


一致的半监督、可解释的医学成像多任务处理
MultiMix:从医学图像中进行少量监督的极端多任务学习

在本文中,我将讨论由 Ayaan Haque(我)、Abdullah-Al-Zubaer Imran、Adam Wang 和 Demetri Terzopoulos 开发的一种新的半监督、多任务医学成像方法 MultiMix。我们的论文被 ISBI 2021 的全文接收,并在 4 月的会议上发表。我们论文的扩展结果得到了改进,也发表在了 MELBA 杂志上。本文将介绍方法、结果和简短的代码审查。代码可在此处获得。[0][1][2][3]
Overview:
MultiMix 通过采用基于置信度的增强策略和为联合任务提供可解释性的新型显着性桥模块来执行联合半监督分类和分割。基于深度学习的模型在完全监督的情况下可以有效地执行复杂的图像分析任务,但这种性能在很大程度上依赖于大型标记数据集的可用性。尤其是在医学成像领域,标签价格昂贵、耗时且容易受到观察者的影响。结果,允许从有限数量的标记数据中学习的半监督学习已被研究作为监督对应物的替代方案。
此外,在同一模型中学习多个任务进一步提高了模型的泛化性。此外,多任务允许任务之间共享表示学习,同时需要更少的参数和更少的计算,从而使模型更高效且不易过拟合。
我们对不同数量的标记数据和多源数据的广泛实验证明了我们方法的有效性。此外,我们还展示了跨任务的域内和跨域评估,以展示我们的模型适应具有挑战性的泛化场景的潜力,这对于医学成像方法来说是一项具有挑战性但重要的任务。
Background:
The Problem
近年来,基于学习的医学成像得到了发展,主要是因为深度学习的发展。然而,深度学习的基本问题始终存在,即它们需要大量标记数据才能有效。不幸的是,这在医学成像领域是一个更大的问题,因为收集大型数据集和注释可能很困难,因为它们需要领域专业知识、昂贵、耗时且难以在集中式数据集中组织。此外,泛化是医学成像领域的一个关键问题,因为来自不同来源的图像在质量和数量上都可能存在显着差异,如果我们想在多个领域实现强大的性能,那么模型构建的过程就会变得困难。我们希望通过一些以半监督和多任务学习为中心的关键方法来解决这些基本问题。
什么是半监督学习?
为了解决有限的标记数据问题,半监督学习(SSL)作为一种有前途的替代方案受到了广泛关注。在半监督学习中,未标记示例与标记示例结合使用以最大化信息增益。在半监督学习方面已经有很多研究,包括一般和医学领域的具体研究。我不会详细讨论这些方法,但如果您有兴趣,这里列出了一些重要的方法供您参考 [1, 2, 3, 4]。[0][1][2][3]
解决有限样本学习的另一种解决方案是使用来自多个来源的数据,因为这会增加数据中的样本数量以及数据的多样性。然而,这样做具有挑战性并且需要特定的培训方法,但如果做得正确,它可能会产生很大的影响。
什么是多任务学习?
