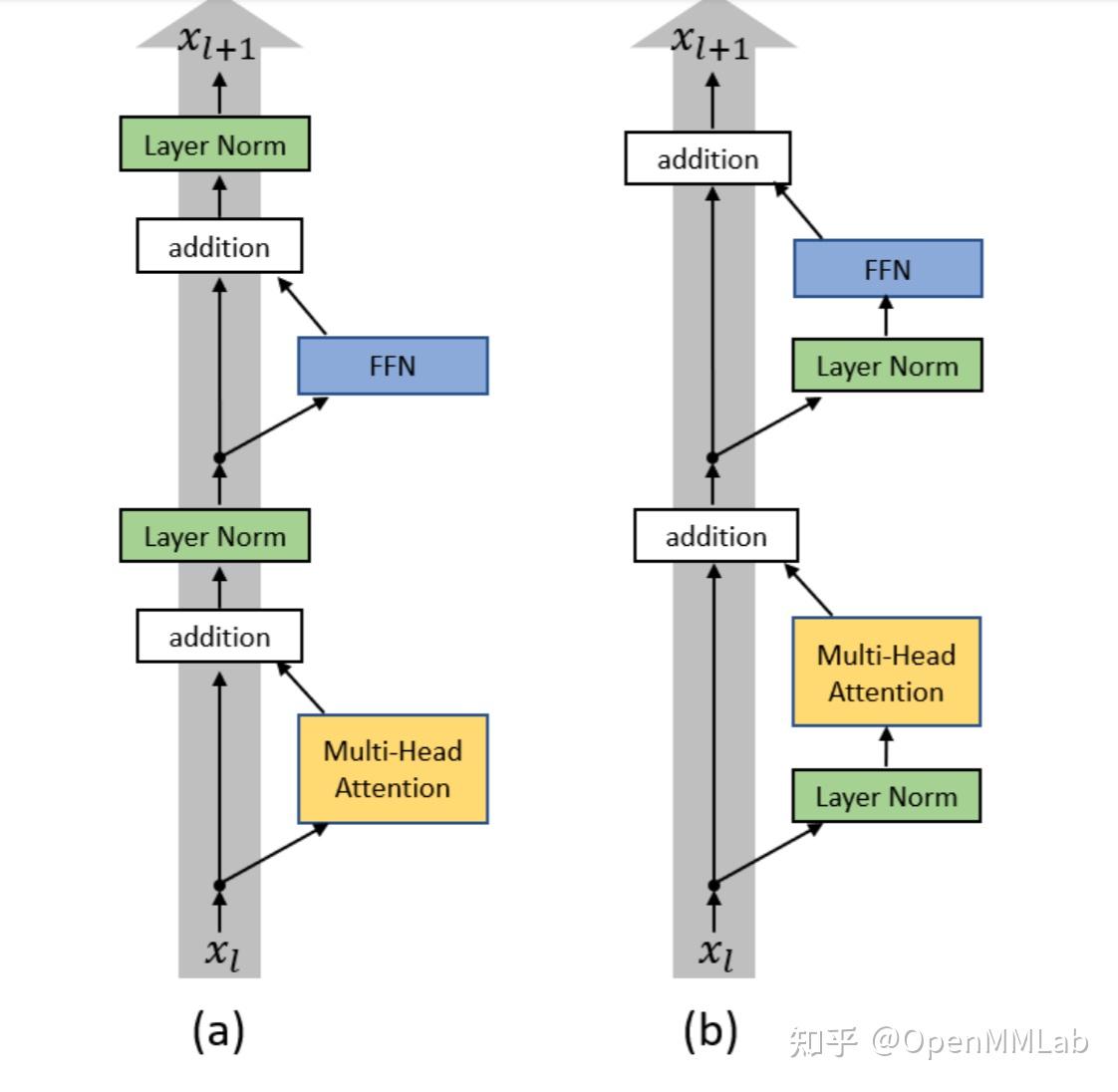
比如,论文中这两种执行逻辑可以通过指定不同的operation_order 轻松实现 a. operation_order=('self_attn', 'norm', 'ffn', 'norm') b. operation_order=('norm', 'self_attn', 'norm', 'ffn')
限于篇幅,更多介绍不在此展开,大家可以在各个具体方向的代码中看到他们的应用。
2 MMClassifcation
GitHub 地址:
这项工作首次实现了 Transformer 在图片分类领域的应用。实验结果表明,视觉领域并不一定要依赖于卷积神经网络(CNN),将图片块(patch)序列输入 transformer 也可实现很好的图片分类效果。
作者认为虽然之前就有工作使用 multi-head self-attention 代替卷积操作应用在 CV 领域,但由于精心设计的注意力模式,他们很难在 GPU 上高效的运行。本文提出的这个模型只对传统的 Transformer 做了微小的修改,目的是想要证明,当进行适当地扩展时,该方法足以超越当前最优的卷积神经网络。

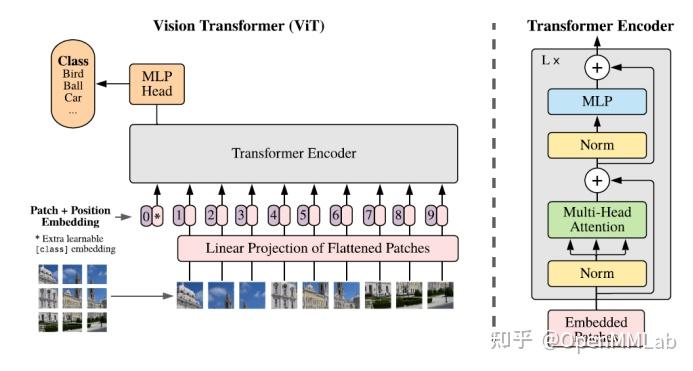
模型结构如图所示,输入一张图片,把它分为若干个 patch,对每个 patch 做相同的线性映射得到一个低维的向量。并借鉴 BERT 的想法,另外引入了一个专门用于分类的向量c ls,将他们拼接在一起再加上一个position embedding 引入位置信息后,作为 transformer encoder 的输入。
最后,用于分类的cls向量对应的输出做一个 mlp,即可实现分类任务。在大规模数据集上进行预训练后,在特定下游任务上做简单的 finetune,即可实现对应领域的图片识别。
GitHub 地址:
当在中型数据集(如 ImageNet)上做预训练时,ViT 的性能会低于卷积神经网络。本文作者认为主要有以下两点原因:
1. 输入图像的简单 token 化无法对相邻像素之间的重要局部结构(如边、线)进行建模,导致其训练样本效率低下;
2. ViT中存在冗余的注意力机制,导致在有限的计算资源和训练样本下,特征丰富度欠缺。
