Python
Meet HistGradientBoostingClassifier
更灵活和可扩展的 GradientBoostingClassifier
Scikit-learn 的 GradientBoostingClassifier(GBM 从这里开始)是在许多数据集上表现良好的最流行的集成算法之一。 HistGradientBoostingClassifier(从这里开始的 HGBM)是一种基于直方图的 GBM 替代实现,在 v0.21.0 中作为实验估计器引入。从 v1.0.0 开始,此估算器已成为稳定的估算器。在这篇文章中,我们将看看使用 HGBM 优于 GBM 的两个主要优势。[0][1][2][3]
还有等效的回归:HistGradientBoostingRegressor。但是,我们不会覆盖它以避免重复,因为同样的逻辑适用。[0]

📦 1. Handles missing data
该估计器可以处理缺失数据,因为它具有对缺失值的内置支持。让我们看看这个在行动。我们将首先导入库并创建具有缺失值的示例数据:
import numpy as np
import pandas as pd
from time import perf_counter
pd.options.display.max_columns = 6from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.ensemble import (GradientBoostingClassifier,
HistGradientBoostingClassifier)
from sklearn.metrics import accuracy_score, roc_auc_score, f1_scoreimport matplotlib.pyplot as plt
import seaborn as sns
sns.set(style='darkgrid', context='talk', palette='rainbow')n = 10**4
X, y = make_classification(n, random_state=42)
X = pd.DataFrame(X, columns=[f'feature{i}' for i in range(X.shape[1])])# Randomly add missing data for all columns
for i, col in enumerate(X.columns):
np.random.seed(i)
X.loc[np.random.choice(range(n), 1000, replace=False), col] = np.nanprint(f"Target shape: {y.shape}")
print(f"Features shape: {X.shape}")
X.head()
我们现在将对数据进行分区并尝试适应 GBM:
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=42)
print("========== Training data ========== ")
print(f"Features: {X_train.shape} | Target:{y_train.shape}")
print("========== Test data ========== ")
print(f"Features: {X_test.shape} | Target:{y_test.shape}")gbm = GradientBoostingClassifier(random_state=42)
gbm.fit(X_train, y_train)
gbm.score(X_test, y_test)