多任务学习 (MTL) 已被研究用于提高许多模型的通用性。多任务学习被定义为优化单个模型中的多个损失,以便通过共享表示学习执行多个相关任务。在模型中联合训练多个任务可以提高模型的泛化性,因为每个任务都会相互规范化。此外,假设训练数据来自具有有限注释的不同任务的不同分布,多任务处理在这种情况下可以用于以几乎没有监督的方式进行学习。将多任务与半监督学习相结合可以提高这两个任务的性能并取得成功。同时完成这两项任务可能是非常有益的,因为无需拥有受过医学培训的专业人员,一个单一的深度学习模型就可以非常准确地完成这两项任务。
关于医学领域的相关工作,我不会详细介绍方法,但这里有一个列表:[1,2,3,4,5,6,7,8,9,10]。然而,这些工作的主要限制是它们不使用来自多个来源的数据,限制了它们的普遍性,以及大多数方法只是单任务方法。[0][1][2][3][4][5][6][7][8][9]
因此,我们提出了一种新的、更通用的多任务模型,称为 MultiMix,结合了基于置信度的增强和显着性桥模块,从多源数据中共同学习诊断分类和解剖结构分割。显着性图可以通过有意义的视觉特征的可视化来分析模型预测。可以通过几种方式生成显着图,最明显的是通过计算输入图像的类别分数的梯度。虽然可以通过显着性图研究任何深度学习模型以获得更好的可解释性,但据我们所知,尚未探索单个模型中两个共享任务之间的显着性桥梁。
The Algorithm:
让我们从定义我们的问题开始。我们使用两个数据集进行训练,一个用于分割,一个用于分类。对于分割数据,我们可以使用符号 Xs 和 Y,它们分别是图像和分割掩码。对于分类数据,我们可以使用符号 Xc 和 C,它们是图像和类标签。
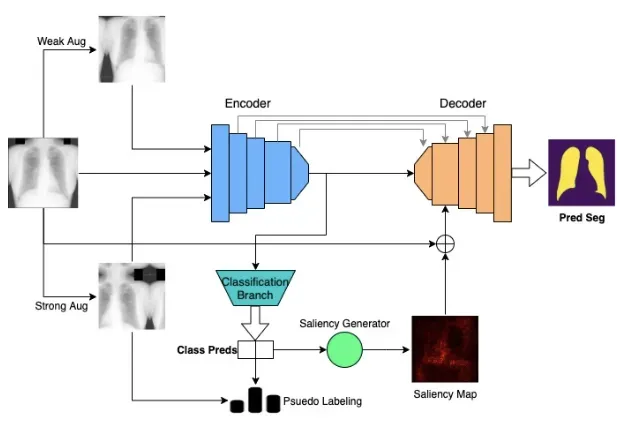
关于我们的模型架构,我们使用基线 U-Net 架构,这是使用编码器-解码器框架的常用分割架构。编码器的功能类似于标准 CNN。为了使用 U-Net 执行多任务,我们从编码器中分离出池化层和全连接层,以获得最终的分类输出。

Classification:
对于我们提出的分类方法,我们利用数据增强和伪标签。受 [1] 的启发,我们采用未标记的图像并执行两个单独的增强。首先,对未标记的图像进行弱增强,然后根据该图像的弱增强版本,根据模型当前状态的预测假设伪标签。这就是为什么该方法是半监督的,但稍后我们将更多地讨论伪标记过程。
其次,对相同的未标记图像进行强烈增强,并使用来自弱增强图像和强增强图像本身的伪标签计算损失。本质上,我们正在教模型将弱增强图像映射到强增强图像,这迫使模型学习诊断分类所需的基本基础特征。两次增强图像还可以最大限度地提高单个图像的潜在知识增益。这也有助于提高泛化能力,就好像模型被迫只学习图像中最重要的部分一样,它将能够克服由于不同领域而出现在图像中的差异。
关于增强,我们对弱增强图像使用常规增强,例如水平翻转和轻微旋转。强增强策略更有趣。我们创建了一个非常规的强增强池,并将随机数量的增强应用到任何给定的图像。这些增强是相当扭曲的,例如包括裁剪、自动对比度、亮度、对比度、均衡、标识、旋转、锐度、剪切等等。通过应用任意数量的这些,我们创建了极其广泛的图像,这在处理低样本数据集时尤其重要。我们最终发现,这种增强策略对于强大的性能非常重要。
现在让我们回过头来讨论伪标记过程。因此,一旦将弱增强转换为伪标签,我们就只使用它们。请注意,如果模型生成伪标签的置信度高于调整阈值,则该图像标签可以防止模型从不正确和差的情况中学习标签。这导致课程免费效果,因为当预测在开始时不太自信时,模型主要从标记数据中学习。该模型对为未标记图像生成标签变得更加自信,因此,模型变得更加高效。就提高性能而言,这也是一个非常重要的特性。
现在让我们看一下损失函数。分类损失可以通过以下等式建模:

其中 L-sub-l 是监督损失,c-hat-l 是分类预测,c-l 是标签,lambda 是无监督分类权重,L-sub-u 是无监督损失,c-hat-s 是对强增强图像的预测,argmax(c-hat-w) 是来自弱增强图像的伪标签,t 是伪标签阈值。
这基本上总结了分类方法,所以现在让我们继续讨论分割方法。
Segmentation:

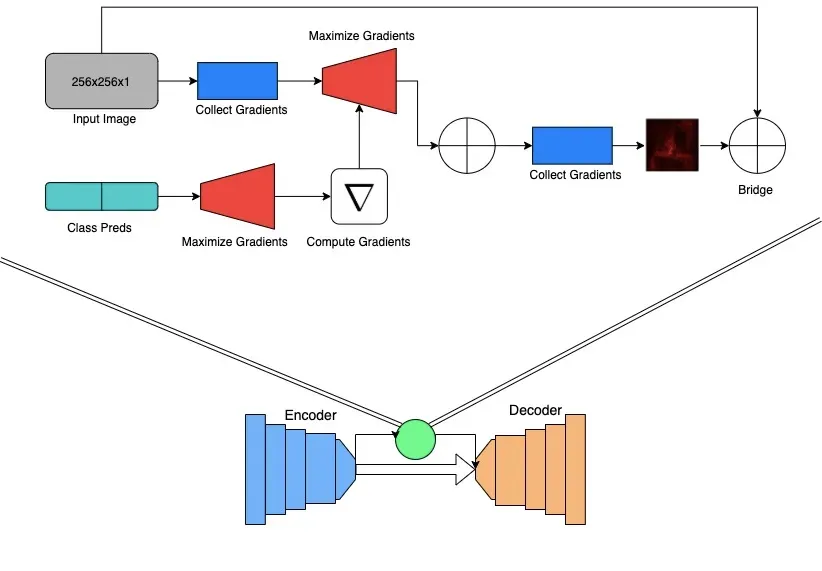
对于分割,预测是通过带有跳跃连接的编码器-解码器架构进行的,这非常简单。如上图所示,我们对分割的主要贡献是结合了显着性桥模块来桥接两个任务。我们使用从编码器扩展到分类分支的梯度,根据模型预测的类生成显着性图。整个过程如上所示,但本质上是一个显着性图突出了模型用于对图像进行肺炎分类的图像的哪些部分。当可视化时,它们最终看起来类似于分割图,使其成为分割桥的完美补充。