为了克服这些限制,作者提出了 Tokens-to-Token Vision Transformer,他引入了:
1. Tokens-To-Token Layer,递归地将相邻的tokens聚合为一个 token,将图像逐步结构化为 tokens,这样,可以对邻居 tokens 呈现的局部结构进行建模,并且可以减少 tokens 的长度;
2. 一个拥有更瘦长的结构的高效 backbone 网络,这是受到 CNN 的启发。

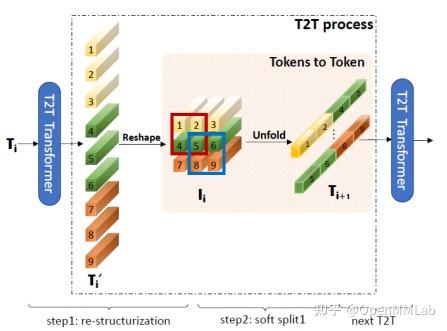
文章的主要创新是提出了这种 Tokens-to-Token 变换(T2T Layer)。如上图所示,该模块的输入是一个 tokens 序列
之后将一个 patch 中的元素 Unfold 起来,得到

GitHub 地址:
这项工作在 ViT 的基础上,实现了一种新的处理视觉任务的 Transformer 架构。
Swin-Transformer 提出了一种分层的 Transformer 结构,这种分层结构有利于将网络应用于各种尺度的任务中,如检测和分割。
同时,Swin-Transformer 还提出了移位窗口多头自注意力机制(Shift Window Multihead Self Attention),相比于之前研究中使用的窗口多头注意力,移位机制允许了相邻的不重叠窗口之间交换信息,提高了信息提取的效率。

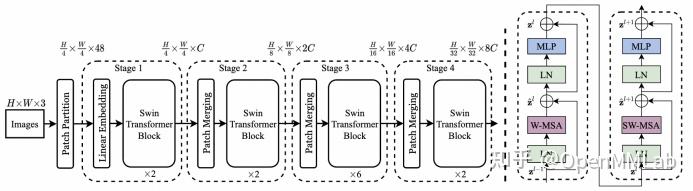
模型结构如图所示,图右为其中两个接连的 block 结构,可以看到两个接连的 block,一个使用了普通的窗口自注意力,另一个则进行了移位,两个 block 相结合,从而实现了上文提到的不重叠窗口间的信息交换。
图左为 tiny 架构的结构,可以看到 Swin-Transformer 沿用了 ViT 的 patch 嵌入思想,对输入图像进行分区和嵌入映射,从而将各种尺寸的图像都能映射到相同长度的低维向量。
但 Swin-Transformer 并没有使用 ViT 中绝对位置嵌入(position embedding)和分类向量(cls token)机制。没有绝对位置嵌入,网络是如何保留 patch 位置信息的呢?