像大多数 Scikit-learn 的估计器一样,尝试将模型拟合到具有缺失值的数据将触发 ValueError: Input contains NaN, infinity or a value too large for dtype(‘float32’)。
现在,让我们看看如果我们使用 HGBM 会发生什么:
hgbm = HistGradientBoostingClassifier(random_state=42)
hgbm.fit(X_train, y_train)
hgbm.score(X_test, y_test)太棒了,这非常有效,因为估计器可以本地处理丢失的数据。这是 HGBM 提供的优于 GBM 的一项优势。
📊 2. 可以很好地处理更大的数据
HGBM 是一种更快的实现 GBM,并且可以很好地适应更大的数据集。让我们看看两个估计器如何比较不同大小的样本数据:
n_samples = 10**np.arange(2,7)
tuples = [*zip(np.repeat(n_samples,2), np.tile(['gbm', 'hgbm'], 2))]
summary = pd.DataFrame(
index=pd.MultiIndex.from_tuples(tuples,
names=["n_records", "model"])
)models = [('gbm', GradientBoostingClassifier(random_state=42)),
('hgbm', HistGradientBoostingClassifier(random_state=42))]for n in n_samples:
X, y = make_classification(n, random_state=42)
X_train, X_test, y_train, y_test = train_test_split(
X, y, random_state=42
)
for name, model in models:
start = perf_counter()
model.fit(X_train, y_train)
end = perf_counter()
summary.loc[(n, name), 'fit_time'] = end-startstart = perf_counter()
y_proba = model.predict_proba(X_test)[:,1]
end = perf_counter()
summary.loc[(n, name), 'score_time'] = end-start
summary.loc[(n, name), 'roc_auc'] = roc_auc_score(y_test,
y_proba)
y_pred = np.round(y_proba)
summary.loc[(n, name), 'accuracy'] = accuracy_score(y_test,
y_pred)
summary.loc[(n, name), 'f1'] = f1_score(y_test, y_pred)
summary
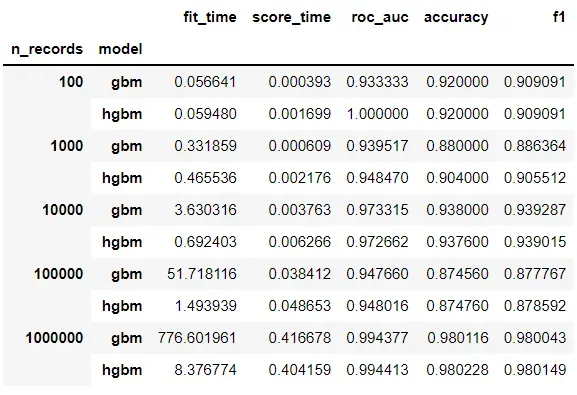
在这里,总记录的 75% 用于训练,其余 25% 的记录用于测试。我们可以看到,随着训练数据的增长,使用 HGBM 的训练时间要快得多。数据越大,HGBM 的速度就越令人印象深刻。 HGBM 通过将数据粗化为分箱特征来实现其惊人的速度。让我们更仔细地看一下摘要:
fig, ax = plt.subplots(2, 1, figsize=(9,6), sharex=True)
sns.lineplot(data=summary['fit_time'].reset_index(),
x='n_records', y='fit_time', hue='model', ax=ax[0])
ax[0].legend(loc='upper right', bbox_to_anchor=(1.3, 1))
sns.lineplot(data=summary['score_time'].reset_index(),
x='n_records', y='score_time', hue='model',
legend=False, ax=ax[1])
ax[1].set_xscale('log')
fig.tight_layout();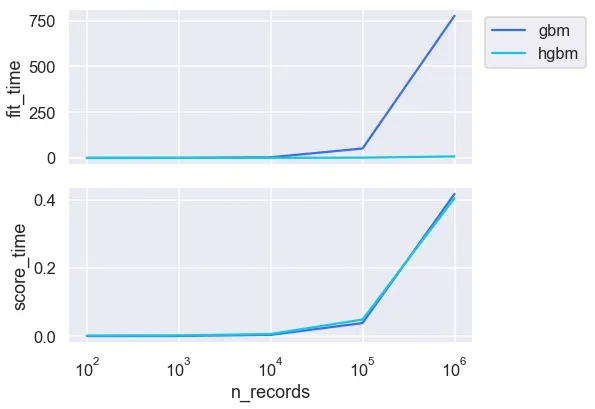
随着训练示例数量的增加,GBM 的训练时间显着增加,而 HGBM 在更大的数据集上仍然相对较快。两者之间的得分时间非常接近。
fig, ax = plt.subplots(3, 1, figsize=(9,9), sharex=True)
sns.lineplot(data=summary['roc_auc'].reset_index(),
x='n_records', y='roc_auc', hue='model', ax=ax[0])
ax[0].legend(loc='upper right', bbox_to_anchor=(1.3, 1))
sns.lineplot(data=summary['accuracy'].reset_index(),
x='n_records', y='accuracy', hue='model',
legend=False, ax=ax[1])
sns.lineplot(data=summary['f1'].reset_index(),
x='n_records', y='f1', hue='model',
legend=False, ax=ax[2])
ax[2].set_xscale('log')fig.tight_layout();
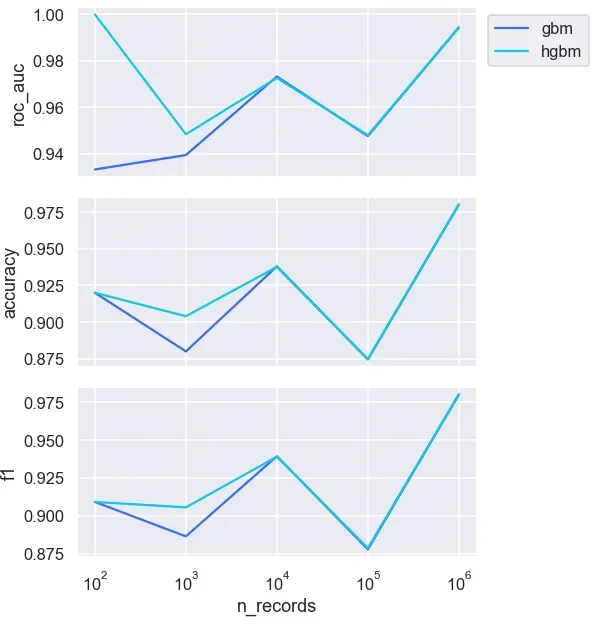
总体而言,两者之间的预测性能非常相似,尽管当训练数据较小时,在 75 和 750 时存在一些差异。
正如您现在所知道的,与 GBM 相比,HGBM 的第二个好处是它在大数据集上的扩展性非常好。
这就是这篇文章的内容!希望您喜欢学习这个灵活且可扩展的估算器,并为进一步探索它感到兴奋。如果您想了解更多信息,HGBM 还具有对分类特征的原生支持。该文档显示了有关此功能的一些很好的示例。[0]

您想访问更多这样的内容吗? Medium 成员可以无限制地访问 Medium 上的任何文章。如果您使用我的推荐链接成为会员,您的一部分会员费将直接用于支持我。[0]
感谢您阅读本文。如果你有兴趣,这里是我其他一些帖子的链接:
◼️️ 从机器学习模型到机器学习管道
◼️️ 用 SHAP 解释 Scikit-learn 模型
◼️️ 在 Python 中绘制多个图形的 4 个简单技巧
◼️ Prettifying pandas DataFrames
◼ Python 中的简单数据可视化,您会发现它很有用️
◼️ Seaborn (Python) 中更漂亮和自定义绘图的 6 个简单技巧[0][1][2][3][4][5]
Bye for now 🏃 💨
文章出处登录后可见!