虽然我们不知道分割图像是否代表肺炎,但生成的地图会突出显示肺部,以最终分割分辨率创建图像。因此,当生成图像的类别预测并使用显着性图进行可视化时,它有点类似于肺掩模。我们假设这些显着性图可用于在解码器阶段指导分割,在从有限的标记数据中学习的同时产生改进的分割。
在 MultiMix 中,生成的显着性图与输入图像连接、下采样并添加到输入到第一个解码器阶段的特征图。与输入图像的连接允许在两个任务之间建立更强的联系,并由于它提供的上下文而提高了桥模块的有效性。添加输入图像和显着图为解码器提供了更多的上下文和信息,这在处理低样本数据时非常重要。
现在让我们讨论一下训练和损失。对于标记的样本,我们通常使用参考肺掩模和预测分割之间的骰子损失来计算分割损失。
由于我们没有未标记分割样本的分割掩码,因此我们无法直接计算它们的分割损失。因此,为此,我们计算标记和未标记示例的分割预测之间的 KL 散度。这会惩罚模型做出与标记数据的预测越来越不同的预测,这有助于模型更适合未标记数据。虽然这是一种计算损失的间接方法,但它仍然允许模型从未标记的分割数据中学到很多东西。
关于损失,我们的分割损失可以写成:

其中 alpha 是与分类相比的分割损失权重,y-hat-l 是标记的分割预测,y-l 是相应的掩码,beta 是无监督的分割权重,y-hat-u 是未标记的分割预测。
我们的模型是针对分类和分割损失的综合目标进行训练的。现在我们已经讨论了损失,它包含了分割方法以及整个方法部分。
Datasets:
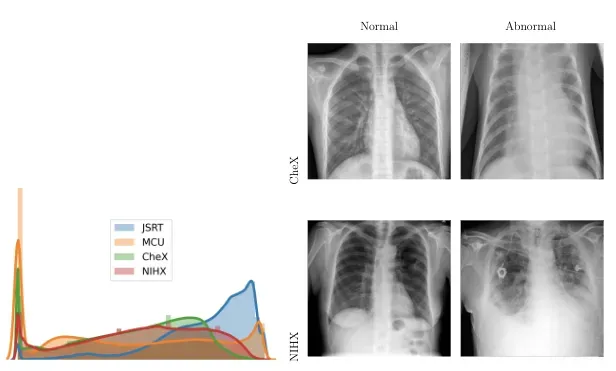
这些模型针对分类和分割任务进行了训练和测试,每个任务的数据来自两个不同的来源:肺炎检测数据集,我们将其称为 CheX [11],以及日本放射技术学会或 JSRT [12] ,分别用于分类和分割。当我们提到域内数据集时,这是两个数据集。[0][1]
重要的是,我们在两个外部数据集上验证了模型,每个任务一个。我们使用了蒙哥马利县胸部 X 光片或 MCU [13],以及 NIH 胸部 X 光片数据集的一个子集,我们将其称为 NIHX [14]。来源的多样性对我们的模型提出了重大挑战,因为图像质量、大小、正常和异常图像的比例以及四个数据集的强度分布差异都存在很大差异。下图显示了强度分布的差异以及来自每个数据集的图像示例。所有 4 个数据集都具有 CC BY 4.0 许可证。[0][1]

Results:
我们在多个数据集(包括域内和跨域)上对不同数量的标记数据进行了大量实验。
作为结果的序言,我们在测试中使用了多个基线,因为我们对模型的每个添加都有一个基线。我们从准系统 U-Net 和标准分类器 (enc) 开始,这是具有密集层的编码器特征提取器。然后,我们将两者结合起来用于我们的基线多任务模型 (UMTL)。我们还使用了具有半监督方法的编码器 (EncSSL)、具有显着性桥 (UMTLS) 的多任务模型,以及具有显着性桥和提议的半监督方法 (UMTLS-SSL) 的多任务模型,这基本上是MultiMix,没有KL散度,用于半监督分割。然后我们当然有MultiMix。
在训练方面,我们在多个级别的标记数据集上进行了训练。对于分类,我们使用了 100、1000 和所有标签,对于分割,我们使用了 10、50 和所有标签。对于我们的结果,我们将使用符号:model-seglabels-classlabels(例如 MultiMix-10-100)。对于评估,我们使用准确度(Acc)和 F1 分数(F1-N 和 F1-P)进行分类,对于分割,我们使用 Dice Similarity (DS)、Jaccard Similarity Score (JS)、结构相似性指数度量 (SSIM) 、平均豪斯多夫距离 (HD)、精度 (P) 和召回率 (R)。
下图是 MultiMix 针对多个基线的性能表。最好的全监督分数用下划线表示,最好的半监督分数用粗体表示。

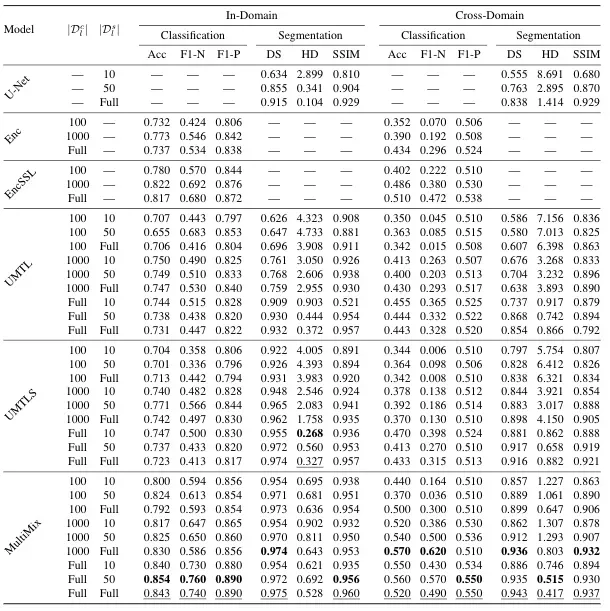
该表显示了如何通过随后包含每个新组件来改进模型性能。对于分类任务,与基线模型相比,我们用于半监督学习的基于置信度的增强方法显着提高了性能。即使每个任务的标记数据最少,我们的 MultiMix-10-100 在准确性方面也优于完全监督的基线编码器。对于分割,显着性桥模块的包含对基线 U-Net 和 UMTL 模型产生了很大的改进。即使使用最小分割标签,我们也可以看到比同类产品提高 30% 的性能,证明了我们提出的 MultiMix 模型的有效性。