Swin-Transformer 在计算注意力的时候,用一张表保存了各种 patch 相对位置对应的偏置(relative position bias),通过在注意力中引入这一可学习的位置偏置,从而保留 patch 之间的位置信息。
没有分类向量,是如何进行分类任务的呢?Swin-Transformer 利用分层机制,在每个 stage 之间加入 patch merging,对 patch 进行融合,从而使网络的最终输出能够融合全局信息,直接进行分类。同时这种分层机制也能够保留图像的多尺度信息,进行目标检测和分割。
Swin-Transformer 中有两处对图像/特征图进行分片的操作 — Patch Embed 和 Patch Merging。在原始的实现中,这两种操作都是对图像进行不重叠的分区,可扩展性有限,而在 MMClassification 中,我们将 Patch Embed 抽象为 Conv2d 的一种特殊形式,而 Patch Merging 抽象为 Unfold,Norm 和 Linear 的组合,从而支持了分区的重叠,以及高可配置的stride、dilation、padding 等参数。
3 MMDetection
GitHub 地址:
DETR 提出了检测的一种新的范式,通过 set loss,二分图匹配,以及将 Head 结构换为 Transformer,成功实现了一对一的正负样本匹配,从而去掉了 NMS 这一后处理,检测任务的逻辑结构第一次变得如此简单。

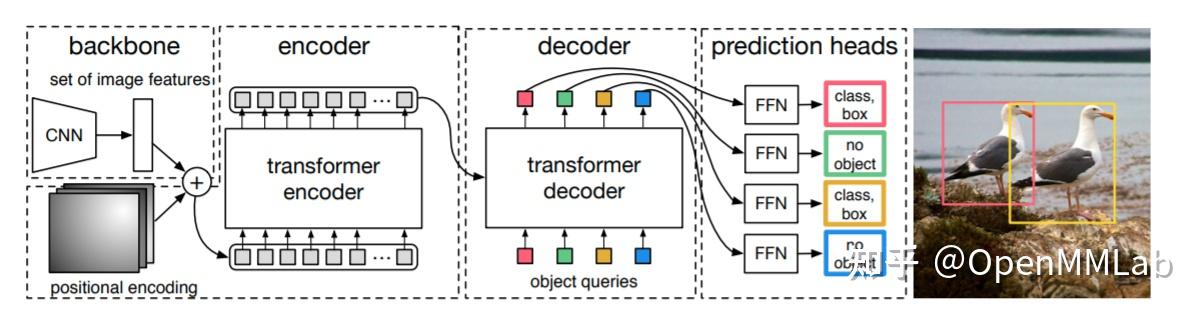
其骨干网络依旧使用的是 CNN, 提取基本特征后加上 Position Encoding 进行进一步的特征提取,通过 100 个 query 从 feature map 上不断提取需要的信息,在 6 层 decoder layer 后,以每个 query 的 分类loss 与 回归 loss 为代价与 Ground Truth 进行匈牙利匹配,从而实现一对一的正负样本匹配。