我们非常关注泛化的重要性,我们的结果表明我们的模型能够很好地泛化。 MultiMix 在两个任务中的通用性都得到提高的领域中始终表现良好。如表中所示,MultiMix 的性能与域内的性能一样有希望。 MultiMix 在所有基线模型的分类任务中取得了更好的成绩。由于前面讨论的 NIHX 和 CheX 数据集存在显着差异,因此分数不如域内结果好。然而,它确实比其他模型表现得更好。

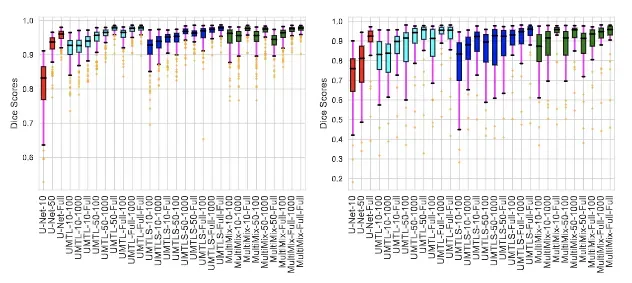
下图是一个箱线图,显示了我们在域内和跨域评估中的分割结果的一致性。我们针对数据集中的每个图像显示我们模型的骰子分数。从图中,我们可以看到与基线相比,MultiMix 是最强的模型。

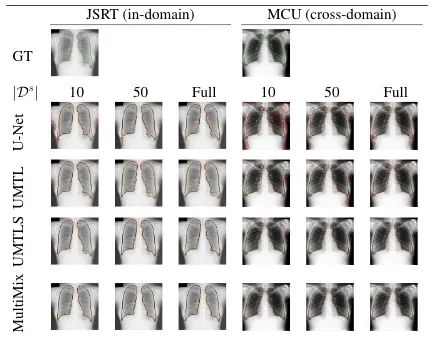
我们将讨论的最后一个图是我们模型的分割预测的可视化。我们针对不同标记数据的基本事实显示了每个提议的分割任务添加的预测边界,包括域内和跨域。该图显示了 MultiMix 的边界预测与地面实况边界的高度一致,尤其是与基线相比时。尤其是跨领域,MultiMix 是最好的,有相当大的优势,显示了我们强大的泛化能力。
Code Review:
现在我们已经介绍了方法和结果,让我们进入代码。我将主要介绍模型架构和训练循环,因为这些是主要的贡献领域。请注意,代码是用 PyTorch 和 Python 编写的。
让我们从检查我们的卷积块开始。
def double_conv(in_channels, out_channels):
return nn.Sequential(
nn.Conv2d(in_channels, out_channels, 3, padding=1),
nn.InstanceNorm2d(out_channels),
nn.LeakyReLU(0.2, inplace=True),
nn.Conv2d(out_channels, out_channels, 3, padding=1),
nn.InstanceNorm2d(in_channels),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout(0.25)
)
每个块都是一个双卷积块。我们从核大小为 3 的 2d 卷积层开始,然后使用实例归一化层和 LeakyReLU 的激活函数,其斜率为 0.2。然后我们再次重复这个序列以完成卷积块。
现在让我们来看看显着性桥。
def generate_saliency(inputs, encoder, optimizer):
inputs2 = copy(inputs)
inputs2.requires_grad = True
encoder.eval()
conv5, conv4, conv3, conv2, conv1, scores = encoder(inputs2)
score_max, score_max_index = torch.max(scores, 1)
score_max.backward(torch.FloatTensor([1.0]*score_max.shape[0]).to(device))
saliency, _ = torch.max(inputs2.grad.data.abs(),dim=1)
saliency = inputs2.grad.data.abs()
optimizer.zero_grad()
encoder.train()
return saliency此代码仅用于生成显着图。我们首先传入输入、编码器和优化器。然后我们创建图像的副本以确保图像的渐变不被修改。然后我们将输入 require_grad 设置为 true 并将编码器设置为 eval 模式。然后我们得到编码器的特征图和输出,这样我们就可以生成显着图。我们首先获得分类输出的最大索引,然后使用 .backward() 函数收集梯度。然后我们通过使用 .abs() 函数收集梯度来获得显着性图。重要的是,我们必须将优化器的梯度归零,因为使用反向计算梯度,这在更新模型参数时可能会出现问题。
现在我们已经介绍了架构的组件,让我们将它们放在一起并检查整个架构。
class MultiMix(nn.Module):
def __init__(self, n_class = 1):
super().__init__()
self.encoder = Encoder(1)
self.decoder = Decoder(1)
self.generate_saliency = generate_saliency
def forward(self, x, optimizer):
saliency = self.generate_saliency(x, self.encoder, optimizer)
conv5, conv4, conv3, conv2, conv1, outC = self.encoder(x)
outSeg = self.decoder(x, conv5, conv4, conv3, conv2, conv1, saliency)
# return outSeg, outC, saliency
return outSeg, outC
class Encoder(nn.Module):
def __init__(self, n_class = 1):
super().__init__()
self.dconv_down1 = double_conv(1, 16)
self.dconv_down2 = double_conv(16, 32)
self.dconv_down3 = double_conv(32, 64)
self.dconv_down4 = double_conv(64, 128)
self.dconv_down5 = double_conv(128, 256)
self.avgpool = nn.AdaptiveAvgPool2d((1,1))
self.fc = nn.Linear(256, 2)
self.maxpool = nn.MaxPool2d(2)
def forward(self, x):
conv1 = self.dconv_down1(x)
x = self.maxpool(conv1)
conv2 = self.dconv_down2(x)
x = self.maxpool(conv2)
conv3 = self.dconv_down3(x)
x = self.maxpool(conv3)
conv4 = self.dconv_down4(x)
x = self.maxpool(conv4)
conv5 = self.dconv_down5(x)
x1 = self.maxpool(conv5)
avgpool = self.avgpool(x1)
avgpool = avgpool.view(avgpool.size(0), -1)
outC = self.fc(avgpool)
return conv5, conv4, conv3, conv2, conv1, outC
class Decoder(nn.Module):
def __init__(self, n_class = 1, nonlocal_mode='concatenation', attention_dsample = (2,2)):
super().__init__()
self.upsample = nn.Upsample(scale_factor=2, mode='bilinear', align_corners=True)
self.dconv_up4 = double_conv(256 + 128 + 2, 128)
self.dconv_up3 = double_conv(128 + 64, 64)
self.dconv_up2 = double_conv(64 + 32, 32)
self.dconv_up1 = double_conv(32 + 16, 16)
self.conv_last = nn.Conv2d(16, n_class, 1)
self.conv_last_saliency = nn.Conv2d(17, n_class, 1)
def forward(self, input, conv5, conv4, conv3, conv2, conv1, saliency):
bridge = torch.cat([input, saliency], dim = 1)
bridge = nn.functional.interpolate(bridge, scale_factor=0.125, mode='bilinear', align_corners=True)
x = self.upsample(conv5)