GitHub 地址:
Deform DETR 保留了 DETR 的基本设计,但是着重解决了 DETR 的收敛速度慢与性能低的问题。
对于收敛速度,从近期工作也可以看出,从全局 Attention 退化为局部的 Attention 可以显著的提高收敛速度,论文中提出了一种稀疏的局部的 attention 计算单元 deformable attention module, 实现了更快地收敛与更好的性能。

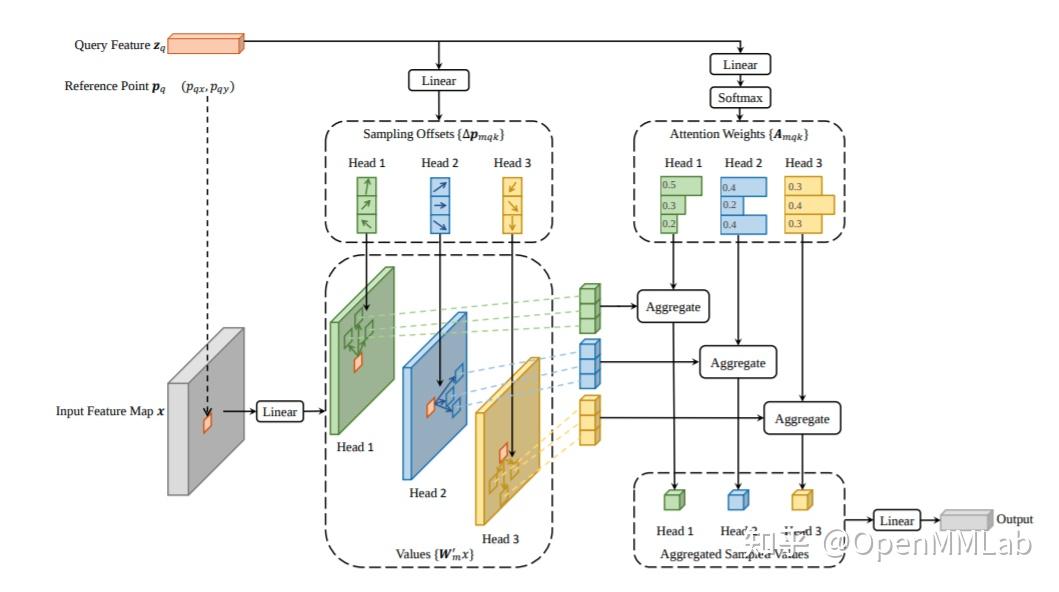
另一方面,基于 CNN 中解决检测问题的经验,含有 RPN 的双阶段结构,多尺度特征融合,Cascade 的 Refine 结构,都应该能大幅提高性能,作者把这些经典设计一一映射到 Deform DETR 中,从而大幅提高了性能。
整个代码结构上,我们充分利用的 MMCV 中的 TransformerLayerSequence 的设计,通过 config 组合不同的 TransformerLayer 可以轻松实现 Deform DETR 与 DETR.
GitHub 地址:
这两个方法还在 review 中,计划在 V2.16.0 发布。
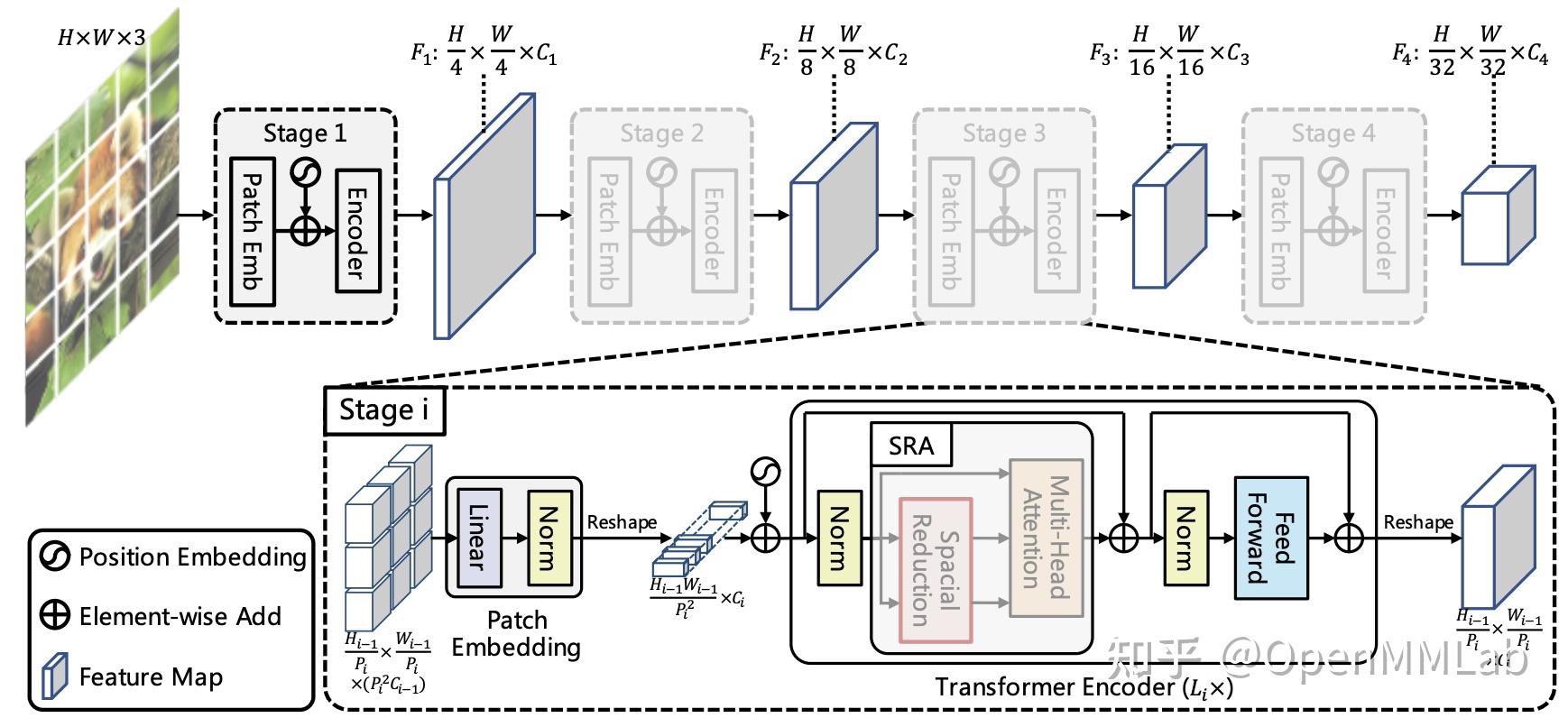
PVT 将金字塔结构引入到 Transformer 中,使其可以像 ResNet 那样无缝接入各种下游任务,并且取得了不错的效果。例如在目标检测上,PVT-S RetinaNet 在 COCO val2017 上的 AP 可以到 40 。