x = torch.cat([x, conv4, bridge], dim=1)
x = self.dconv_up4(x)
x = self.upsample(x)
x = torch.cat([x, conv3], dim=1)
x = self.dconv_up3(x)
x = self.upsample(x)
# pdb.set_trace()
x = torch.cat([x, conv2], dim=1)
x = self.dconv_up2(x)
x = self.upsample(x)
x = torch.cat([x, conv1], dim=1)
x = self.dconv_up1(x)
out = self.conv_last(x)
return out我们将模型拆分为单独的编码器和解码器模块,并将它们组合在 MultiMix 类中。对于编码器,我们每次使用 double_conv 块放大 2 倍。看前向函数,我们在每个卷积块之后保存特征图,用于跳过编码器和解码器之间的连接,我们使用最大池化层来解构图像。然后,我们使用平均池化层和密集层为多任务添加分类分支,以获得最终的分类输出 (outC)。我们返回所有特征图以及解码器使用的分类预测。
然后在解码器中,我们使用卷积层来减少特征图,并使用上采样层来重建图像。 forward 函数是所有魔法发生的地方。我们首先将显着性图与原始图像连接和堆叠。然后我们对输入进行下采样,以便它可以与跳过连接一起在第一个卷积块中连接。对于下一个卷积块,我们只需执行标准反卷积并跳过连接以获得最终输出(out)。
一旦我们建立了模型,我们就可以建立我们的训练循环。这是一段相当长且令人生畏的代码块,所以别担心,我们会分解它。
def calc_loss(outSeg, target, outSegUnlabeled, outC, labels, outWeak, outStrong, metrics, ssl_weight = 0.25, threshold = 0.7, kl_weight = 0.01, dice_weight = 5):
predSeg = torch.sigmoid(outSeg)
dice = dice_loss(predSeg, target)
lossClassifier = criterion(outC, labels)
probsWeak = torch.softmax(outWeak, dim=1)
max_probs, psuedoLabels = torch.max(probsWeak, dim=1)
mask = max_probs.ge(threshold).float()
lossUnLabeled = (F.cross_entropy(outStrong, psuedoLabels,
reduction='none') * mask).mean()
kl_class = kl_divergence_class(outC, outStrong)
kl_seg = kl_divergence_seg(outSeg, outSegUnlabeled)
# do KL only with segmentation for now
loss = lossClassifier + dice * dice_weight + (lossUnLabeled * ssl_weight) + (kl_seg * kl_weight)
metrics['lossClassifier'] += lossClassifier.data.cpu().numpy() * target.size(0)
metrics['dice'] += dice.data.cpu().numpy() * target.size(0)
metrics['loss'] += loss.data.cpu().numpy() * target.size(0)
return loss
def train_model(model, optimizer, scheduler, num_epochs=25):
best_loss = 1e10
accuracies = []
for epoch in range(num_epochs):
print('Epoch {}/{}'.format(epoch, num_epochs - 1))
print('-' * 10)
since = time.time()
# Each epoch has a training and validation phase
for phase in ['train', 'val']:
if phase == 'train':
model.train() # Set model to training mode
else:
# gc.collect()
# torch.cuda.empty_cache()
model.eval() # Set model to evaluate mode
metrics = defaultdict(float)
epoch_samples = 0
total_train = 0
correct_train = 0
trainloader = zip(cycle(dataloaders[phase]), cycle(dataloaders["unlabeled"]), cycle(dataloadersClassifier[phase]), dataloadersClassifier["weak"], dataloadersClassifier["strong"]) # added cycling
for i, (dataSeg, dataSegUnlabeled, data, dataWeak, dataStrong) in enumerate(trainloader):
gc.collect()
torch.cuda.empty_cache()
inputs, masks = dataSeg
inputs, masks = inputs.to(device=device, dtype=torch.float), masks.to(device=device, dtype=torch.float)
inputsUnlabeled, masksUnlabeled = dataSegUnlabeled
inputsUnlabeled, masksUnlabeled = inputsUnlabeled.to(device=device, dtype=torch.float), masksUnlabeled.to(device=device, dtype=torch.float)
inputsClass, labels = data
inputsClass, labels = inputsClass.to(device), labels.to(device)
inputsWeak, weakLabelUnused = dataWeak
inputsWeak, weakLabelUnused = inputsWeak.to(device), weakLabelUnused.to(device)
inputsStrong, strongLabelUnused = dataStrong
inputsStrong, strongLabelUnused = inputsStrong.to(device), strongLabelUnused.to(device)
inputsAll = torch.cat((inputs, inputsUnlabeled, inputsClass, inputsWeak, inputsStrong))
batch_size_seg = inputs.shape[0]
batch_size_seg_unlabeled = inputsUnlabeled.shape[0] + batch_size_seg
batch_size_class = inputsClass.shape[0] + batch_size_seg_unlabeled
batch_size_weak = inputsWeak.shape[0] + batch_size_class
batch_size_strong = inputsStrong.shape[0] + batch_size_weak
# zero the parameter gradients
optimizer.zero_grad()
# forward
with torch.set_grad_enabled(True):
# backward + optimize only if in training phase
if phase == 'train':
outSegAll, outClassAll = model(inputsAll, optimizer)
outSeg = outSegAll[:batch_size_seg]
outSegUnlabeled = outSegAll[batch_size_seg:batch_size_seg_unlabeled]