PVTv2 在 v1 的基础上进行了 3 点改进,包括:带有 depthwise 卷积的 FFN,基于 zero padding 的位置编码,以及线性复杂度的 attention 层。
基于这些改进,在目标检测上,PVTv2 同样大小的模型比 Swin 好 1-2 个点,并且解决了大分辨率输入下计算复杂度大的问题。

4 MMDetection3D
GitHub 地址:
Group-free-3D 同样继承了 DETR 的基本设计结构,但是针对 3D 点云的数据特点进行了相应的改进,使其更加适用于 3D 目标检测任务。
一是采用了具有数据先验信息的初始对象候选,由于点云本身数据的特殊性,抛弃 DETR 的初始对象候选方法,采用了基于点云采样方法 KPS 获得初始对象候选,充分利用了点云数据的信息,大幅提高了模型的检测性能。
另一方面,不同于 VoteNet 等方法设定一个或者多个固定 group 尺寸的思想,将局部点分组到每个候选对象,而是基于 self-attention module 和 cross-attention module 分别建立各个候选对象之间的依赖关系,以及点云中的各个点与各个候选对象的依赖关系,给予权重,这样既避免了 group 尺寸的超参数设定问题,同时也实现了自适应的尺度优势。

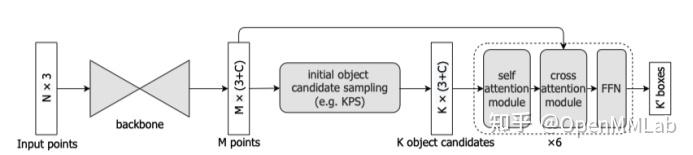
此外,该论文引入了逐阶段修正 spatial encoding 的方法,通过将前一阶段预测出的 box location 作为辅助信息更新下一个阶段的 spatial encoding,从而进一步提高了模型的性能。
5 MMSegmentaion
GitHub 地址:
SegFormer 是一个简单,高效并且鲁棒性很好的语义分割方法,它的 encoder 是一个分层次的 Transformer 结构,基于 PVTv1 做出了一些重要的改进,并在 ImageNet-1K 上做了预训练。它的decoder全部由MLP构成,不包含 dilated conv,aux loss 等复杂的操作。
SegFormer 有 B0-B5 6 种不同的 model size,其中 B0 的 model 只有 3.7M 参数,速度也非常快,而 B5 的 model 是 87M 参数,可以达到目前领先的水平。

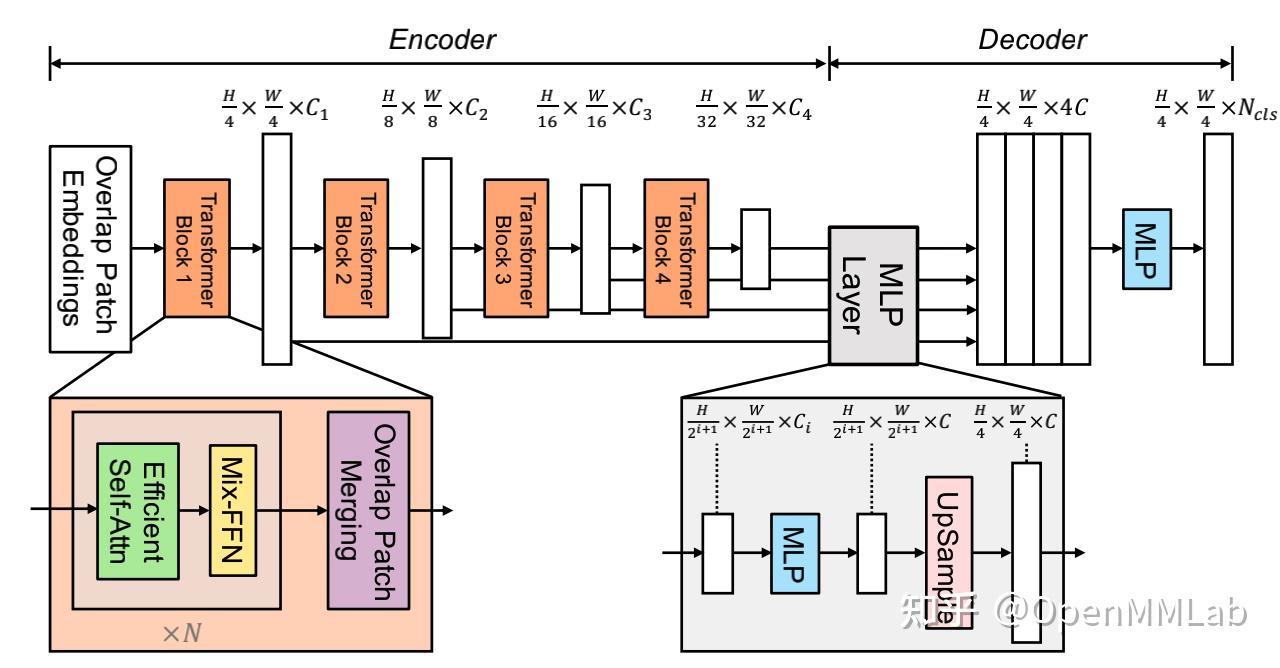
GitHub 地址:
MMSegmentation 在原始 ViT 的基础上,提供了更多的特性,例如:支持输出多个 Layer 的特征图;提供一个修改输出特征图大小的简易上下采样结构;支持随机尺寸的图片输入;提供多种输出形式以支持不同的算法;支持导入 MMClassification、timm 等仓库的预训练权重。
GitHub 地址:
SETR 是 Semantic Segmentation 引入 vision transformer 早期较为成功的网络, SETR 主要提供了三种形式:Naive、PUP、MLA。
其中 Naive 与 PUP 主要使用 Backbone 最后一层输出,来进行语义解析输出分割图,MLA 则使用了多个 Backbone 层输出,然后使用了一个特征金字塔来提取多尺度特征,而后融合多层输出,经过像素级分类器得到分割结果。

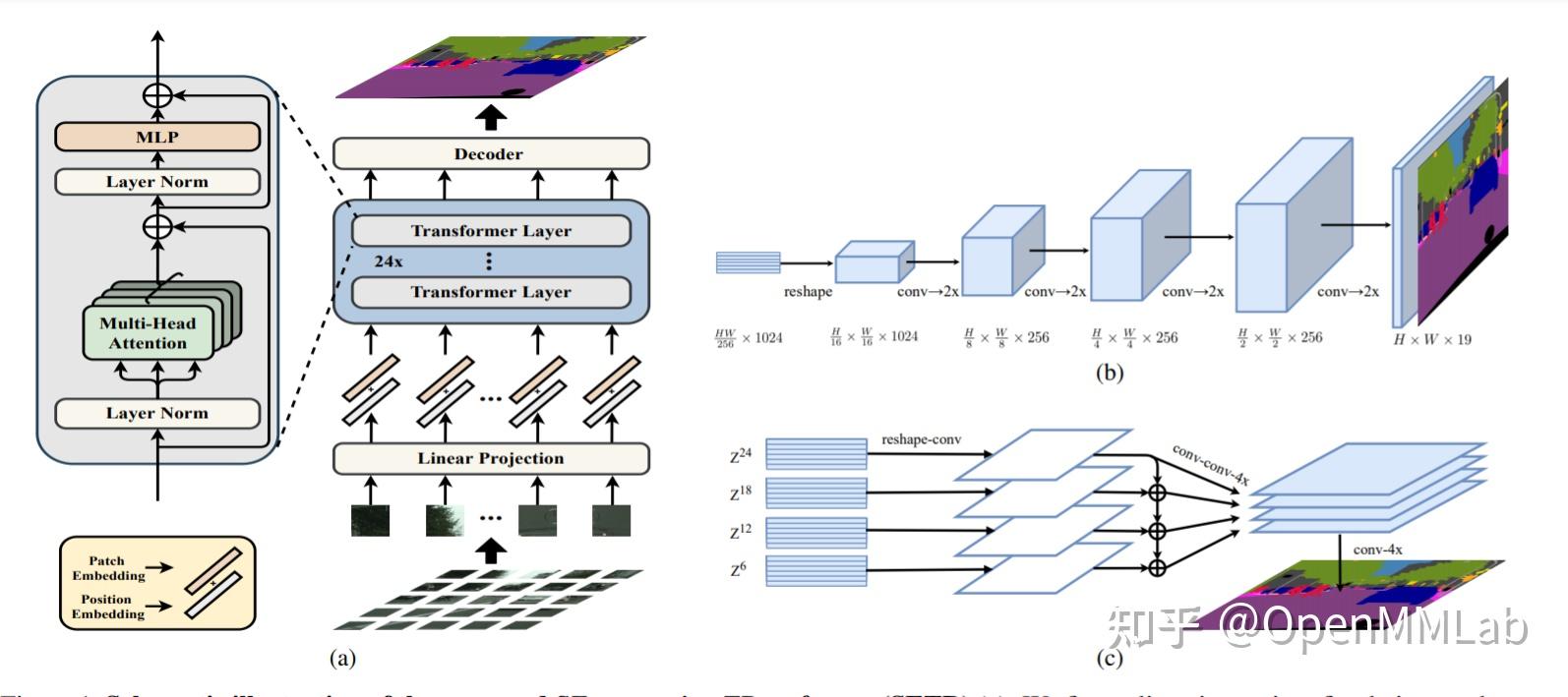
GitHub 地址:
MMSegmentation 的主要特性在于将 PatchMerging 的 index sample Linear 拓展成了 nn.Unfold Linear。nn.Unfold 与卷积参数基本一致,这就使得 PatchMerging 模块的可操作性更强。
例如,通过设置 dilation 来实现 Dilated Swin Transformer,通过设置 kernel_size 和 stride 来实现 Overlapping PatchMerging 等等。此外,MMSegmentation 还加强了对输入尺寸的鲁棒性,支持导入 MMClassification,timm 等 repo 的预训练权重。
6 MMEditing
GitHub 地址:
TTSR 是微软研究院在 CVPR2020 的一篇论文,通过 Transformer 的 multi-self-attention 结构实现了借助参考图像完成超分重建的任务。
单一图像的超分辨率,受限于高分辨率纹理在退化过程中被破坏而无法完整恢复。尽管基于 GAN 的图像重建方法可以伪造高分辨率细节,依然不能得到原始的高频细节。RefSR 通过参考图像对重建图像进行高分辨率纹理转换,可产生令人满意的视觉效果。

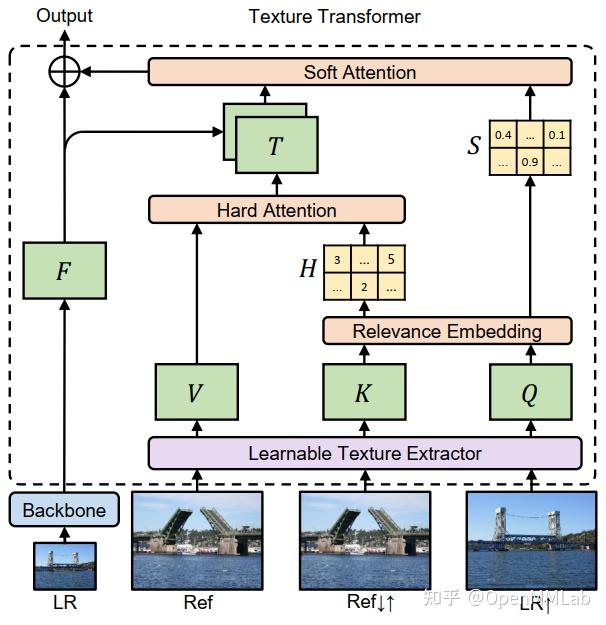
TTSR 模型借助 self-attention 结构充分发挥参考图像的作用:将插值上采样的低分辨率图像看作将参考图像看作 Q,将参考图像看作 V,将下采样-上采样的参考图像看作 K,通过 Hard-Attention 和 Soft-Attention 提取有助于超分辨率重建的高频细节。
TTSR 首先使用可学习的纹理提取器(Learnable Texture Extractor,LTE)将图像加工成特征图。再使用纹理转移器(Texture Transformer)提取有助于超分辨率重建的高频细节。
TTSR 的主干网络同时处理输入的低分辨率图像和 LTE 输出的高频细节,在下图三种尺寸下进行特征提取,实现四倍上采样。