outC = outClassAll[batch_size_seg_unlabeled:batch_size_class]
outWeak = outClassAll[batch_size_class:batch_size_weak]
outStrong = outClassAll[batch_size_weak:batch_size_strong]
loss = calc_loss(outSeg, masks, outSegUnlabeled, outC, labels, outWeak, outStrong, metrics)
loss.backward()
optimizer.step()在我们讨论循环之前,请注意我们省略了很多方法和训练循环来简化它。
如果我们从第 52 行开始,我们首先组合所有训练数据集,包括监督分割训练集、未标记分割训练集、监督分类训练集、弱增强分类集和强增强分类集。后两者具有相同的精确图像,但只是在不同级别上进行了增强。下一组线只是简单地对数据进行基本的拼接和组合,以便所有数据通过模型统一发送。
一旦我们将所有输入传递到模型中,我们就会将它们全部传递给 calc_loss 函数。在 calc_loss 函数中,我们首先获取基本的监督分类和分割损失(dice 和 lossClassifier)。我们使用骰子损失进行分割,使用交叉熵进行分类。
对于半监督分类,我们首先通过 softmax 函数传递弱增强的图像预测以获取概率,然后使用 torch.max 函数获取标签。然后我们使用 .ge 函数只保留高于置信度阈值的预测,这是方法中讨论的一个重要因素。然后我们计算无监督分类损失(lossUnlabeled)。
最后,我们使用标记和未标记的分割预测 (kl_seg) 计算 KL 散度。一旦所有计算完成,我们将它们组合成一个单一的损失计算,方法是将所有损失乘以它们各自的权重(lambda、alpha、beta)。一旦将其传递回主训练循环,我们只需使用 loss.backward() 计算梯度,并使用 optimizer.step() 更新模型的参数。
代码审查部分到此结束。我们没有讨论增强和数据处理部分,因为它非常乏味。如果您有兴趣,请查看以下 repo 中的完整代码:https://github.com/ayaanzhaque/MultiMix[0]
Conclusion and Thoughts:
在这篇博文中,我们解释了 MultiMix,这是一种新颖的少监督、多任务学习模型,用于联合学习分类和分割任务。通过结合一致性增强和新的显着性桥模块以获得更好的可解释性,MultiMix 即使在有限标记数据和多源数据上进行训练时,也可以执行改进且一致的肺炎检测和肺分割。我们使用四个不同的胸部 X 射线数据集进行的广泛实验真正证明了 MultiMix 在域内和跨域评估中的任何一项任务的有效性。我们未来的工作将集中在进一步提高 MultiMix 的跨域性能,尤其是分类方面。我们目前正在准备一份完整的期刊提交,其中包含更多结果和工作扩展。
做这项工作对我来说真的很令人兴奋。作为一名高中生,我很高兴有机会与合格且经验丰富的研究人员一起进行前沿研究。整个过程对我来说非常具有挑战性,因为我对如何撰写正式的研究论文和进行适当且令人信服的实验几乎没有经验。即使是编码和构建实际的添加也需要相当多的时间。我还在熟悉 PyTorch,但是从事这个项目非常有趣和令人兴奋,我学到了很多关于深度学习和医学成像的知识。我很高兴这次会议有机会与其他研究人员会面并了解该领域的新研究,我相信我们未来的工作也将取得与该项目相同的成功。感谢您的阅读。
如果您发现此博客或论文的任何部分有趣,请考虑引用:
@article{melba:2021:011:haque,
title = "Generalized Multi-Task Learning from Substantially Unlabeled Multi-Source Medical Image Data",
authors = "Haque, Ayaan and Imran, Abdullah-Al-Zubaer and Wang, Adam and Terzopoulos, Demetri",
journal = "Machine Learning for Biomedical Imaging",
volume = "1",
issue = "October 2021 issue",
year = "2021"
}文章出处登录后可见!