主干网络中使用跨尺度特征集成模型(CrossScale Feature Integrations),融合不同尺度的纹理特征,从而提高网络的特征表达以及生成图像的质量。

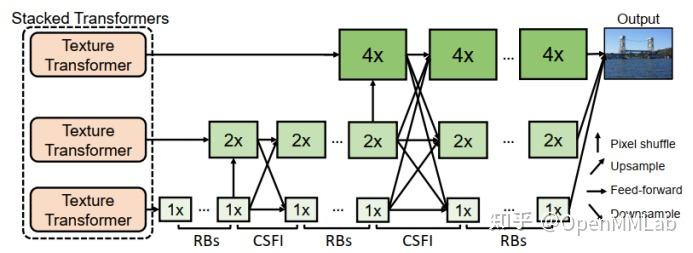
7 MMAction2
GitHub 地址:
这项工作把 Transformer 应用在视频分类领域,并且把 self-attention 机制从图像空间扩展到时空3D领域。
基于 ViT(Vision Transformer), TimeSformer 将输入的视频看做是从多帧中提取图像块的时空序列,然后通过将每个图像块的语义与视频中的其它图像块进行比较,来获取每个图像块的语义。
为了减少计算量,避免所有的图像块之间进行复杂的计算,作者设计了 5 种 self-attention 策略,如下图所示。


其中,Space Attention 计算过程中只考虑每一帧本身,不考虑相邻帧的图像特征交互。
Joint Space-Time Attention不加区分地计算时空上所有特征块间的Attention,需要消耗大量计算量。
Divided Space-Time Attention 计算两种 Attention, 其一为 Time Attention,第 t 时刻的 query 与其余时刻对应位置的图像块进行计算,其二为 Space Attention,第 t 时刻帧中其余图像块参与 query 块的计算。
通过实验证明,Divided Space-Time Attention 的策略能有效降低模型计算量,同时效果最好。
好了,以上就是 OpenMMLab 中复现的13种基于 Transformer 的方法,快去看吧。
版权声明:本文为博主OpenMMLab原创文章,版权归属原作者,如果侵权,请联系我们删除!